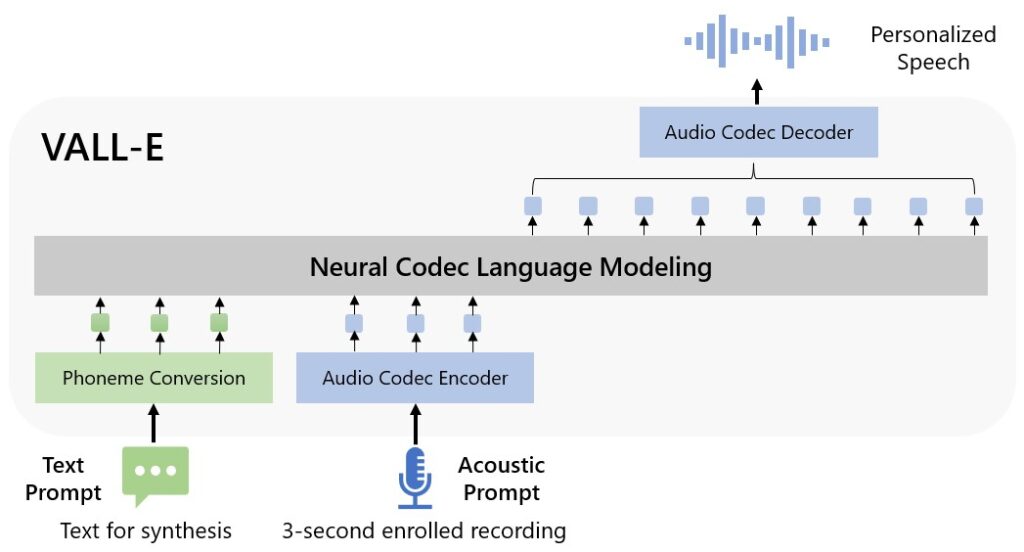
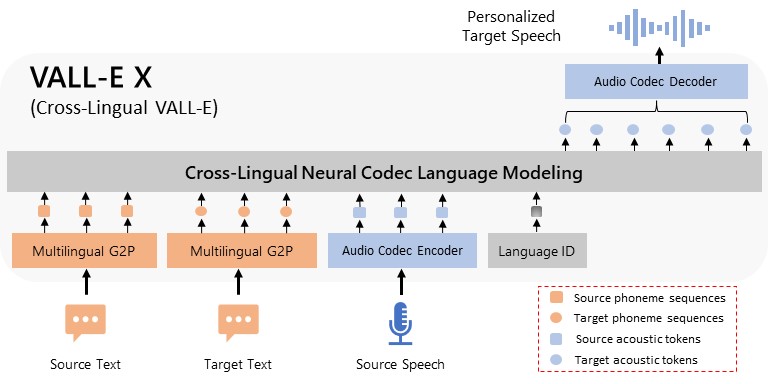
VALL-E简介
VALL-E是微软研究院在2023年初推出的一种神经编解码语言模型,用于实现零样本文本转语音合成。它具有以下主要特点:
- 仅需3秒音频样本即可合成高质量的个性化语音
- 能够保持说话人的情感和音频环境
- 支持多语言场景
- 在语音自然度和说话人相似度上显著超越现有系统
VALL-E的核心思想是将文本转语音任务视为条件语言建模任务,而不是传统的连续信号回归。这种方法使模型具备了强大的上下文学习能力。
学习资源
官方资料
-
VALL-E项目主页 微软官方的VALL-E项目介绍,包含模型概述、音频样例等。
-
VALL-E论文
详细介绍VALL-E的技术原理和实验结果。 -
VALL-E演示页面 提供了大量音频样例,展示VALL-E的合成效果。
开源实现
-
EnCodec VALL-E使用的神经音频编解码器,由Meta AI开源。
-
非官方PyTorch实现 基于EnCodec的VALL-E非官方PyTorch实现,包含训练和推理代码。
-
Google Colab示例 可在线运行的VALL-E简单示例。
相关博客文章
-
VALL-E: 仅需3秒音频实现高质量TTS 详细解读VALL-E的技术原理。
-
VALL-E: 革命性的TTS模型 分析VALL-E的创新点和潜在影响。
实践指南
如果您想尝试复现VALL-E,可以按以下步骤进行:
-
安装依赖:
pip install git+https://github.com/enhuiz/vall-e -
准备数据: 将音频文件(.wav)和对应的文本(.normalized.txt)放入同一文件夹。
-
数据预处理:
python -m vall_e.emb.qnt data/your_data python -m vall_e.emb.g2p data/your_data -
配置训练参数: 创建
config/your_data/ar.yml和config/your_data/nar.yml配置文件。 -
训练模型:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml -
导出模型:
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml -
推理合成:
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
需要注意的是,由于VALL-E需要大规模数据训练,个人复现可能难以达到论文中的效果。建议关注官方后续是否会开源预训练模型。
总结
VALL-E作为一种创新的零样本TTS方法,展现了神经编解码语言模型在语音合成领域的巨大潜力。虽然目前官方尚未开源完整模型,但社区已有多个非官方实现可供学习参考。相信随着相关研究的深入,VALL-E及其衍生技术将为语音合成领域带来更多突破。