
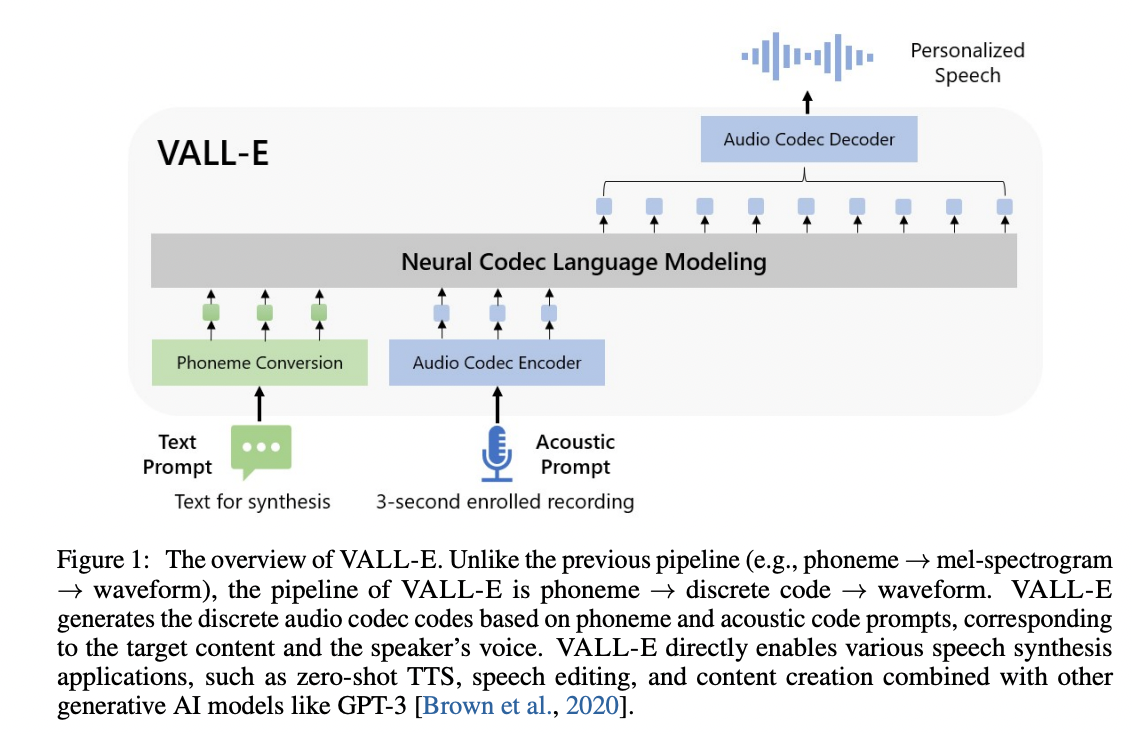
VALL-E
一个基于EnCodec分词器的非官方PyTorch实现的VALL-E。

快速开始
一个简单的Google Colab示例:
请注意,该示例仅针对
data/test中的单个语句过拟合,不可实际使用。 预训练模型尚未提供。
要求
由于训练器基于DeepSpeed,因此你需要拥有DeepSpeed已经开发和测试过的GPU,以及预先安装CUDA或ROCm编译器来安装此包。
安装
pip install git+https://github.com/enhuiz/vall-e
或者你可以克隆:
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
请注意,该代码仅在Python 3.10.7下测试。
训练
-
将你的数据放入一个文件夹,例如
data/your_data。音频文件应以.wav为后缀,文本文件应以.normalized.txt为后缀。 -
量化数据:
python -m vall_e.emb.qnt data/your_data
- 根据文本生成音素:
python -m vall_e.emb.g2p data/your_data
-
通过创建
config/your_data/ar.yml和config/your_data/nar.yml自定义你的配置。有关详细信息,请参阅config/test和vall_e/config.py中的示例配置。你可以选择不同的模型预设,查看vall_e/vall_e/__init__.py。 -
使用以下脚本训练AR或NAR模型:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
你可以随时在CLI中键入quit退出训练,最新的检查点将自动保存。
导出
两个训练好的模型都需要导出到某个路径。导出任意一个,运行:
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
这将导出最新的检查点。
合成
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
待办事项
- 第一个量化器的AR模型
- 从tokens中解码音频
- 剩下量化器的NAR模型
- 两个模型的训练器
- 为NAR模型实现AdaLN
- NAR训练的样本级量化水平采样
- 在LibriTTS上提供预训练检查点和演示
- 合成CLI
注意
- EnCodec根据CC-BY-NC 4.0授权。如果你使用该代码生成音频量化或进行解码,重要的是要遵守其许可证条款。
引用
@article{wang2023neural,
title={Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author={Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others},
journal={arXiv preprint arXiv:2301.02111},
year={2023}
}
@article{defossez2022highfi,
title={High Fidelity Neural Audio Compression},
author={Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
journal={arXiv preprint arXiv:2210.13438},
year={2022}
}









