Vec4IR: 面向信息检索的词嵌入框架
Vec4IR是一个专门为信息检索任务设计的词嵌入应用框架。它的目标是将词嵌入技术与实际的信息检索过程结合起来,为研究人员和数据科学家提供一个灵活而强大的工具。
框架概述
Vec4IR的核心理念是模拟实际的信息检索场景。它包含了从查询扩展、文档匹配到相似度评分等完整的检索流程。框架的设计着重于可扩展性,使得添加新的检索模型变得简单直接。主要功能包括:
- 模拟实际的信息检索场景
- 原生支持词嵌入,与gensim库无缝集成
- 内置评估功能
- API设计借鉴scikit-learn,易于使用
- 可扩展性强,支持添加新的检索模型
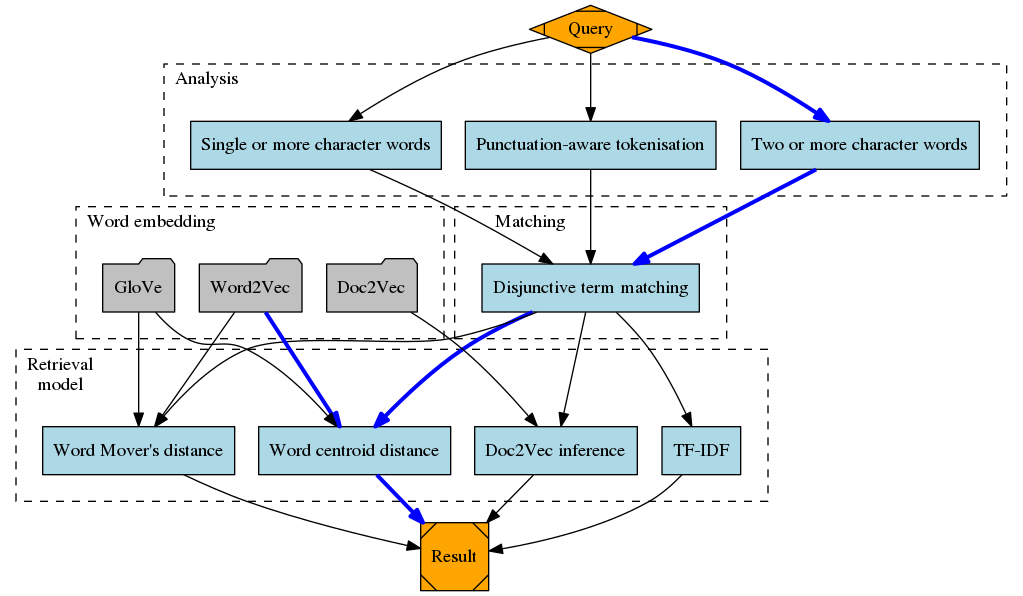
核心概念
Vec4IR涉及了信息检索的几个关键概念:
-
匹配(Matching):初步筛选出包含查询词的文档。
-
相似度评分(Similarity Scoring):为匹配的文档分配相关性得分。
-
词嵌入(Word Embedding):将词语映射到低维向量空间,捕捉语义信息。
-
词中心相似度(Word Centroid Similarity):利用文档词向量的质心来表示文档,计算查询与文档的相似度。
主要功能
Vec4IR提供了多种基于词嵌入的检索模型:
- 词中心相似度:计算查询和文档词向量质心的余弦相似度
- IDF加权词中心相似度:在计算质心时加入IDF权重
- Word Mover's Distance:计算查询词到文档词的最小移动距离
- Doc2Vec推断:利用Doc2Vec模型推断文档向量,计算相似度
框架还内置了评估功能,可以计算MAP、MRR、NDCG等常用信息检索评价指标。
使用方法
Vec4IR的使用非常简单直观。以下是一个基本示例:
from gensim.models import Word2Vec
from vec4ir import Matching, WordCentroidDistance, Retrieval
# 创建匹配器
match_op = Matching()
# 加载词嵌入模型
model = Word2Vec(documents['full-text'], min_count=1)
# 创建检索模型
wcd = WordCentroidDistance(model.wv)
# 组合成完整的检索系统
RM = Retrieval(wcd, matching=match_op).fit(documents['full-text'])
# 进行查询
results = RM.query("example query")
扩展性
Vec4IR的一大特色是其良好的扩展性。用户可以轻松实现自定义的检索模型,只需继承RetriEvalMixin类并实现fit()和query()方法即可。
此外,Vec4IR还支持通过运算符重载来组合多个检索模型,实现更复杂的检索策略。
总结
Vec4IR为研究人员和数据科学家提供了一个强大而灵活的工具,可以方便地将词嵌入技术应用于信息检索任务。无论是评估新的检索模型,还是为特定数据集选择最佳模型,Vec4IR都是一个理想的选择。它不仅模拟了实际的信息检索场景,还提供了丰富的功能和良好的扩展性,为信息检索研究和应用提供了有力支持。









