
 Github
Github 论文
论文Vec4IR
用于信息检索的词嵌入。


快速入门
访问测试文件以快速了解该框架的基本用法。
关于vec4ir中可用方法的比较,请参阅我们的论文Word Embeddings for Practical Information Retrieval(作者副本)。 如果您在研究中使用了这段代码,请考虑引用该论文:
@inproceedings{mci/Galke2017,
author = {Galke, Lukas AND Saleh, Ahmed AND Scherp, Ansgar},
title = {Word Embeddings for Practical Information Retrieval},
booktitle = {INFORMATIK 2017},
year = {2017},
editor = {Eibl, Maximilian AND Gaedke, Martin} ,
pages = { 2155-2167 } ,
doi = { 10.18420/in2017_215 },
publisher = {Gesellschaft für Informatik, Bonn},
address = {}
}
欢迎任何扩展框架的建议!如有功能需求,请随时提出问题。
用户指南
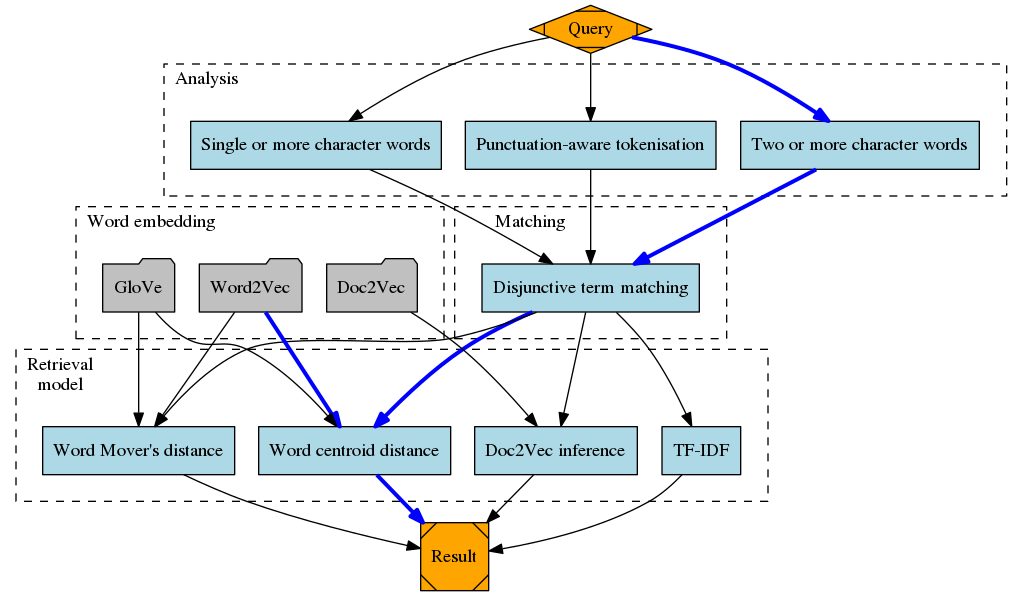
理念
信息检索框架vec4ir的目标是模拟实际的信息检索场景。为了鼓励该领域的研究,重点放在可扩展性上。添加新的检索模型进行评估应该尽可能简单。目标受众是评估自己检索模型的研究人员和想要评估哪种检索模型最适合其数据的好奇数据科学家。
术语
以下我们回顾与该框架相关的最重要定义。
信息检索(IR)
信息检索任务可以定义如下:
给定文档集合D和查询q,以排序方式返回{d ∈ D ∣ d与q相关}。
实际的信息检索系统通常至少包含两个组件:匹配和相似度评分。 还可以考虑其他几个组件,如查询扩展、伪相关反馈、查询解析和分析过程本身。
匹配
匹配操作指的是文档的初始过滤过程。例如,匹配操作的输出包含所有至少包含一个查询词的文档。匹配操作的其他变体也可能允许模糊匹配(在莱文斯坦距离的某个阈值内)或强制精确匹配短语。
相似度评分
评分步骤是指分配分数的过程。分数反映了特定文档与查询的相关性。它们用于创建匹配文档的排序。当考虑距离分数时,排序是升序的;在相似度分数的情况下,排序是降序的。
词嵌入和Word2Vec
词嵌入是词汇表中每个词的分布式(密集)向量表示。它能够捕捉输入文本的语义和语法特性。有趣的是,词向量的算术运算也是有意义的:例如,国王 - 王后 = 男人 - 女人。从原始文本学习词嵌入的两种最流行方法是:
- Mikolov等人(2013)的Skip-Gram负采样(Word2Vec)
- Pennington、Socher和Manning(2014)的全局词向量(GloVe) Skip-gram负采样(或Word2Vec)是一种基于浅层神经网络的算法,旨在学习词嵌入。它具有高效性,因为它避免了密集矩阵乘法,并且不需要完整的词共现矩阵。给定某个目标词w_t,中间目标是训练神经网络预测w_t的c邻域内的词: w_(t-c),...,w_(t-1),w_(t+1),...,w_(t+c)。 首先,将词直接与其对应的向量关联,作为(多项)逻辑回归的输入,以预测c邻域内的词。然后,调整逻辑回归的权重以及向量本身(通过反向传播)。Word2Vec算法采用负采样:引入额外的k个不出现在c邻域内的噪声词作为可能的输出,其期望输出已知为"假"。因此,模型不会降低所有其他词汇的权重,而只降低那些采样的k个噪声词的权重。当这些噪声词出现在与w_t相似的上下文中时,模型在训练过程中会变得越来越细致。与Word2Vec不同,GloVe(Pennington, Socher和Manning 2014)算法计算给定语料库的整个词共现矩阵。为了获得词向量,对词共现矩阵进行因子分解。训练目标是使每两个词向量的欧几里得点积与它们的词共现对数概率匹配。
词向量质心相似度(WCS)
在信息检索中使用词嵌入的一种直观方法是词向量质心相似度(WCS)。每个文档的表示是其各自词向量的质心。由于词向量携带了词的语义信息,可以假设文档中词向量的质心在某种程度上编码了其含义。 在查询时,计算查询词向量的质心。与(匹配的)文档质心的余弦相似度被用作相关性的度量。当首先根据逆文档频率(即语料库中频繁出现的词被折扣)对查询和文档的初始词频进行重新加权时,该技术被称为IDF重加权词向量质心相似度(IWCS)。
特性
这个信息检索框架的主要特性包括:
- 模拟实际IR设置
- 结合
gensim(Řehuřek和Sojka 2010)的原生词嵌入支持 - 内置评估
- API设计灵感来自
sklearn(Buitinck等人2013) - 可通过新的检索模型进行扩展
依赖项
除了python3本身,vec4ir包依赖于以下Python包。
- numpy
- scipy
- gensim
- pandas
- networkx
- rdflib
- nltk
- sklearn
- pyyaml
安装
由于vec4ir被打包为Python包,可以通过pip安装:
我们提供了一个辅助脚本来设置新的虚拟环境并安装所有依赖项。可以通过bash requirements.sh调用。
要在以后使用已安装的包,你必须通过source venv/bin/activate激活创建的虚拟环境。
如果不需要新的虚拟环境,可以手动安装vec4ir:
pip install -e .
如果依赖项安装出现问题,请尝试手动安装:我们还建议预先安装numpy和scipy(手动或作为二进制系统包)。
pip install -r requirements.txt
WordMoversDistance和pyemd
要计算Word Mover's距离,需要pyemd包。
可以通过pip install pyemd安装。但是,安装pyemd可能需要Python3开发系统包(如python3-dev或python3-devel)。
只有在需要使用Word Mover's距离时才需要执行此步骤。
评估脚本
该包包含一个原生命令行脚本vec4ir-evaluate,用于评估信息检索管道。查询扩展、匹配和评分的管道应用于一组查询,并计算平均精确度均值(MAP)、平均倒数排名(MRR)、归一化折扣累积增益(NDCG)、精确度和召回率等指标。因此,该脚本可以原样用于评估你的数据集,或作为框架使用的参考实现。评估脚本的行为和生成的信息检索管道可以通过以下命令行参数控制:
元选项
作为影响其他选项的元选项,我们允许指定配置文件。
-c, --config配置文件的路径,其中指定了数据集和嵌入模型的文件路径。默认值为config.yml。
一般选项
-d, --dataset要操作的数据集。(必需)-e, --embedding要使用的词嵌入模型。(必需)-r, --retrieval-model用于相似度评分的检索模型。可选择tfidf(默认)、wcd、wmd或d2v。-q, --query-expansion应用于查询的扩展技术。可选择wcd、eqe1或eqe2。
参数 --dataset 和 --embedding 需要在 --config 指定的配置文件中存在相应的键。嵌入的键应位于配置文件的 embeddings 下,而数据集的键应位于 data 下。以下是一个最小示例结构:
embeddings:
word2vec: # --embedding 的可能值
path: "/path/to/GoogleNews-vectors-negative300.bin.gz"
data:
short-ntcir2: # --dataset 的可能值
type: "ntcir"
root_path: "path/to/data/NTCIR2/"
field: "title"
topic: "title"
rels: 2
各键下的选项指定负责的构造函数(type)及其参数(root_path、field 等)。有关原生支持的数据集格式的更多详细信息,请参阅开发者指南。检索模型(--retrieval-model)的替代方案将在下文中详细描述。
嵌入选项
-n, --normalize归一化嵌入模型的词向量。-a, --all-but-the-top应用 Mu、Bhat 和 Viswanath (2017) 提出的 All-but-the-top 嵌入后处理。-t, --train用于训练词汇表外单词的轮次数。
在 --train 0 的特殊情况下,脚本的行为与省略此参数不等效。在从输入文档构建词汇表后,词向量会与嵌入的词向量取交集。更具体地说,缺失的词汇表单词会被初始化为接近零的随机向量。相反,如果省略 --train 参数,词汇表外的单词将被忽略。
检索选项
-I, --no-idf不使用 IDF 重新加权的词频进行词向量聚合。-w, --wmd为wmd检索模型考虑的额外文档比例。
默认情况下,如果提供了 -r wcd,vec4ir-evaluate 使用 IDF 重新加权的词质心相似度。如果不需要 IDF 重新加权,则需要提供 --no-idf 参数。当选择词移距离(-r wmd)作为检索模型时,--wmd 参数指的是要考虑的额外文档比例。例如,考虑 --wmd 0.1 和特定查询的 120 个匹配文档。当需要检索 20 个文档时,词质心相似度会用于检索前 20 + 0.1 ⋅ (120 − 20) = 30 个文档。然后,这 30 个最相关(相对于词质心相似度)的文档将根据词移距离重新排序。--wmd 值为零对应于仅根据词移距离重新排序前 k 个文档,而最高可能值 1.0 对应于计算完整的词移距离,而不考虑 WCS。
输出选项
输出选项控制评估脚本的在线和持久输出。特殊选项 --stats 可用于计算词汇表外标记的比率,打印 50 个最频繁的词汇表外标记,然后退出。
-o, --output写入输出的文件路径。-v, --verbose详细程度级别。-s, --stats计算词汇表外统计信息并退出。
评估选项
以下参数影响评估过程:
-k要检索的文档数量(默认为 20)。-Q, --filter-queries删除包含词汇表外单词的查询。-R, --replacement处理黄金标准中缺失相关性信息的方法。选择drop忽略它们(默认)或zero将它们视为不相关。
在大多数情况下,不过滤查询并将缺失值替换为零(表示不相关)的默认设置是适当的。
分析选项
可以通过以下参数自定义将字符串分割为标记的分析过程:
-M, --no-matching不进行匹配操作。-T, --tokenizer用于匹配操作的分词器。可选择sklearn、sword或nltk。-S, --dont-stop不移除英语停用词。-C, --cased进行大小写敏感的分析。
请注意,分析过程也直接影响匹配操作。默认设置是进行匹配操作,使用 sklearn 分词器(F. Pedregosa 等人,2011)(标记由至少两个连续的单词字符组成),移除英语停用词,并将所有字符转换为小写。sword 分词器还将单字符单词视为标记。nltk 分词器保留所有标点符号作为标记(Bird,2006)。
基本框架使用
我们提供了一个最小示例,包括匹配操作和 TF-IDF 检索模型。假设我们有两个文档 fox valley 和 dog nest,以及两个查询 fox 和 dog。首先,我们创建一个 Matching 类的实例,其可选参数直接传递给 sklearn 的 CountVectorizer。
>>> match_op = Matching()
在其默认形式下,匹配是一种非模糊的布尔"或"匹配。可以通过match_op.fit(documents)对一组文档进行拟合后,使用Matching实例的match_op.predict(query_string)方法来返回匹配文档的索引。然而,应用匹配操作的首选方式是在Retrieval实例内部。Retrieval实例除了可选的Matching实例(和可选的查询扩展实例)外,还需要一个检索模型作为必需参数。现在,我们创建一个Tfidf类的实例并将其传递给Retrieval构造函数。
>>> tfidf = Tfidf()
>>> retrieval = Retrieval(retrieval_model=tfidf, matching=match_op)
>>> retrieval.fit(titles)
>>> retrieval.query("fox")
[0]
>>> retrieval.query("dog")
[1]
在索引时,Retrieval实例会在提供的查询扩展、匹配和检索模型代理上调用fit方法。在查询时,Retrieval实例会咨询matching参数的predict方法以获取一组匹配索引。这些匹配索引作为indices关键字参数传递给检索模型的query方法。然后,检索模型的结果会被转换回相应的文档标识符。
使用词嵌入
几个提供的检索模型使用了词嵌入。然而,这些检索模型并不自行学习词嵌入,而是将gensim的Word2Vec对象作为参数。
from gensim.models import Word2Vec
model = Word2Vec(documents['full-text'], min_count=1)
wcd = WordCentroidDistance(model.wv)
RM = Retrieval(wcd, matching=match_op).fit(documents['full-text'])
请注意,你只需要使用Word2Vec模型的词向量.wv。
本地提供了几种基于嵌入的检索模型:
-
词中心相似度
文档词向量中心与查询词向量中心之间的余弦相似度(WordCentroidDistance(idf=False))。 -
IDF重新加权的词中心相似度
在通过逆文档频率重新加权术语后,文档中心与查询中心之间的余弦相似度(WordCentroidDistance(idf=True))。 -
词移距离
最小化从查询词到文档词的移动成本。可选的complete参数(介于零和一之间)允许控制考虑的文档数量。设置complete=0会根据词移距离重新排序词中心相似度返回的文档,而设置complete=1.0会计算所有匹配文档的词移距离。 -
Doc2Vec推断
Doc2VecInference类需要一个gensim的Doc2Vec实例作为基础模型,而不是Word2Vec对象。该模型用于推断文档和查询的文档向量。匹配的文档根据查询和文档的推断向量之间的余弦相似度进行排序。参数alpha、min_alpha和epochs控制Doc2Vec实例的推断步骤。
所有这些提供的基于嵌入的检索模型都设计用于Retrieval包装器内部使用。
评估模型
要评估你的检索模型RM,只需调用其evaluate(X, Y)方法,其中X是(query_id,query_string)对的列表。金标准Y是一个两级数据结构。第一级对应于query_id,第二级对应于document_id。因此,Y[query_id][document_id]应该返回特定查询-文档对的相关性数字。Y的确切类型是灵活的,它可以是字典列表、二维numpy数组或具有(层次)多索引的pandas.DataFrame。
scores = RM.evaluate(X, Y)
evaluate(X, Y, k=None)方法返回每个查询计算的各种指标的字典。之后可以通过字典推导手动将分数减少到它们的平均值:
import numpy as np
mean_scores = {k : np.mean(v) for k,v in scores.items()}
结果分数字典的指标和键包括:
-
MAP
平均精确度均值(@k) -
precision
精确度(@k) -
recall
召回率(@k) -
f1_score
精确度和召回率的调和平均 -
ndcg
归一化折损累积增益(即使给定k,也会根据金标准产生合理的分数) -
MRR
平均倒数排名(@k)
其中k是要检索的文档数量。
扩展新模型
为了创建一个新的检索模型,必须实现一个至少包含两个方法的类:fit(X)和query(query, k=None, indices=None)。接下来,我们将演示一个虚拟检索模型的实现:GoldenRetriever模型,它返回k个匹配文档的随机样本。
import random as RNG
class GoldenRetriever(RetriEvalMixin):
def __init__(self, seed='bone'):
# 配置
RNG.seed(seed)
def fit(self, documents):
# 跟踪文档
self._fit_X = np.asarray(documents)
def query(self, query, k=None, indices=None):
# 预选的匹配文档
if indices is not None:
docs = self._fit_X[indices]
else:
docs = self._fit_X
# 现在我们可以对docs做更多处理,或者...
ret = RNG.sample(range(docs.shape[0]), k)
# 注意,我们的结果假定是
# 相对于匹配的索引
# 而不是它们的子集
return ret
新开发的类包含以下三个必需的方法:
-
构造函数 所有配置都在构造函数中完成,使模型准备好拟合文档。构造函数中不执行任何昂贵的计算。
-
fit(self, documents)fit方法在索引时被调用,检索模型了解文档并保存其内部文档表示。 -
query(self, query, k=None, indices=None)query方法在查询时被调用。除查询字符串本身外,它预期允许两个关键字参数:k表示所需文档数,indices提供匹配查询的文档索引。
模型对文档的自身视图的缩减(docs = self._fit_X[indices])很重要,因为返回的索引预期相对于这种缩减(下一节有更多细节)。这些相对索引提供了一个关键优势。通常,文档标识符不是简单的索引而是字符串值。使用相对(于匹配)索引允许我们的检索模型忽略文档标识符可能是字符串值或其他不匹配文档数组X位置的索引这一事实。可能的外围Retrieval类将为您跟踪文档标识符,并将查询结果ret转换到标识符空间。
从RetriEvalMixin继承提供了上面描述的evaluation方法,该方法内部调用新检索模型的query方法。
匹配、评分和查询扩展
我们提供了一个Retrieval类,实现图中所需的检索过程。Retrieval类由最多三个组件组成。它结合了检索模型(上面提到)作为必需对象,以及两个可选对象:匹配操作和查询扩展对象。在调用fit(X)时,Retrieval类将文档X委托给所有普遍的组件,即在匹配对象、查询扩展对象和检索模型对象上调用fit(X)。查询扩展类预期提供两种方法。
-
fit(X)此方法用原始文档集X调用 -
transform(q)此方法用查询字符串q调用,应返回扩展的查询字符串。
我们在开发者指南中提供了有关实现完整信息检索管道的更多详细信息。
组合多个字段和模型
高度实验性,一些技术尚不支持
vec4ir包还提供了一个实验性的运算符重载API,用于组合多个检索模型。
RM_title = WordCentroidDistance()
RM_title.fit(documents['title'])
RM_content = Tfidf()
RM_content.fit(documents['full-text'])
RM = RM_title ** 2 + RM_content # 求和得分,标题字段权重加倍
R = Retrieval(retrieval_model=RM, labels=documents['id'])
在组合检索模型RM上调用query方法时,标题模型和内容模型都会被咨询,它们各自的分数根据运算符合并。为加法、乘法以及幂运算符**提供了运算符重载,后者有效地加权检索模型返回的所有分数。
对于这些Combined检索模型,被咨询的操作数检索模型预期在其结果集中返回(doc_id, score)对。然而,在这种情况下结果集不必排序。因此,操作数检索模型的查询方法以sort=False调用。尽管如此,检索实例R仍会以sort=True调用最外层的组合检索模型,以便最终结果可以排序。
参考文献
Bird, Steven. 2006. "NLTK: The Natural Language Toolkit." In ACL 2006, 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, Sydney, Australia, 17-21 July 2006, edited by Nicoletta Calzolari, Claire Cardie, and Pierre Isabelle. The Association for Computer Linguistics. http://aclweb.org/anthology/P06-4018.
Buitinck, Lars, Gilles Louppe, Mathieu Blondel, Fabian Pedregosa, Andreas Mueller, Olivier Grisel, Vlad Niculae, et al. 2013. "API Design for Machine Learning Software: Experiences from the Scikit-Learn Project." In ECML Pkdd Workshop: Languages for Data Mining and Machine Learning, 108–22.
Mikolov, Tomas, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013. "Distributed Representations of Words and Phrases and Their Compositionality." In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a Meeting Held December 5-8, 2013, Lake Tahoe, Nevada, United States., edited by Christopher J. C. Burges, Léon Bottou, Zoubin Ghahramani, and Kilian Q. Weinberger, 3111–9. http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.
Mu, Jiaqi, Suma Bhat, and Pramod Viswanath. 2017. "All-but-the-Top: Simple and Effective Postprocessing for Word Representations." CoRR abs/1702.01417. http://arxiv.org/abs/1702.01417.
Pedregosa, F., G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, et al. 2011. "Scikit-Learn: Machine Learning in Python." Journal of Machine Learning Research 12: 2825–30. Pennington, Jeffrey、Richard Socher和Christopher D. Manning。2014年。"Glove:词表示的全局向量"。发表于《2014年自然语言处理实证方法会议论文集,EMNLP 2014,2014年10月25-29日,卡塔尔多哈,ACL特别兴趣小组Sigdat会议》,由Alessandro Moschitti、Bo Pang和Walter Daelemans编辑,1532-43页。ACL。http://aclweb.org/anthology/D/D14/D14-1162.pdf。
Řehuřek, Radim和Petr Sojka。2010年。"大规模语料库主题建模的软件框架"。发表于《LREC 2010自然语言处理框架新挑战研讨会论文集》,45-50页。马耳他瓦莱塔:ELRA。











