
VectorDB简介
VectorDB是一个简单、轻量级、完全本地化的端到端解决方案,用于基于嵌入的文本检索。它具有低延迟和小内存占用的特点,被用于为Kagi搜索提供AI功能支持。
VectorDB的主要特性包括:
- 简单轻量:API简洁易用,安装方便
- 本地化:所有数据处理包括嵌入和向量搜索都在本地完成
- 高性能:针对检索速度进行了优化
- 灵活性:支持多种嵌入模型和分块策略
安装与使用
可以通过pip安装VectorDB:
pip install vectordb
基本使用示例:
from vectordb import Memory
memory = Memory()
# 保存文本内容和元数据
memory.save(
["apples are green", "oranges are orange"],
[{"url": "https://apples.com"}, {"url": "https://oranges.com"}]
)
# 搜索相关结果
results = memory.search("green", top_n=1)
print(results)
这将返回最相关的文本块、元数据和向量距离。
主要功能
VectorDB提供以下主要功能:
- 文本保存与检索
- 灵活的分块策略
- 多种嵌入模型选择
- 元数据关联
- 批量查询
- 持久化存储
详细的API参数和用法可以参考GitHub文档。
性能分析
VectorDB在嵌入和向量搜索性能上都做了优化:
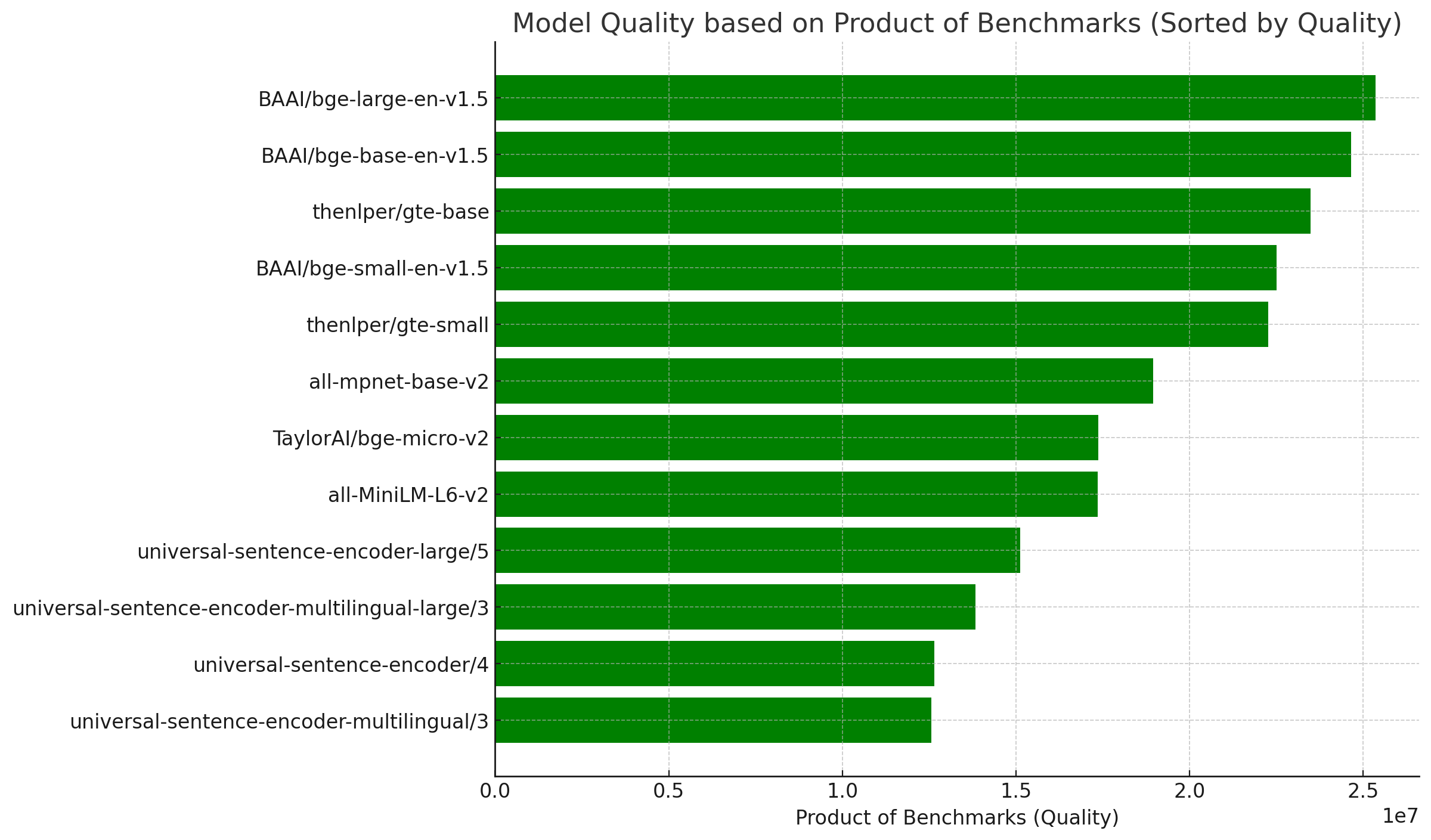
- 嵌入性能:提供多种嵌入模型选择,可以根据需求平衡速度和质量。
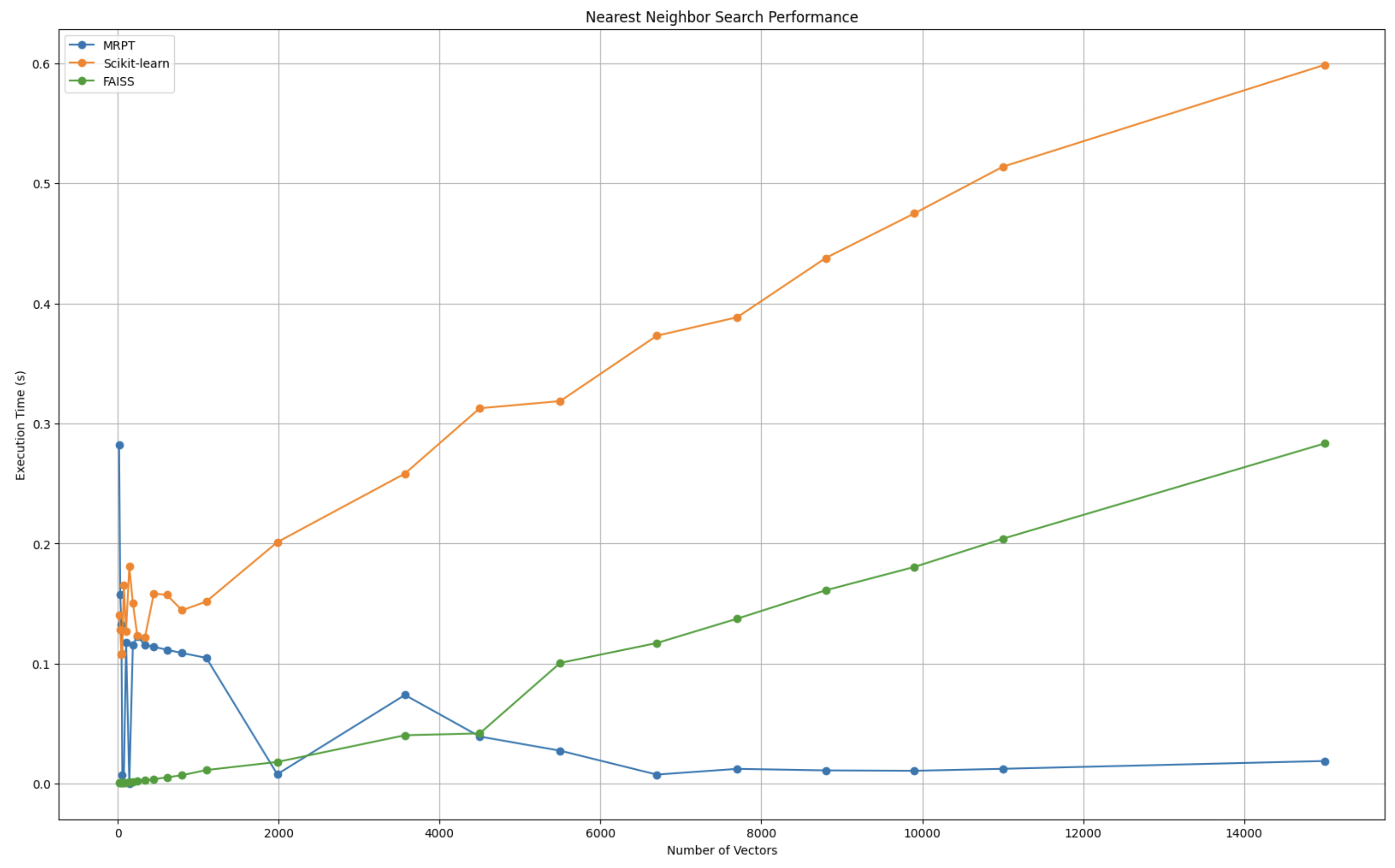
- 搜索性能:针对不同数据规模自动选择合适的搜索算法。
总结
VectorDB作为一个轻量级的向量数据库解决方案,为开发者提供了简单易用的API来实现基于嵌入的文本检索功能。它的高性能和灵活性使其成为构建AI应用的理想选择。无论是个人项目还是生产环境,VectorDB都能满足多样化的需求。
欢迎访问GitHub仓库了解更多详情,并加入Discord社区讨论交流使用心得。VectorDB采用MIT许可证,可以放心使用在各种项目中。











