
VectorDB简介
VectorDB是一个简单、轻量级、完全本地化的端到端解决方案,专门用于基于嵌入的文本检索。它由Kagi公司开发,旨在为开发者提供一个易用而高效的向量数据库工具。
得益于其低延迟和小内存占用的特点,VectorDB被用于为Kagi搜索引擎提供AI功能支持。这个强大的工具可以帮助开发者轻松实现文本存储、检索和相似度搜索等功能,为各种AI应用提供基础支持。
主要特性
VectorDB具有以下几个突出的特性:
-
简单易用: VectorDB提供了简洁的API,使得开发者可以快速上手并集成到自己的项目中。
-
轻量级: 该库设计轻量,不会给系统带来太多额外负担。
-
本地化: 所有数据处理都在本地完成,包括嵌入和向量搜索,无需依赖外部服务。
-
高性能: VectorDB针对性能进行了优化,可以快速处理大量文本数据。
-
灵活性: 支持多种嵌入模型和分块策略,可以根据需求进行调整。
安装和使用
要安装VectorDB,只需使用pip命令:
pip install vectordb
以下是一个简单的使用示例:
from vectordb import Memory
# 创建Memory实例
memory = Memory()
# 保存文本内容
memory.save(
["apples are green", "oranges are orange"], # 文本内容
[{"url": "https://apples.com"}, {"url": "https://oranges.com"}] # 元数据
)
# 搜索相关内容
query = "green"
results = memory.search(query, top_n = 1)
print(results)
这个例子展示了如何保存文本内容及其相关元数据,并进行简单的搜索。VectorDB会自动处理文本分块、嵌入和向量搜索等复杂过程,让开发者可以专注于应用逻辑的实现。
高级配置选项
VectorDB提供了多种配置选项,以满足不同场景的需求:
-
内存持久化: 可以指定
memory_file参数来持久化存储数据。 -
分块策略: 支持滑动窗口和段落两种分块模式,可通过
chunking_strategy参数配置。 -
嵌入模型选择: 提供多种预训练嵌入模型,从快速到高质量,还支持多语言模型。
-
搜索参数调整: 可以通过
top_n、unique等参数来精细控制搜索结果。
这些灵活的配置选项使得VectorDB可以适应各种不同的应用场景和性能需求。
性能分析
VectorDB团队对各种嵌入模型进行了详细的性能分析,包括延迟和质量评估。以下是部分模型的性能对比:
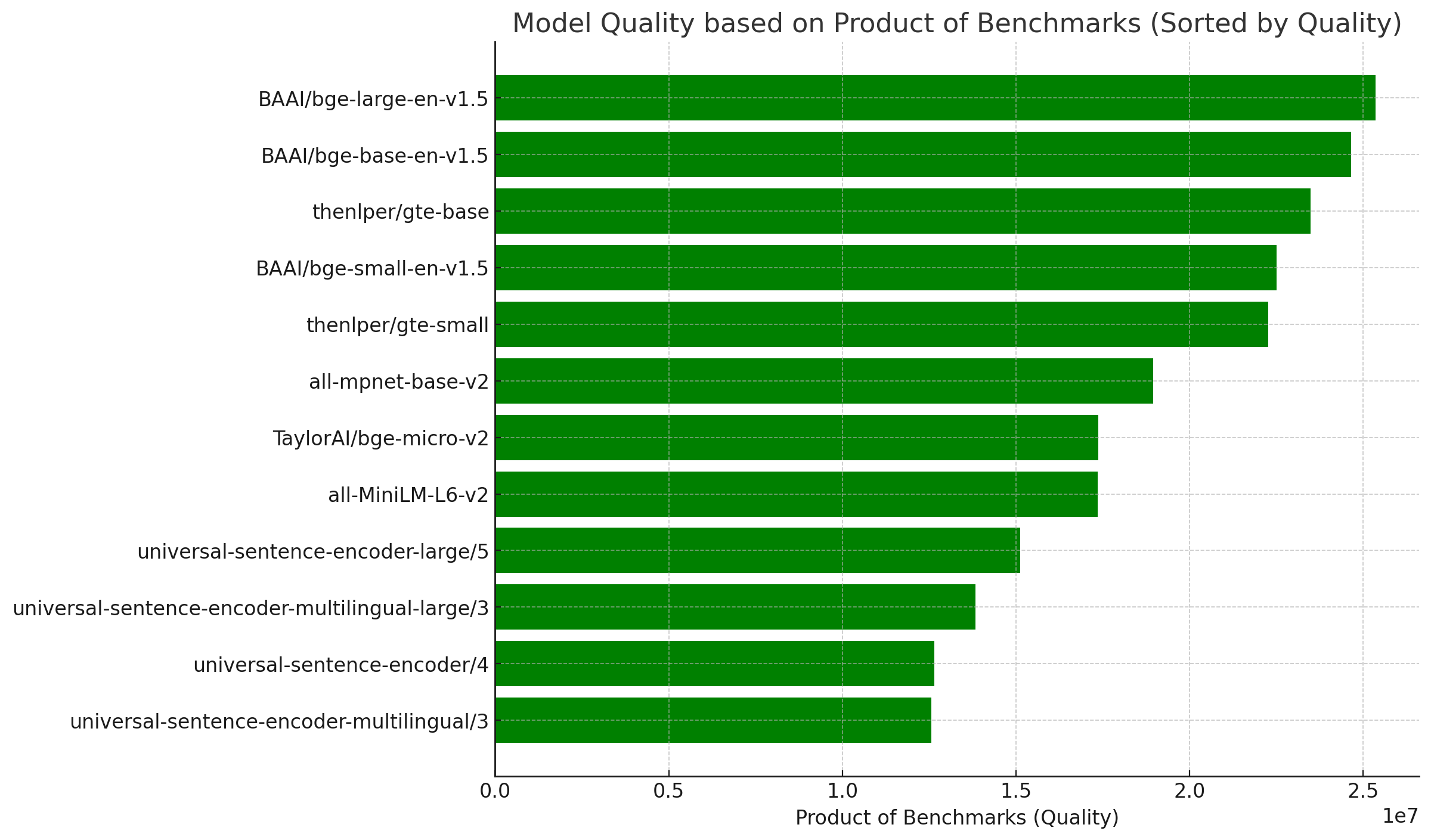
从图中可以看出,不同模型在性能和质量之间有着不同的权衡。开发者可以根据自己的需求选择合适的模型。
此外,VectorDB还针对向量搜索进行了优化。对于小规模数据(<4000个块),它使用Faiss库;对于大规模数据,则采用mrpt库,以确保在各种使用场景下都能获得最佳性能。
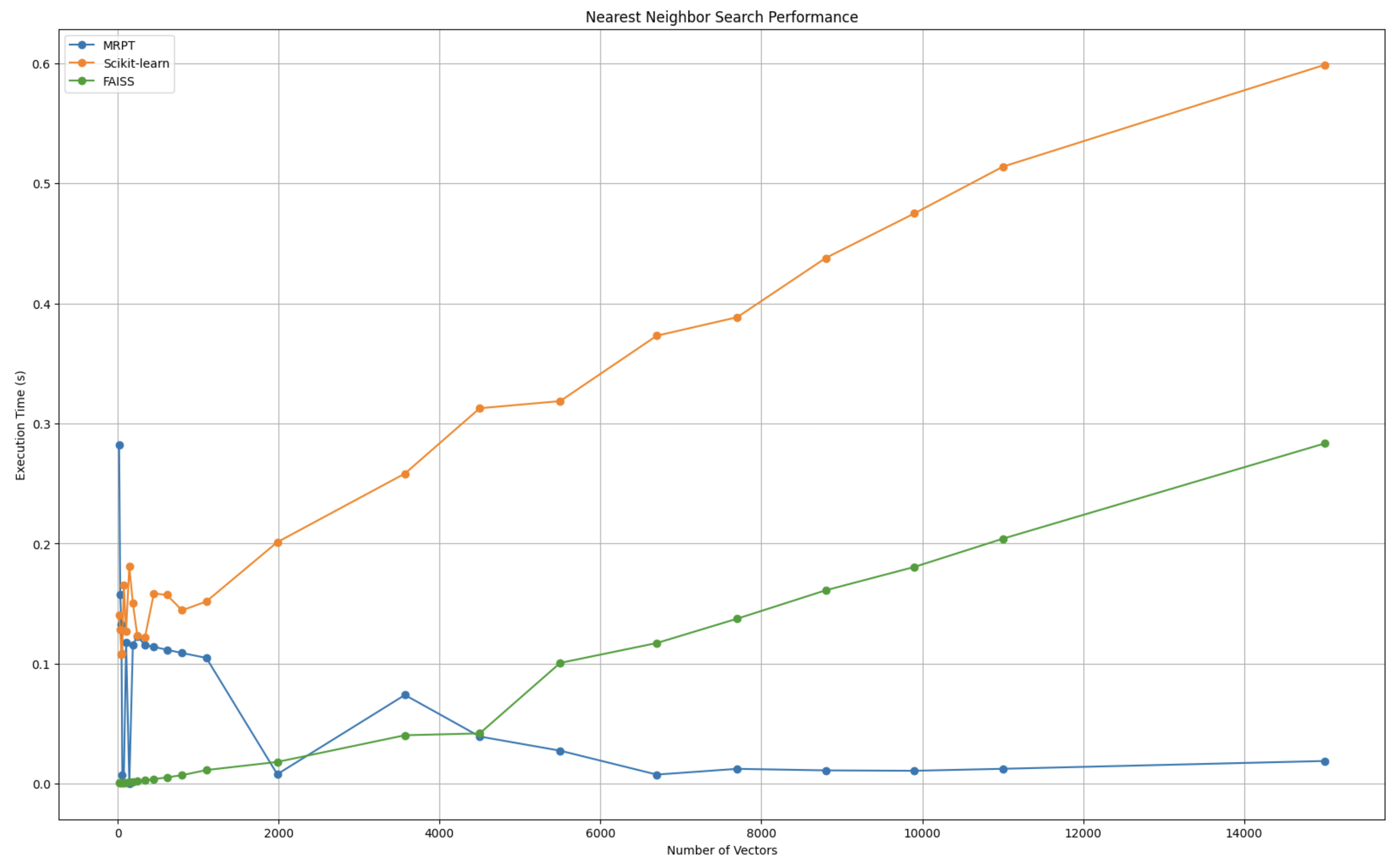
应用场景
VectorDB可以应用于多种AI和机器学习相关的场景,例如:
-
智能搜索引擎: 实现基于语义的文本搜索,提高搜索结果的相关性。
-
推荐系统: 基于文本相似度为用户推荐相关内容。
-
文档分类: 自动对大量文档进行分类和组织。
-
问答系统: 构建能够理解和回答自然语言问题的系统。
-
内容去重: 在大型文本数据集中识别和去除重复或相似的内容。
-
异常检测: 在文本数据中发现异常或不寻常的模式。
社区和支持
VectorDB是一个开源项目,欢迎社区贡献。开发者可以通过以下方式参与或获取支持:
- GitHub仓库: https://github.com/kagisearch/vectordb
- 问题反馈: 可以在GitHub上提交issues
- 贡献代码: 欢迎提交pull requests
- 文档: 详细的使用文档和API参考
结语
VectorDB为Python开发者提供了一个强大而易用的向量数据库解决方案。无论是构建小型原型还是大规模生产应用,VectorDB都能满足各种文本检索和分析需求。随着AI和机器学习技术的不断发展,VectorDB这样的工具将在未来扮演越来越重要的角色,帮助开发者更轻松地构建智能化应用。
如果你正在寻找一个高效、灵活的向量数据库工具,不妨尝试一下VectorDB。它可能会成为你AI项目开发过程中的得力助手。











