Visual-Chinese-LLaMA-Alpaca: 开启中文多模态AI新纪元
在人工智能快速发展的今天,多模态大语言模型成为了研究的热点。近日,一个名为Visual-Chinese-LLaMA-Alpaca(简称VisualCLA)的开源项目引起了广泛关注。这个项目基于中文LLaMA和Alpaca大模型,开发出了一个能够同时理解图像和文本的多模态中文大语言模型,为中文AI领域带来了新的突破。
VisualCLA的诞生背景
VisualCLA项目由中国科学院计算技术研究所等机构的研究人员开发。该项目源于对现有大语言模型局限性的思考 - 虽然像GPT等模型在文本处理方面表现出色,但它们缺乏对视觉信息的理解能力。研究团队意识到,要让AI系统更好地服务人类,就必须赋予其多模态理解的能力。
因此,他们基于此前开发的中文LLaMA和Alpaca模型,增加了图像编码等模块,使模型可以接收和处理视觉信息。通过多阶段的训练,VisualCLA最终具备了基本的多模态理解、对话和指令执行能力。
VisualCLA的技术亮点
VisualCLA的核心架构由三部分组成:
-
Vision Encoder: 采用ViT结构,负责对输入图像进行编码,生成图像的序列表示。
-
Resampler: 采用6层类BERT结构,对图像表示进行重采样和维度对齐。
-
LLM: 基于LLaMA模型,使用Chinese-Alpaca-Plus 7B初始化。
这种设计使得模型能够有效地融合图像和文本信息。在训练过程中,研究团队采用了多模态预训练和多模态指令精调两个阶段,使用了大量中文图文对数据和多模态指令数据,有效提升了模型的性能。
VisualCLA的能力展示
VisualCLA展现出了令人印象深刻的多模态理解和生成能力。它可以:
- 准确描述图片内容
- 回答关于图片的问题
- 结合图片进行推理
- 识别图片中的文字
- 理解复杂的多模态指令
例如,当向模型展示一幅梵高的《星夜》画作时,它不仅能准确描述画面内容,还能分析画作风格,甚至讨论梵高的生平和艺术特点。这种深度的理解和关联能力,展现了VisualCLA强大的多模态认知潜力。
VisualCLA的应用前景
VisualCLA的出现为多个领域带来了新的可能性:
-
智能客服: 可以理解用户上传的图片,提供更精准的服务。
-
内容创作: 辅助创作者生成与图片相关的文字内容。
-
教育辅助: 帮助学生理解复杂的图表和示意图。
-
医疗诊断: 协助医生分析医学影像,提供初步诊断建议。
-
视觉问答系统: 构建更智能的人机交互界面。
VisualCLA的开源与社区
值得一提的是,VisualCLA项目采取了开源策略。研究团队在GitHub上发布了项目代码、模型权重和详细文档,鼓励开发者和研究者进行二次开发和改进。这种开放共享的态度,无疑将加速多模态AI技术的发展和应用。
目前,VisualCLA已经吸引了众多开发者的关注。许多人在尝试将其部署到自己的项目中,探索更多可能性。社区的活跃也为项目带来了宝贵的反馈和改进建议。
VisualCLA的未来展望
尽管VisualCLA已经展现出impressive的能力,但研究团队坦言,当前版本仍有改进空间。例如,模型在处理精细文字、复杂图表时的准确率还有待提高,且在长对话中的表现也需要优化。
未来,研究团队计划从以下几个方面继续完善VisualCLA:
- 扩大训练数据规模,提高模型的知识储备。
- 优化模型结构,提升多模态信息的融合效果。
- 改进训练策略,增强模型的长程依赖能力。
- 探索更多的下游任务适配,拓展应用场景。
结语
Visual-Chinese-LLaMA-Alpaca的出现,标志着中文多模态AI研究迈出了重要一步。它不仅展示了中国AI研究的实力,也为未来更智能、更全面的AI系统指明了方向。随着技术的不断进步和社区的共同努力,我们有理由相信,像VisualCLA这样的多模态大语言模型将在不久的将来改变我们与AI交互的方式,为人类社会带来更多便利和价值。
作为AI领域的从业者或爱好者,我们应该密切关注VisualCLA等项目的发展,积极参与到开源社区中来,共同推动多模态AI技术的进步。让我们携手迎接AI带来的新机遇,共创智能化的美好未来。
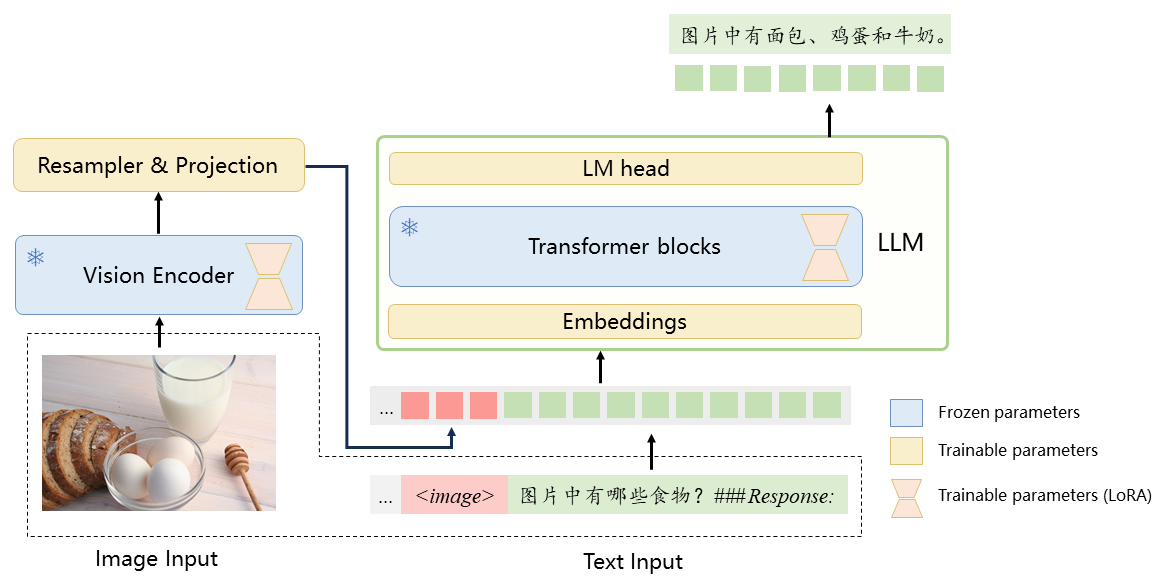
图: VisualCLA模型的整体架构
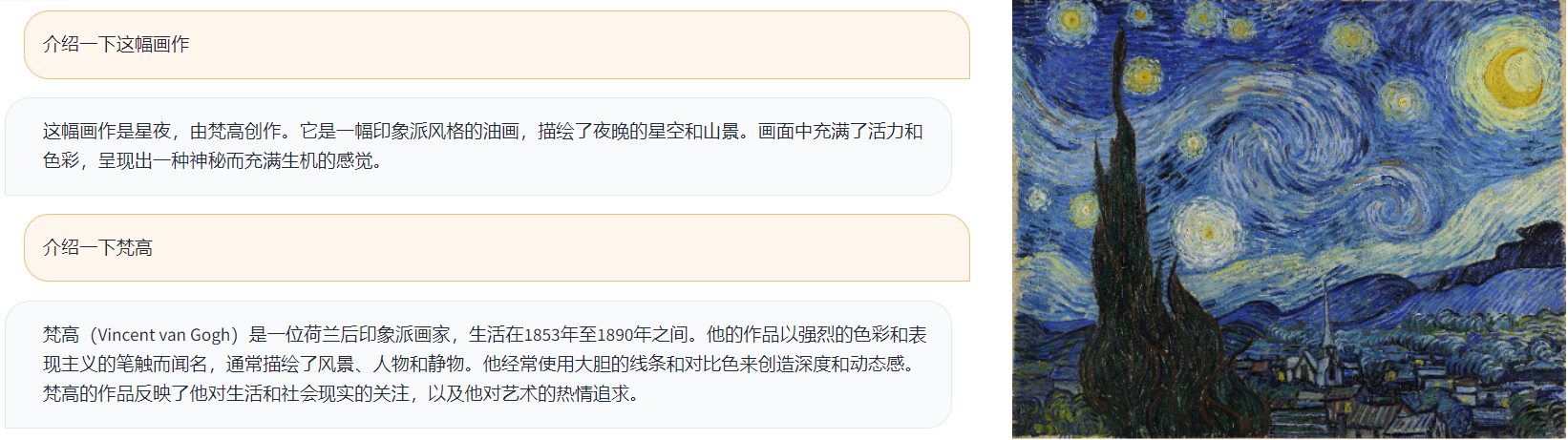
图: VisualCLA对梵高《星夜》的分析示例










