
Visual-Chinese-LLaMA-Alpaca: 多模态中文大语言模型
Visual-Chinese-LLaMA-Alpaca(简称VisualCLA)是一个支持图像和文本输入的中文多模态大语言模型。本文汇总了该项目的相关学习资源,帮助读者快速了解和使用这个模型。
项目简介
VisualCLA在中文Alpaca模型的基础上,添加了图像编码模块,使模型能够理解视觉信息。其主要特点包括:
- 基于Chinese-LLaMA-Alpaca开发,具备多模态指令理解和对话能力
- 模型结构包含Vision Encoder、Resampler和LLM三部分
- 采用LoRA方法进行高效训练
- 开源了7B参数量的测试版模型
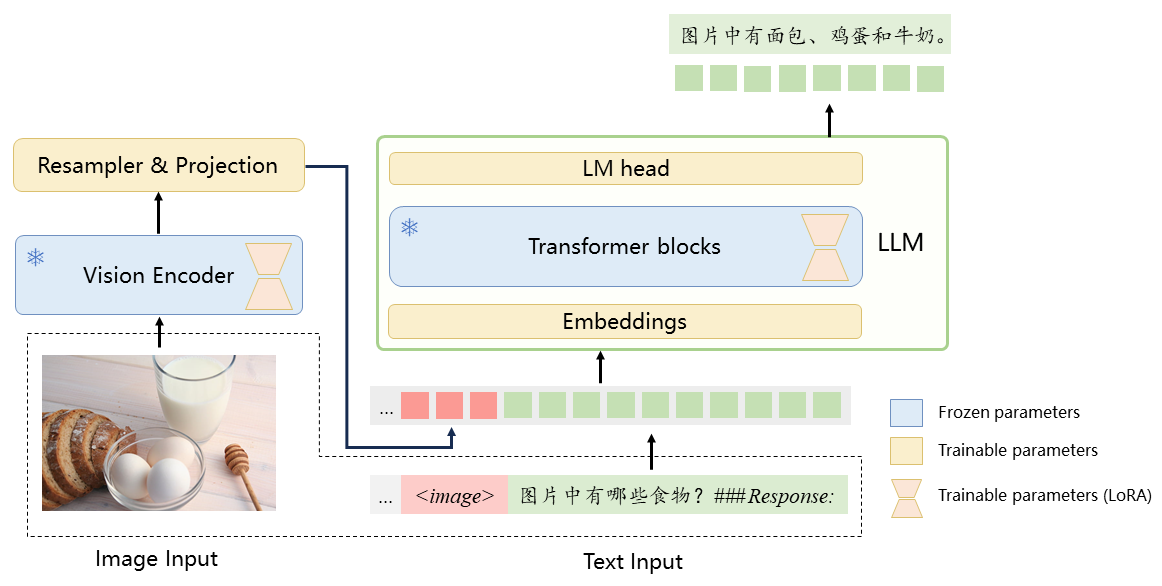
模型下载
VisualCLA-7B-v0.1模型下载链接:
也可以在🤗Model Hub下载模型。
使用教程
- 安装依赖:
git clone https://github.com/airaria/Visual-Chinese-LLaMA-Alpaca
cd Visual-Chinese-LLaMA-Alpaca
pip install -e .
- 模型加载与推理:
import torch
import visualcla
model, tokenizer, _ = visualcla.get_model_and_tokenizer_and_processor(
visualcla_model="/path/to/visualcla/model",
torch_dtype=torch.float16,
load_in_8bit=True
)
model.to(0)
history = []
visualcla.chat(model=model, image="image.jpg", text="描述这张图片", history=history)
- 命令行推理:
python scripts/inference/inference.py \
--visualcla_model /path/to/visualcla/model \
--image_file image.jpg \
--load_in_8bit
- 启动Gradio demo:
python scripts/inference/gradio_demo.py --visualcla_model /path/to/visualcla/model --load_in_8bit
效果展示
以下是VisualCLA-7B-v0.1模型的一些示例效果:
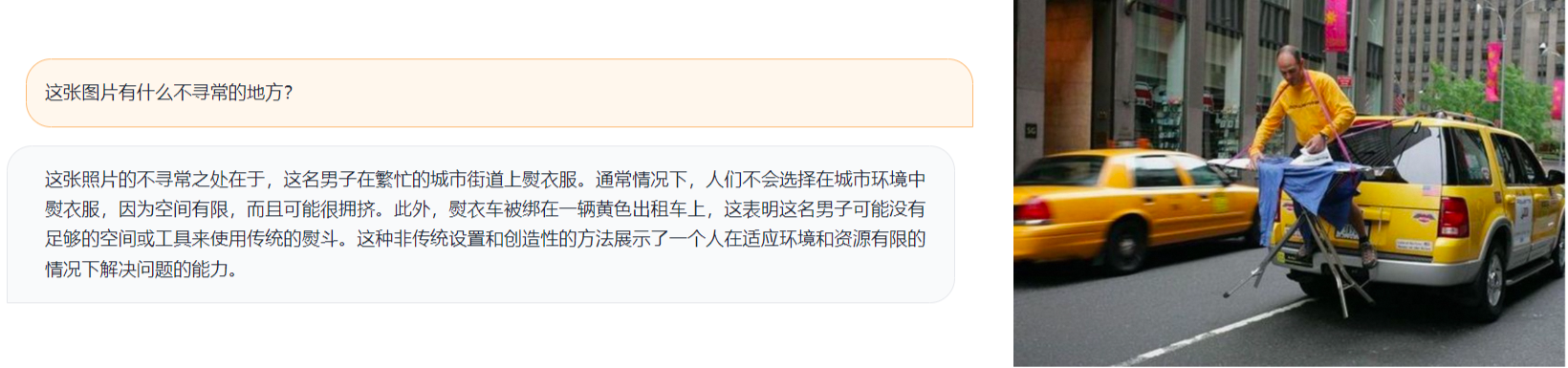
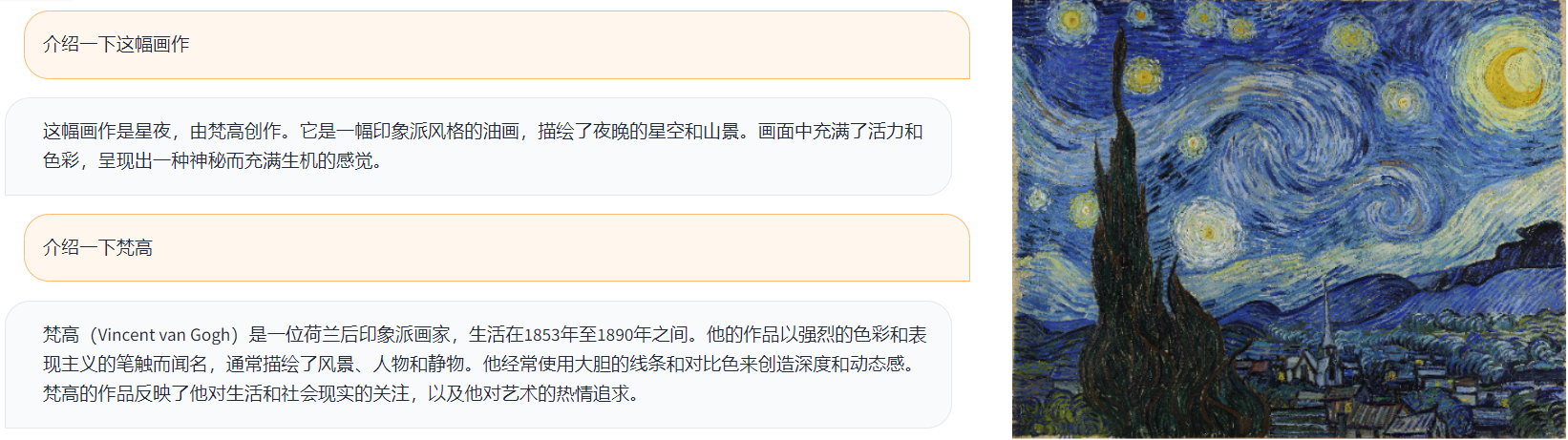
更多资源
VisualCLA作为一个开源的中文多模态大语言模型,为研究人员提供了宝贵的学习资源。欢迎大家尝试使用并为项目做出贡献!










