
WhisperX:音频转录的革命性突破
在人工智能和自然语言处理领域,精准的语音识别技术一直是研究热点。近期,由牛津大学视觉几何组(VGG)支持开发的WhisperX项目在这一领域取得了重大突破。WhisperX在OpenAI的Whisper模型基础上,通过创新的技术方案,实现了更快速、更精确的语音转录,并首次在开源项目中加入了说话人分离功能。这一技术的出现,将为众多依赖语音识别的应用场景带来革命性的变革。
核心技术创新
WhisperX的核心创新主要体现在以下几个方面:
-
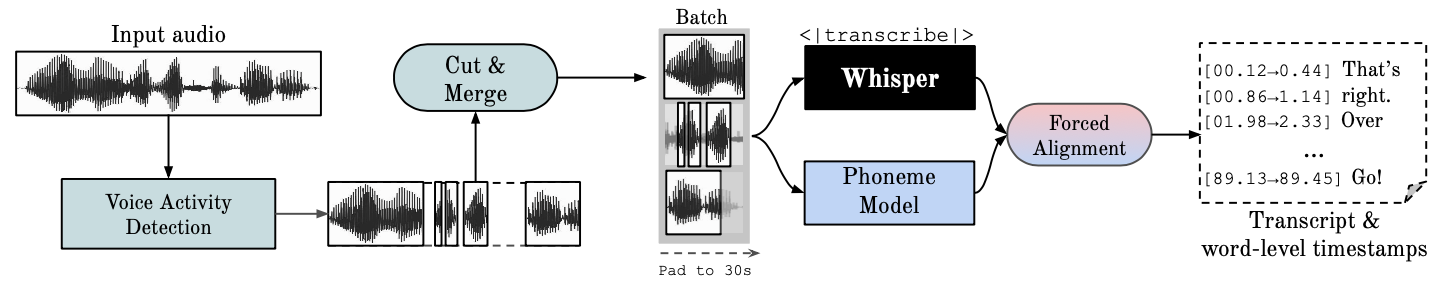
批处理加速: 通过使用faster-whisper后端和批处理技术,WhisperX可以实现70倍实时速度的转录效率,大大提升了处理长音频的能力。
-
精确时间戳: 利用wav2vec2对齐技术,WhisperX能够生成精确到单词级别的时间戳,这对于字幕制作、会议记录等应用至关重要。
-
说话人分离: 集成了pyannote-audio的说话人分离技术,可以自动识别不同说话人并为转录文本添加标签。
-
VAD预处理: 采用语音活动检测(VAD)预处理,有效减少了幻听现象,提高了转录准确性。
-
多语言支持: 支持英语、法语、德语、西班牙语等多种语言的识别和转录。
应用场景与影响
WhisperX的出现为多个领域带来了新的可能:
- 媒体制作: 自动生成精确时间戳的字幕,大幅提升视频后期制作效率。
- 会议记录: 自动区分发言人并生成会议纪要,为企业和学术交流提供便利。
- 语音分析: 为语音数据挖掘和分析提供更精确的基础数据。
- 口译辅助: 为同声传译人员提供实时的文字参考。
使用方法
WhisperX的使用非常简单,以下是一个基本的命令行使用示例:
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
这条命令会对示例音频进行转录,使用large-v2模型,开启说话人分离功能,并在输出的.srt文件中高亮显示单词时间戳。
对于开发者来说,WhisperX也提供了Python API,允许更灵活的集成和定制:
import whisperx
device = "cuda"
audio_file = "audio.mp3"
model = whisperx.load_model("large-v2", device)
result = model.transcribe(audio_file)
# 对齐和说话人分离
model_a, metadata = whisperx.load_align_model(language_code=result["language"], device=device)
result = whisperx.align(result["segments"], model_a, metadata, audio_file, device)
diarize_model = whisperx.DiarizationPipeline(use_auth_token=YOUR_HF_TOKEN, device=device)
diarize_segments = diarize_model(audio_file)
result = whisperx.assign_word_speakers(diarize_segments, result)
未来展望
尽管WhisperX已经展现出强大的性能,但开发团队仍在不断完善和扩展其功能:
- 进一步优化多语言支持
- 改进说话人分离的准确性
- 探索更多降低GPU内存需求的方法
- 集成更多VAD选项,如silero-vad
随着这些改进的实现,WhisperX有望在更广泛的应用场景中发挥作用,推动语音识别技术向更高水平发展。
结语
WhisperX的出现标志着语音识别技术进入了一个新的阶段。它不仅大幅提升了转录速度和准确性,还通过引入说话人分离等创新功能,为语音数据的深度应用铺平了道路。无论是在学术研究还是商业应用中,WhisperX都展现出巨大的潜力。我们期待看到更多基于WhisperX的创新应用,推动语音交互和分析技术的进一步发展。










