
XNNPACK简介
XNNPACK是Google开发的一个高度优化的神经网络推理库,专为移动设备、服务器和Web平台提供高效的浮点神经网络推理运算。它是一个低级别的性能原语库,主要用于加速高级机器学习框架,如TensorFlow Lite、TensorFlow.js、PyTorch、ONNX Runtime和MediaPipe等。
XNNPACK的设计目标是在保证高性能的同时,支持多种硬件平台和神经网络运算符。它针对ARM、x86、WebAssembly和RISC-V等平台进行了深度优化,可以充分发挥各种硬件的计算能力。
支持的硬件平台
XNNPACK支持以下硬件平台:
- ARM64:支持Android、iOS、macOS、Linux和Windows
- ARMv7(带NEON):支持Android
- ARMv6(带VFPv2):支持Linux
- x86和x86-64(支持AVX512):支持Windows、Linux、macOS、Android和iOS模拟器
- WebAssembly MVP
- WebAssembly SIMD
- WebAssembly Relaxed SIMD(实验性)
- RISC-V (RV32GC和RV64GC)
这种广泛的平台支持使XNNPACK成为跨平台神经网络部署的理想选择。
支持的运算符
XNNPACK实现了神经网络中常用的大量运算符,包括但不限于:
- 2D卷积(包括分组卷积和深度卷积)
- 2D反卷积(又称转置卷积)
- 2D平均池化和最大池化
- 全连接层
- 激活函数(ReLU、Sigmoid、Tanh等)
- 归一化操作
- 张量运算(加、减、乘、除等)
所有运算符都支持NHWC布局,并且允许沿着通道维度进行自定义步长。这意味着运算符可以只处理输入张量的一部分通道,为实现零成本的通道分割和连接提供了可能。
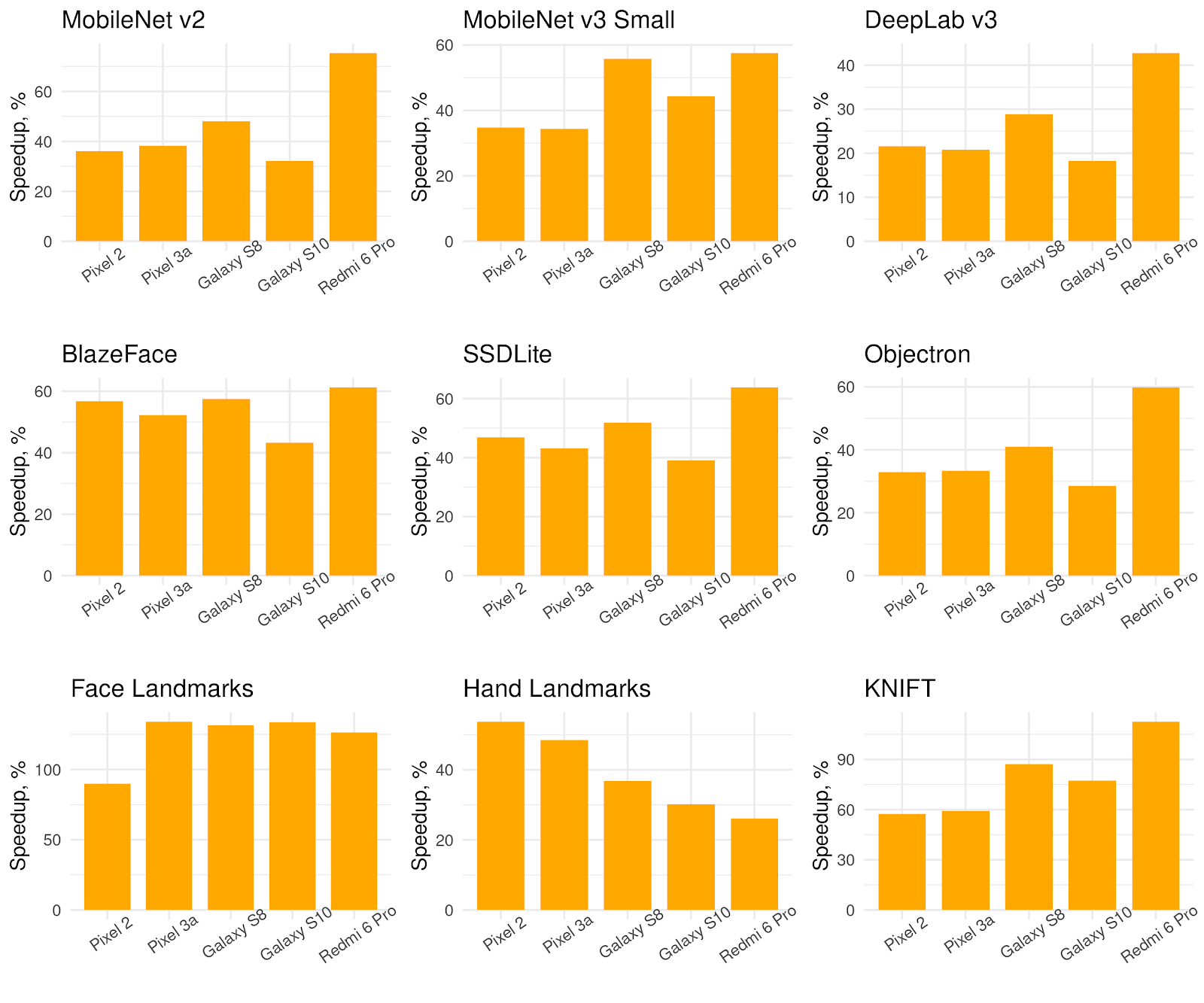
性能表现
XNNPACK在移动设备上展现出优异的性能。下面是在三代Pixel手机上运行MobileNet系列模型的单线程性能数据:
| 模型 | Pixel (ms) | Pixel 2 (ms) | Pixel 3a (ms) |
|---|---|---|---|
| FP32 MobileNet v1 1.0X | 82 | 86 | 88 |
| FP32 MobileNet v2 1.0X | 49 | 53 | 55 |
| FP32 MobileNet v3 Large | 39 | 42 | 44 |
| FP32 MobileNet v3 Small | 12 | 14 | 14 |
多线程性能更加出色:
| 模型 | Pixel (ms) | Pixel 2 (ms) | Pixel 3a (ms) |
|---|---|---|---|
| FP32 MobileNet v1 1.0X | 43 | 27 | 46 |
| FP32 MobileNet v2 1.0X | 26 | 18 | 28 |
| FP32 MobileNet v3 Large | 22 | 16 | 24 |
| FP32 MobileNet v3 Small | 7 | 6 | 8 |
XNNPACK在Raspberry Pi等嵌入式设备上也表现不俗。以下是在不同代Raspberry Pi上的多线程性能数据:
| 模型 | RPi Zero W (ms) | RPi 2 (ms) | RPi 3+ (ms) | RPi 4 (ms) | RPi 4 ARM64 (ms) |
|---|---|---|---|---|---|
| FP32 MobileNet v1 1.0X | 3919 | 302 | 114 | 72 | 77 |
| FP32 MobileNet v2 1.0X | 1987 | 191 | 79 | 41 | 46 |
| FP32 MobileNet v3 Large | 1658 | 161 | 67 | 38 | 40 |
| FP32 MobileNet v3 Small | 474 | 50 | 22 | 13 | 15 |
| INT8 MobileNet v1 1.0X | 2589 | 128 | 46 | 29 | 24 |
| INT8 MobileNet v2 1.0X | 1495 | 82 | 30 | 20 | 17 |
这些数据充分展示了XNNPACK在不同硬件平台上的优异性能表现。
最新进展:动态范围量化
最近,XNNPACK在全连接和2D卷积运算符中新增了对动态范围量化的支持。这一改进使得推理性能相比单精度基准提升了4倍。动态范围量化是介于全整数量化和单精度浮点推理之间的一种折中方案,它在保持较高精度的同时,可以获得接近全整数量化的性能提升。
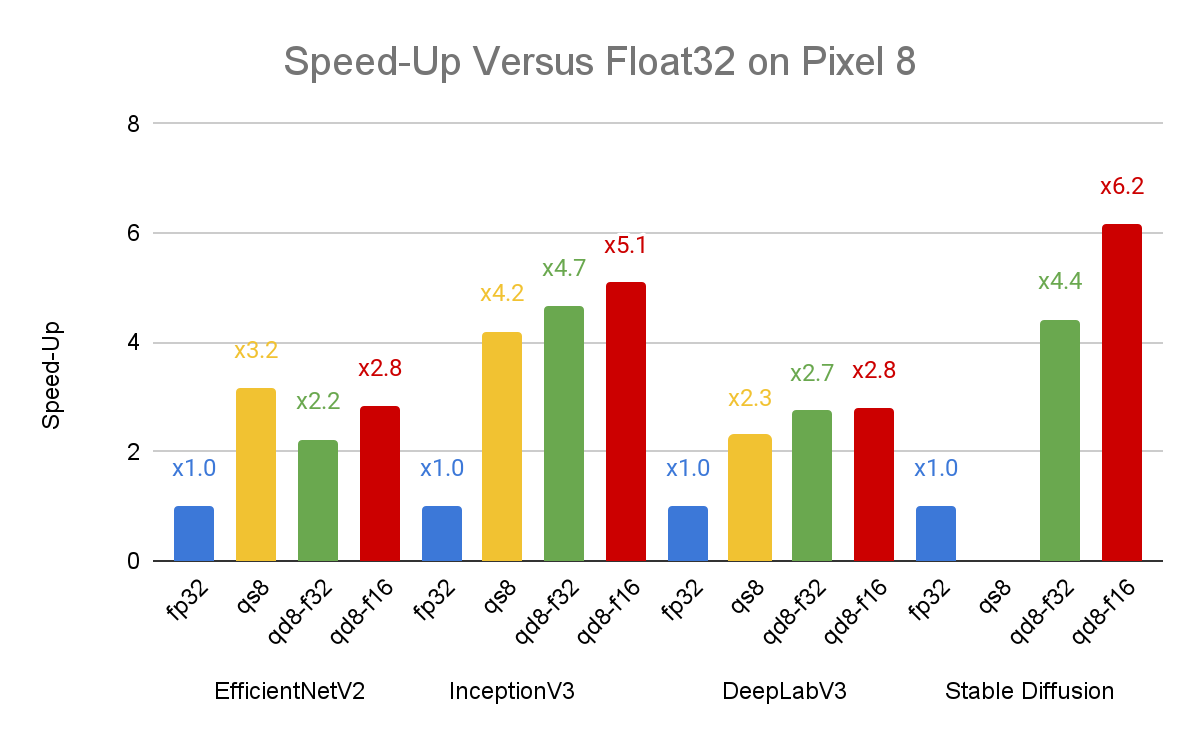
在EfficientNetV2、Inception-v3、Deeplab-v3等模型上,动态范围量化的性能已经可以与全整数量化相媲美,甚至在某些情况下表现更佳。这一改进使得更多AI功能可以部署到老旧和低端设备上。
使用XNNPACK
XNNPACK已经集成到多个主流机器学习框架中,包括:
对于想要直接使用XNNPACK的开发者,该项目提供了C API。但需要注意的是,XNNPACK主要面向框架开发者,而非直接面向深度学习实践者和研究人员。
构建要求
要构建XNNPACK,需要满足以下最低要求:
- C11
- C++14
- Python 3
总结
XNNPACK是一个强大的神经网络推理库,为移动设备、服务器和Web平台提供了高效的浮点运算支持。它优秀的跨平台性能和广泛的运算符支持,使其成为部署深度学习模型的理想选择。随着动态范围量化等新特性的加入,XNNPACK正在不断提升其性能和适用范围,为更多设备带来AI能力。
无论您是框架开发者还是对高性能神经网络推理感兴趣的研究人员,XNNPACK都值得您深入了解和尝试。欢迎访问XNNPACK的GitHub仓库以获取更多信息。










