
Zotero OCR插件简介
Zotero OCR是由曼海姆大学图书馆开发的一款开源插件,旨在为Zotero用户提供PDF文档的光学字符识别(OCR)功能。作为一款专为学术研究设计的文献管理软件,Zotero在管理PDF文档方面表现出色。而Zotero OCR插件的加入,进一步增强了Zotero处理扫描版PDF的能力,使得用户可以更加高效地搜索和管理这类文档。
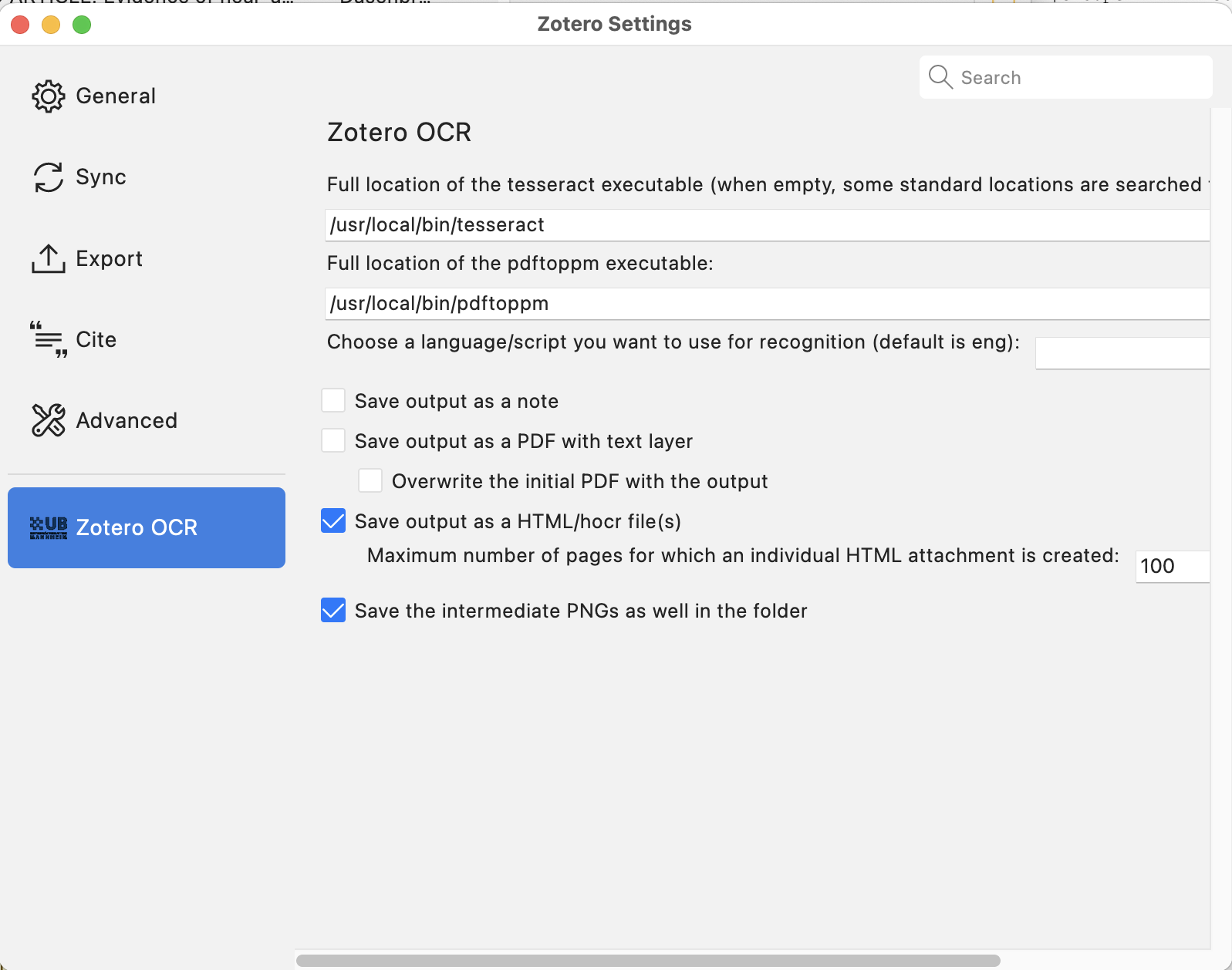
主要功能特点
-
PDF文档OCR识别:Zotero OCR插件可以对Zotero库中选中的PDF文档进行OCR处理,生成包含可识别文本的新PDF文件。
-
提取识别文本:插件能够将OCR识别的文本单独提取出来,以注释的形式添加到Zotero中,方便用户快速查阅和搜索。
-
生成HTML(HOCR)文件:除了生成新的PDF和提取文本,插件还可以生成包含原始图像和识别文本的HTML文件,为用户提供更多选择。
-
多语言支持:基于Tesseract OCR引擎,Zotero OCR插件支持多种语言的文字识别,满足不同用户的需求。
-
自定义设置:用户可以在插件设置中调整OCR引擎路径、语言选项等参数,以适应个人使用习惯。
安装与配置
要使用Zotero OCR插件,需要先安装以下依赖:
- Tesseract OCR:负责文字识别的核心引擎
- pdftoppm:用于将PDF转换为图像的工具(来自poppler库)
安装步骤如下:
- 下载并安装Tesseract OCR和pdftoppm
- 从GitHub releases页面下载最新版本的Zotero OCR插件(.xpi文件)
- 在Zotero中,点击"工具" -> "附加组件",将下载的.xpi文件拖拽到附加组件窗口中完成安装
- 重启Zotero
- 在Zotero的"工具" -> "Zotero OCR首选项"中,填写Tesseract和pdftoppm的路径
对于Mac用户,可以使用Homebrew简化安装过程:
brew install tesseract
brew install poppler
使用方法
安装配置完成后,使用Zotero OCR插件的步骤非常简单:
- 在Zotero库中选择需要OCR的PDF文档
- 右键点击,选择"Perform OCR"选项
- 等待OCR处理完成,新生成的PDF文件将自动添加到Zotero库中
用户反馈与建议
Zotero OCR插件得到了广大用户的好评,许多人表示这大大提高了他们管理扫描版PDF的效率。然而,也有用户提出了一些建议:
- 希望OCR功能能够直接集成到Zotero核心功能中,无需额外安装插件。
- 对于手写文档或老旧字体的识别效果有待提高。
- 部分用户反映OCR处理后的PDF文件体积显著增大,希望能够提供压缩选项。
未来展望
Zotero OCR插件的开发团队一直在积极改进产品。最新版本已经支持Zotero 7,并计划进一步优化OCR性能,提高识别准确率。同时,也在考虑增加更多自定义选项,如OCR质量和文件大小的平衡设置等。
结语
Zotero OCR插件无疑是提升学术文献管理效率的有力工具。它不仅能够帮助研究者更好地组织和检索扫描版文献,还为数字化保存和分享珍贵历史文献提供了便利。尽管仍有改进空间,但Zotero OCR插件已经成为许多学者工作流程中不可或缺的一部分。无论你是学生、教师还是研究人员,如果经常需要处理大量PDF文献,Zotero OCR插件都值得一试。
最后,值得一提的是,Zotero OCR插件是一个开源项目,欢迎感兴趣的开发者参与贡献,共同推动学术工具的进步。让我们期待Zotero OCR插件在未来能够带来更多惊喜,为学术研究提供更强大的支持。










