
 访问官网
访问官网 Github
Github 文档
文档Zotero OCR




这个Zotero插件为在Zotero中选择的PDF添加了执行OCR的功能。它可以添加一个包含识别文本的新PDF,一个仅包含识别文本的笔记,以及HTML(HOCR)文件。文本识别本身使用Tesseract OCR进行。
先决条件
- 已安装Tesseract OCR
- Windows用户请参见 https://github.com/UB-Mannheim/tesseract/wiki
- Linux和Mac用户请参见 https://tesseract-ocr.github.io/tessdoc/Installation.html
- 已下载并安装poppler库中的
pdftoppm
安装
安装扩展:
- 下载最新版本的XPI文件。
- 在Zotero中,转到工具→附加组件,并将.xpi文件拖到附加组件窗口上。
- 可能需要在附加组件选项中调整Tesseract的路径。
配置
可以在工具→Zotero OCR首选项(Zotero 6)或Zotero→设置(Zotero 7)中访问配置。
默认情况下,OCR引擎和pdftoppm路径字段为空,这意味着会查看常用位置。如果不起作用,你应该在本地机器上找到这些工具,并输入包含工具本身名称的完整路径。
Tesseract使用的默认语言/脚本只能是已安装模型中的一个。如果你将该字段留空,将使用始终与Tesseract一起安装的英语模型(eng)。
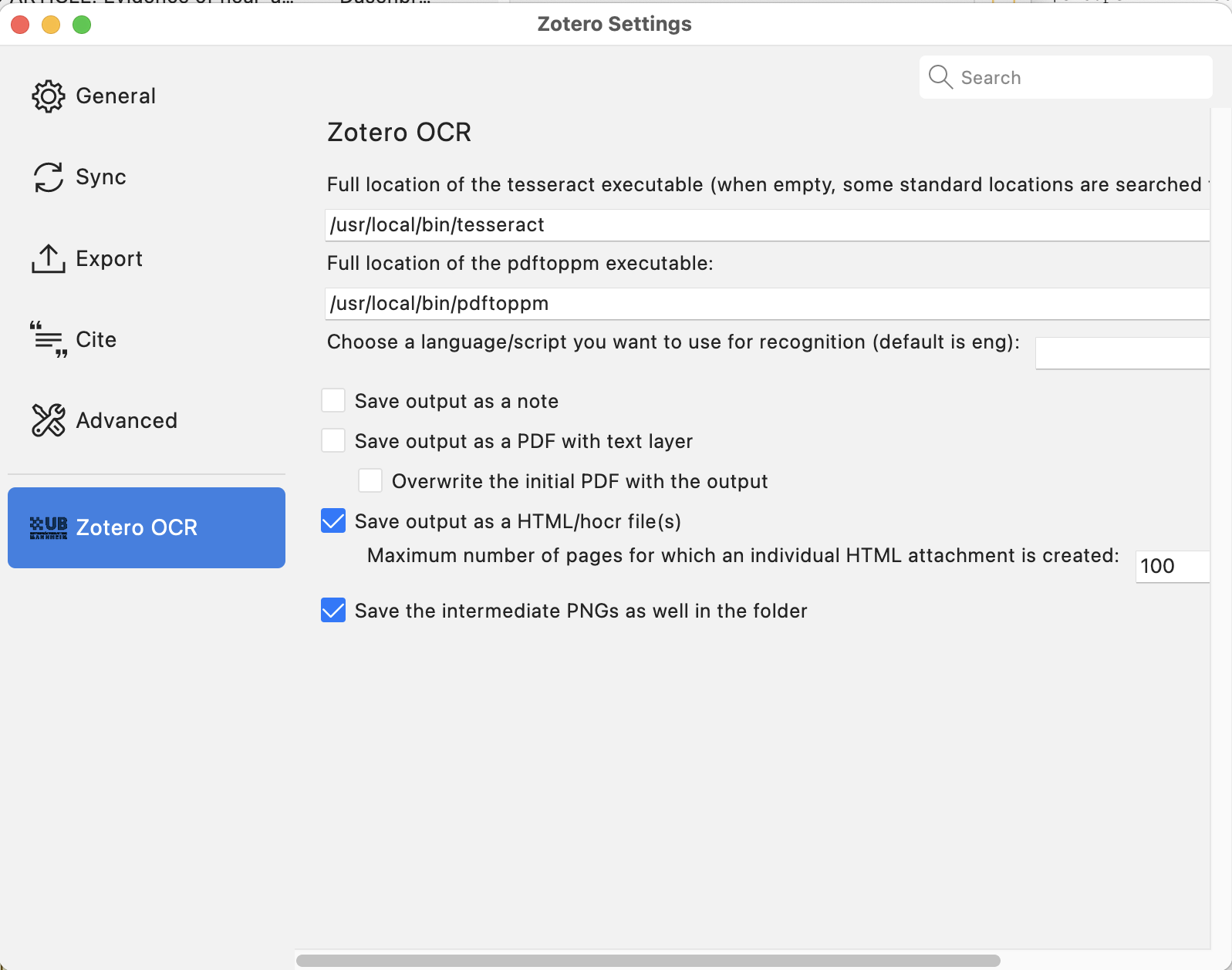
此外,这些选项被保存为Zotero首选项变量,也可以通过配置编辑器访问。
构建和发布
运行build.sh脚本,创建新的.xpi文件。
对于新版本,运行release.sh脚本。它会运行build.sh脚本,提交新版本的代码更改并添加标签。将更新后的本地master分支和标签推送到GitHub。然后在GitHub上发布新版本并附上.xpi文件。
开发
代码更改后,可以通过./build.sh <版本>构建新的扩展文件。然后在Zotero中转到工具,附加组件,从文件安装附加组件...,并选择新创建的.xpi文件。Zotero 6将重启并加载新构建的附加组件版本。Zotero 7无需重启,会立即激活它。
如果出现任何错误,可以在帮助,报告错误...对话框中看到更多详细信息。要查看一些调试消息,可以在Zotero的帮助中激活调试输出日志记录。
许可证
Zotero OCR是免费的开源软件。源代码根据GNU Affero通用公共许可证v3发布。











