
 访问官网
访问官网 Github
Github 文档
文档tesstrain
用于 Tesseract 5 的训练工作流程,以 Makefile 形式实现依赖跟踪。
安装
辅助工具
你至少需要 GNU make(最低版本 4.2)、wget、find、bash 和 unzip。
Leptonica, Tesseract
你需要最新版本(>= 5.3)的 Tesseract,并且需要包含训练工具和匹配的 Leptonica 绑定。 编译 说明 以及更多信息可以在 Tesseract 用户手册 中找到。
Windows
- 安装最新版 Tesseract(例如从 https://digi.bib.uni-mannheim.de/tesseract/ 下载),并确保 Tesseract 已添加到你的 PATH 中。
- 安装 Python 3
- 安装 Git SCM for Windows - 它提供了许多 Linux 工具在 Windows 上的版本(如
find、unzip、rm),并将C:\Program Files\Git\usr\bin添加到 PATH 变量的开头(临时可以在cmd中使用set PATH=C:\Program Files\Git\usr\bin;%PATH%来实现)- 不幸的是,有几个 Windows 工具与 Linux 上的同名工具(find、sort)有不同的行为/功能,需要在训练过程中避免使用它们。 - 安装 winget/Windows 包管理器,然后运行
winget install ezwinports.make和winget install wget来安装缺失的工具。
Python
你需要最新版本的 Python 3.x。图像处理使用 Python 库 Pillow。
如果你没有全局安装,请使用提供的 requirements 文件 pip install -r requirements.txt。
语言数据
Tesseract 需要一些配置数据(radical-stroke.txt 文件和所有脚本的 *.unicharset)放在 DATA_DIR 中。
要获取它们:
make tesseract-langdata
(虽然这一步只需要执行一次,并且隐含在 training 目标中,但你可能想要提前显式运行它。)
使用方法
选择模型名称
为你的模型选择一个名称。按照惯例,包含特定语言资源的 Tesseract 堆叠模型使用 ISO 639 中定义的(小写)三字母代码,并用下划线分隔附加信息。例如,chi_tra_vert 表示垂直排版的繁体中文。与语言无关(即特定于脚本)的模型使用大写的脚本类型名称作为标识符。例如,Hangul_vert 表示垂直排版的谚文脚本。在以下内容中,模型名称用 MODEL_NAME 表示。
提供真实数据
将由行图像和转录文本组成的真实数据放在 data/MODEL_NAME-ground-truth 文件夹中。这些文件将被分为训练和评估数据,比例由 RATIO_TRAIN 变量定义。
图像必须是 TIFF 格式并具有 .tif 扩展名,或者是 PNG 格式并具有 .png、.bin.png 或 .nrm.png 扩展名。
转录文本必须是单行纯文本,并且与行图像具有相同的名称,但图像扩展名替换为 .gt.txt。
该仓库包含一个带有样本真实数据的 ZIP 存档,请参见 ocrd-testset.zip。将其解压到 ./data/foo-ground-truth 并运行 make training。
注意: 如果你想从整页生成用于转录的行图像,请参见 issue 7 中的提示,特别是 @Shreeshrii 的 shell 脚本。
训练
运行
make training MODEL_NAME=name-of-the-resulting-model
这是以下命令的快捷方式
make unicharset lists proto-model tesseract-langdata training MODEL_NAME=name-of-the-resulting-model
运行 make help 查看所有可用的目标和变量:
选择训练方案
首先,决定你想要进行哪种类型的训练。
- 微调:选择(并安装)一个
START_MODEL - 从头开始:指定一个
NET_SPEC(参见文档)
更改目录假设
要覆盖默认的路径名要求,只需在上面的列表中设置相应的变量:
make training MODEL_NAME=name-of-the-resulting-model DATA_DIR=/data GROUND_TRUTH_DIR=/data/GT
如果你想使用shell变量来覆盖make变量(例如因为你正在从脚本或其他makefile运行tesstrain),那么你可以使用-e标志:
MODEL_NAME=结果模型的名称 DATA_DIR=/data GROUND_TRUTH_DIR=/data/GT make -e training
制作模型文件(traineddata)
当训练完成后,它会写入一个可以用于Tesseract文本识别的traineddata文件。请注意,这个文件不包含字典。因此tesseract可执行文件会打印一个警告。
也可以从中间训练结果(所谓的检查点)创建额外的traineddata文件。这甚至可以在训练仍在进行时完成。例如:
# 添加MODEL_NAME和OUTPUT_DIR,与训练时相同。
make traineddata
这将在OUTPUT_DIR中创建两个目录tessdata_best和tessdata_fast,每个检查点都有最佳(基于双精度)和快速(基于整数)模型。
也可以只为选定的检查点创建模型。例如:
# 为最近三周的检查点文件制作traineddata。
make traineddata CHECKPOINT_FILES="$(find data/foo -name '*.checkpoint' -mtime -21)"
# 为最后两个检查点文件制作traineddata。
make traineddata CHECKPOINT_FILES="$(ls -t data/foo/checkpoints/*.checkpoint | head -2)"
# 为字符错误率(CER)优于1%的所有检查点文件制作traineddata。
make traineddata CHECKPOINT_FILES="$(ls data/foo/checkpoints/*[^1-9]0.*.checkpoint)"
如有需要,添加MODEL_NAME和OUTPUT_DIR,并将data/foo替换为输出目录。
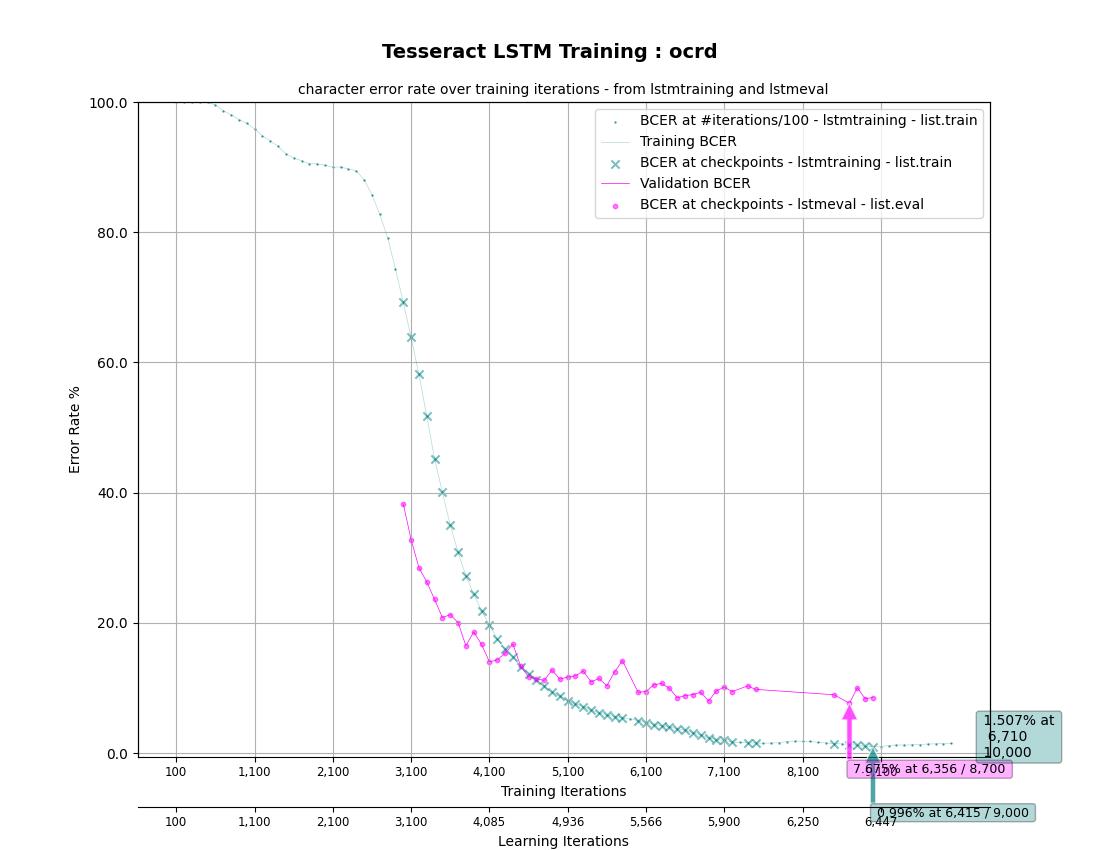
绘制CER图
可以使用Matplotlib绘制训练和评估字符错误率(CER):
# 生成OUTPUT_DIR/MODEL_FILE.plot_*.png
make plot
上面定义的所有变量都适用,但没有对training的显式依赖。
尽管如此,该目标仍然依赖于训练期间捕获的LOG_FILE(只是不会触发训练本身)。除了分析日志文件外,这还直接在评估数据集上评估训练好的模型(对每个检查点)。后者也可作为独立目标evaluation使用:
# 生成OUTPUT_DIR/eval/MODEL_FILE*.*.log
make evaluation
即使在训练仍在进行时也可以进行绘图,并将描绘到那时为止的训练状态。(只要LOG_FILE发生变化或写入新的检查点,就可以随时重新运行。)
作为示例,使用ocrd-testset.zip中提供的训练数据进行一些训练并生成图表:
unzip ocrd-testset.zip -d data/ocrd-ground-truth
make training MODEL_NAME=ocrd START_MODEL=frk TESSDATA=~/tessdata_best MAX_ITERATIONS=10000 &
# 生成data/ocrd/ocrd.plot_cer.png和plot_log.png(在训练期间/之后重复)
make plot MODEL_NAME=ocrd
然后应该看起来像这样:
许可证
软件根据Apache 2.0许可证的条款提供。
由Deutsches Textarchiv提供的样本训练数据属于公共领域。











