
gpu.cpp
gpu.cpp是一个轻量级库,旨在简化C++中的可移植GPU计算。
它专注于通用原生GPU计算,利用WebGPU规范作为可移植的低级GPU接口。这意味着我们可以在C++项目中嵌入GPU代码,并使其在Nvidia、Intel、AMD和其他GPU上运行。同样的C++代码可以在各种笔记本电脑、工作站、移动设备或几乎任何支持Vulkan、Metal或DirectX的硬件上运行。
技术目标:轻量级、快速迭代和低样板代码
通过gpu.cpp,我们希望为个人开发者和研究人员提供一个高杠杆率的库,只需要标准C++编译器作为工具,就能将GPU计算整合到程序中。我们的目标是:
- 高效率API:提供最小的API表面积,同时覆盖全范围的GPU计算需求。
- 快速编译/运行周期:确保项目能几乎即时构建,在现代笔记本电脑上编译/运行周期应不超过5秒。
- 最少的依赖和工具开销:标准的clang C++编译器应该足够,除WebGPU原生实现外无需其他外部库依赖。
实现旨在保持最小的API表面积和最少的样板代码。只需少量的库操作即可执行广泛的低级GPU操作。我们避免增加间接层的抽象,使gpu.cpp库与原始WebGPU API之间的映射在需要时清晰可见。
本着快速实验的精神,我们还希望C++构建几乎瞬时完成,即使在性能一般的个人计算设备上也不超过一两秒。考虑到这一点,我们不仅保持API表面积小,还保持实现小巧,并提供Dawn原生WebGPU实现的预构建二进制文件。
核心库在仅头文件的gpu.h源代码中的实现约为1000行代码。除了实现瞬时、半交互式的编译周期外,小型实现表面积还能降低维护负担并提高改进速度。
我们还将Google的Dawn WebGPU实现预构建为共享库二进制文件。这允许构建时链接共享库,并在不增加开发周期中重新编译Dawn成本的情况下,整合Google强大的原生WebGPU实现。
对于更高级的用户和发布部署,我们提供了使用cmake从头到尾构建Dawn和gpu.cpp的示例,但大多数用户无需也不建议这样做。
快速入门:构建和运行
要构建gpu.cpp项目,您需要在系统上安装:
- 支持C++17的
clang++编译器。 python3或更高版本,用于运行下载Dawn共享库的脚本。make用于构建项目。- 仅限Linux系统 - Vulkan驱动程序。如果未安装Vulkan,可以运行
sudo apt install libvulkan1 mesa-vulkan-drivers vulkan-tools来安装。
gpu.cpp唯一的库依赖是WebGPU实现。目前我们支持Dawn原生后端,但计划支持其他目标和WebGPU实现(Web浏览器或其他原生实现如wgpu)。目前支持MacOS、Linux和Windows(通过WSL)。
可选地,可以使用提供的cmake构建脚本从头开始构建Dawn和gpu.cpp - 请参见Makefile中的-cmake目标。但这仅建议高级用户使用。使用cmake构建Dawn依赖项比使用预编译的Dawn共享库耗时更长。
克隆仓库后,在gpu.cpp的顶级目录中,您应该能够通过输入以下命令来构建和运行hello world GELU示例:
make
首次以这种方式构建和运行项目时,它会自动下载Dawn原生WebGPU实现的预构建共享库(使用setup.py脚本)。这会将Dawn共享库放置在third_party/lib目录中。之后,您应该在MacOS上看到libdawn.dylib或在Linux上看到libdawn.so。此下载仅发生一次。
构建过程本身应该只需要几秒钟。如果构建和执行成功,您应该看到GELU计算的输出:
Hello gpu.cpp!
--------------
gelu(0.00) = 0.00
gelu(0.10) = 0.05
gelu(0.20) = 0.12
gelu(0.30) = 0.19
gelu(0.40) = 0.26
gelu(0.50) = 0.35
gelu(0.60) = 0.44
gelu(0.70) = 0.53
gelu(0.80) = 0.63
gelu(0.90) = 0.73
gelu(1.00) = 0.84
gelu(1.10) = 0.95
...
计算了10000个GELU(x)值
如果需要清理构建产物,可以运行:
make clean
Hello World教程:GELU内核
作为使用gpu.cpp的实际但简单的示例,让我们从神经网络中的一个实用GPU内核开始。
GELU是一种非线性的、高度并行的操作,常用于现代大型语言模型的基于Transformer的架构中。
它接受一个浮点数向量作为输入,并对向量的每个元素应用GELU函数。该函数是非线性的,将小于零的值衰减到接近零,对于大的正值近似于y = x恒等函数。对于接近零的值,GELU在恒等函数和零函数之间平滑插值。
以下GELU代码将说明使用gpu.cpp设置GPU计算的三个主要方面:
-
在GPU上运行的代码(使用WebGPU着色语言,即WGSL),实现计算操作。
-
在CPU上运行的C++代码,通过分配和准备资源来设置GPU计算。为了高性能,这些代码应该在应用程序的热路径之外提前运行。
-
在CPU上运行的C++代码,用于调度GPU计算并检索结果。热路径调度代码的主要关注点是消除或最小化任何不必要的资源分配或数据移动(将这些关注点转移到第2步)。次要考虑是GPU调度是异步的。我们使用标准C++异步原语来管理内核调度的异步方面。
这里是一个GELU内核的实现(基于llm.c中的CUDA实现),作为设备上的WebGPU WGSL代码,并使用gpu.cpp库函数和类型从主机调用。它可以使用标准C++编译器编译(我们推荐使用Clang):
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu; // createContext, createTensor, createKernel,
// dispatchKernel, wait, toCPU Bindings,
// Tensor, Kernel, Context, Shape, kf32
static const char *kGelu = R"(
const GELU_SCALING_FACTOR: f32 = 0.7978845608028654; // sqrt(2.0 / PI)
@group(0) @binding(0) var<storage, read_write> inp: array<{{precision}}>;
@group(0) @binding(1) var<storage, read_write> out: array<{{precision}}>;
@compute @workgroup_size({{workgroupSize}})
fn main(
@builtin(global_invocation_id) GlobalInvocationID: vec3<u32>) {
let i: u32 = GlobalInvocationID.x;
if (i < arrayLength(&inp)) {
let x: f32 = inp[i];
out[i] = select(0.5 * x * (1.0 + tanh(GELU_SCALING_FACTOR
* (x + .044715 * x * x * x))), x, x > 10.0);
}
}
)";
int main(int argc, char **argv) {
Context ctx = createContext();
static constexpr size_t N = 10000;
std::array<float, N> inputArr, outputArr;
for (int i = 0; i < N; ++i) {
inputArr[i] = static_cast<float>(i) / 10.0; // 虚拟输入数据
}
Tensor input = createTensor(ctx, Shape{N}, kf32, inputArr.data());
Tensor output = createTensor(ctx, Shape{N}, kf32);
std::promise<void> promise;
std::future<void> future = promise.get_future();
Kernel op = createKernel(ctx, {kGelu, /* 1-D工作组大小 */ 256, kf32},
Bindings{input, output},
/* 工作组数量 */ {cdiv(N, 256), 1, 1});
dispatchKernel(ctx, op, promise);
wait(ctx, future);
toCPU(ctx, output, outputArr.data(), sizeof(outputArr));
for (int i = 0; i < 16; ++i) {
printf(" gelu(%.2f) = %.2f\n", inputArr[i], outputArr[i]);
}
return 0;
}
在这里我们可以看到GPU代码是用一种称为WGSL(WebGPU着色语言)的领域特定语言编写的。在更大的项目中,你可能会将这些代码存储在单独的文件中,以便在运行时加载(请参阅examples/shadertui,查看实时WGSL代码重新加载的演示)。
main()中的CPU代码设置了GPU计算的主机协调。我们可以将gpu.cpp库的使用看作是一系列GPU名词和动词的集合。
"名词"是由库的类型定义建模的GPU资源,而"动词"是对GPU资源的操作,由库的函数建模。预先资源获取函数以create*为前缀,例如:
createContext()- 构造一个指向GPU设备上下文的引用(Context)。createTensor()- 在GPU上获取一个连续的缓冲区(Tensor)。createKernel()- 构造一个指向GPU计算资源的句柄(Kernel),将着色器代码作为输入,并绑定张量资源。
这些资源获取函数与用于与GPU交互的资源类型相关联:
Context- 用于与GPU设备交互的资源状态的句柄。Tensor- GPU上的数据缓冲区。KernelCode- 可以分派到GPU的WGSL程序的代码。这是WGSL字符串的一个简单封装,还包括代码设计运行的工作组大小。Kernel- 可以分派到GPU的GPU程序。它接受一个KernelCode和一个要绑定的Tensor资源列表用于分派计算。它接受一个Bindings参数,这是一个Tensor实例列表,应该映射到WGSL代码顶部声明的绑定。在这个例子中,有两个绑定,分别对应GPU上的input缓冲区和output缓冲区。
在这个例子中,GELU计算只执行一次,程序立即退出,因此资源准备和分派是并排的。examples/目录中的其他示例说明了如何提前准备资源获取,而分派则发生在热路径中,如渲染、模型推理或模拟循环。
除了create*资源获取函数外,gpu.cpp库中还有一些用于处理向GPU分派执行和数据移动的"动词":
dispatchKernel()- 将Kernel分派到GPU进行计算。这是一个异步操作,立即返回。wait()- 阻塞直到GPU计算完成。这是一个标准的C++ future/promise模式。toCPU()- 将数据从GPU移动到CPU。这是一个同步操作,阻塞直到数据复制完成。toGPU()- 将数据从CPU移动到GPU。这是一个同步操作,阻塞直到数据复制完成。在这个特定的例子中,没有使用toGPU(),因为程序中只有一次从CPU到GPU的数据移动,这发生在调用createTensor()函数时。
这个例子可以在examples/hello_world/run.cpp中找到。
其他示例:矩阵乘法、物理模拟和SDF渲染
你可以探索examples/中的示例项目,这些项目展示了如何将gpu.cpp作为库使用。
在顶级目录中运行make获取预构建的Dawn共享库后,你可以通过导航到每个示例的目录并在该目录中运行make来运行每个示例。
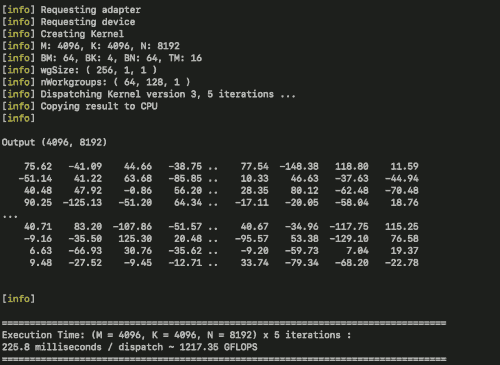
examples/matmul中有一个分块矩阵乘法的例子。这实现了Simon Boehm的文章如何优化CUDA矩阵乘法内核以达到类似cuBLAS的性能:工作日志中前几个内核的WebGPU版本。目前在Macbook Pro M1 Max笔记本上运行速度约为2.5+ TFLOPs,而该设备的理论峰值为10.4 TFLOPs。欢迎贡献以进一步优化。
examples/physics展示了一个并行物理模拟,在GPU上使用不同的初始条件并行模拟一组双摆。

我们还展示了一些有符号距离函数计算的例子,在终端中以ASCII形式渲染。examples/render中展示了球体的3D SDF,而examples/shadertui中展示了类似shadertoy的实时重载示例。
有趣的是,给定一个起始示例,像Claude 3.5 Sonnet这样的LLM在为你编写低级WGSL代码方面相当有能力 - shadertui示例中的其他着色器就是由LLM编写的。
gpu.cpp适合谁?
gpu.cpp旨在为需要可移植的设备上GPU计算的项目提供支持,同时最小化实现复杂性和摩擦。一些使用案例包括:
- 开发在个人计算设备上运行的GPU算法
- 神经网络模型的直接独立实现
- 物理模拟和模拟环境
- 多模态应用 - 音频和视频处理
- 离线图形渲染
- ML推理引擎和运行时
- 并行计算密集型数据处理应用
尽管gpu.cpp适用于任何通用GPU计算,而不仅仅局限于AI,但我们特别感兴趣的一个领域是探索新算法在训练后和设备上计算交叉点的极限。
迄今为止,AI研究主要以CUDA作为特权的一级目标进行构建。CUDA在大规模训练和推理方面一直占据主导地位,但在另一端的个人设备GPU计算世界中,硬件和软件栈存在更多的异构性。
在这个个人设备生态系统中,GPU计算主要局限于少数专家,如游戏引擎开发人员和直接从事ML编译器或推理运行时的工程师。与此同时,直接针对Vulkan甚至WebGPU API的实现往往主要针对基础设施规模的努力 - 游戏引擎、生产ML推理引擎、大型软件包。
我们希望让更广泛的项目能够更容易地利用个人设备上GPU的力量。只需少量代码,我们就能以低级别访问GPU,专注于直接实现算法,而不是围绕GPU的脚手架和技术栈。例如,在我们的AI研究中,有很多关于各种形式的动态/条件训练后计算的探索空间 - 动态使用适配器、稀疏性、模型压缩、实时多模态集成等。
gpu.cpp让我们能够实现和插入任何算法,对数据移动和GPU代码进行精细控制,并探索现有生产导向推理运行时支持范围之外的领域。同时,我们可以编写可移植的代码,可以立即在各种GPU供应商和计算形式上使用 - 工作站、笔记本电脑、移动设备,甚至新兴的硬件平台,如AR/VR和机器人技术。
gpu.cpp不是什么
gpu.cpp适用于对C++和GPU编程有一定熟悉度的开发人员。它不是一个高级数值计算或机器学习框架或推理引擎,尽管它可以用于支持此类实现。
其次,尽管名字如此,WebGPU有与网络和浏览器解耦的原生实现。gpu.cpp首先利用WebGPU作为一个可移植的原生GPU API,未来在浏览器中运行的可能性是一个便利的额外好处。
如果你觉得WebGPU是一种原生技术而不仅仅是用于网络这一点令人困惑,那么请观看Elie Michel的精彩演讲"WebGPU不仅仅关于网络"。
最后,gpu.cpp的重点是通用GPU计算,而不是GPU上的渲染/图形,尽管它可以用于离线渲染或视频处理用例。我们将来可能会探索图形方面的方向,但目前我们的重点是GPU计算。
限制和即将推出的功能
API改进 - gpu.cpp还在开发中,还有许多功能和改进有待推出。在这个早期阶段,我们预计API设计将随着我们从用例中识别改进/需求而不断发展。特别是,结构化参数的处理和异步分派在短期内将会经历完善和成熟。 浏览器目标 - 尽管使用了WebGPU,但我们还没有测试针对浏览器的构建,不过这是短期的优先事项。
可重用内核库 - 目前,核心库严格限于用于与WebGPU API接口的操作和类型,在examples/中有一些特定用例的WGSL实现示例。随着时间推移,当内核实现成熟后,我们可能会将一些可重用的操作从特定示例迁移到一个小型的可重用内核库中。
更多用例示例和测试 - 预计会有一个用例迭代循环,以设计调整和改进,这反过来会使用例更加清晰和易于编写。一个短期用例是以WebGPU形式充实llm.c中的内核。随着这些成熟为可重用的内核库,我们希望帮助实现WebGPU计算在AI中的潜力。
故障排除
如果您在构建项目时遇到问题,请开一个issue。
致谢
gpu.cpp使用了:
- Dawn作为WebGPU实现
- @jspanchu的webgpu-dawn-binaries来构建Dawn的二进制制品
- @eliemichel的webgpu-distribution用于cmake构建
也感谢Answer.AI团队的同事们提供的支持、测试帮助和反馈。
Discord社区和贡献
加入我们在AnswerDotAI Discord的#gpu-cpp频道。也欢迎通过X @austinvhuang联系。
欢迎反馈、提出问题和提交拉取请求。
贡献者代码指南
对于贡献者,以下是关于gpu.cpp库设计和风格的一般经验法则:
美学 - 最大化杠杆作用并考虑摩擦源:
- 除了性能外,理解代码库的时间、编译时间、构建失败模式的数量都是值得优化的。
- 只有在有明确目标的情况下才增加实现的表面积。这可以最大化每单位努力的杠杆作用,增加库使用方式的选择性,并保持编译时间较短。
- 借鉴经过时间考验的神经网络库(如PyTorch)的水平可扩展性,可以将库架构大致描述为一袋可组合的函数。
- 设计选择通常试图将函数式编程的可组合性与面向数据设计的性能意识相结合。
重载和模板:
- 对于核心实现代码,优先使用值级类型而不是类型级模板。在值类型核心实现的基础上添加一个更类型安全的模板包装器很容易。而将模板化的核心实现从编译时移到运行时会导致更重大的重构。
- 对于编译时多态,优先使用简单的函数重载而不是模板。除了编译时间的好处外,这使得推理正在调用哪个版本的函数变得明确且可在代码库中扫描。
避免封装和方法:
- 为了有效地构建系统,我们需要用行为已知的子系统来构建它们,从而使其可组合和可预测。因此,我们更喜欢透明性,避免封装。不要使用抽象类作为接口规范,库及其函数签名就是接口。
- 除非有明确的理由,否则默认使用struct而不是class。
- 不使用方法,而是将"拥有对象"的对象作为引用传递给函数。通常,这种约定可以执行方法可以执行的任何操作,但更灵活,耦合度更低。使用可变函数更容易推广到对多个参数有副作用的操作,而方法则优先考虑拥有类,将单变量情况视为特殊情况,使其更难推广到多个参数。
- 方法通常只用于构造函数/析构函数/运算符等特权情况。
- 对于请求GPU资源和更复杂的初始化操作,使用遵循
create[X]约定的工厂函数 - createTensor、createKernel、createContext等。 - 对简单的支持类型使用(尽可能简单的)构造函数(主要为调度提供元数据)Shape、KernelCode等。
所有权:
- 优先使用栈分配进行所有权管理,当需要堆时使用unique_ptr。仅将原始指针用于非拥有视图。除非有明确的共享所有权理由,否则避免使用shared_ptr。
- 使用池作为管理资源集的单一控制点。如果资源对整个API来说足够通用,可以考虑将池合并到Context中。
将资源获取与热路径分离:
- 通常,资源获取应该在应用程序的热路径之前完成。这是为了确保热路径尽可能快,不必处理资源分配或数据移动。
- API中的操作应该考虑到特定用途来实现 - 通常是提前准备/获取资源、热路径或非关键的测试/可观察性代码。











