
Agent-FLAN: 为大型语言模型设计有效的代理调优数据和方法



✨ 介绍
[🤗 HuggingFace] [🧰 OpenXLab] [📃 论文] [🌐 项目页面 ]
开源的大型语言模型(LLM)在各种自然语言处理任务中取得了巨大的成功,然而在作为代理时,它们仍远不如基于API的模型。如何将代理能力整合到通用LLM中成为一个关键且紧迫的问题。本文首先提出了三点关键观察:(1) 目前的代理训练语料库同时包含了格式遵循和代理推理,这与其预训练数据的分布有显著偏离;(2) LLM在不同代理任务所需能力上的学习速度不同;(3) 目前的方法在通过引入幻觉来提高代理能力时存在副作用。基于以上发现,我们提出了Agent-FLAN以有效地微调语言模型用于代理。通过对训练语料的仔细分解和重新设计,Agent-FLAN使Llama2-7B在各种代理评估数据集上超过了之前最好的工作3.5%。通过全面构建负样本,Agent-FLAN基于我们建立的评估基准大大缓解了幻觉问题。此外,在扩展模型规模时,它持续提升了LLM的代理能力,同时略微增强了LLM的通用能力。
🚀 更新内容
- [2024.3.21] 论文已在 ArXiv 上发布。🔥🔥🔥
- [2024.3.20] 发布了Agent-FLAN的数据集和模型检查点。🎉🎉🎉
♟️ Agent-FLAN
Agent-FLAN系列通过在AgentInstruct和Toolbench上应用Agent-FLAN论文中提出的数据生成流水线进行微调,在各种代理任务和工具使用方面展现出强大的能力~
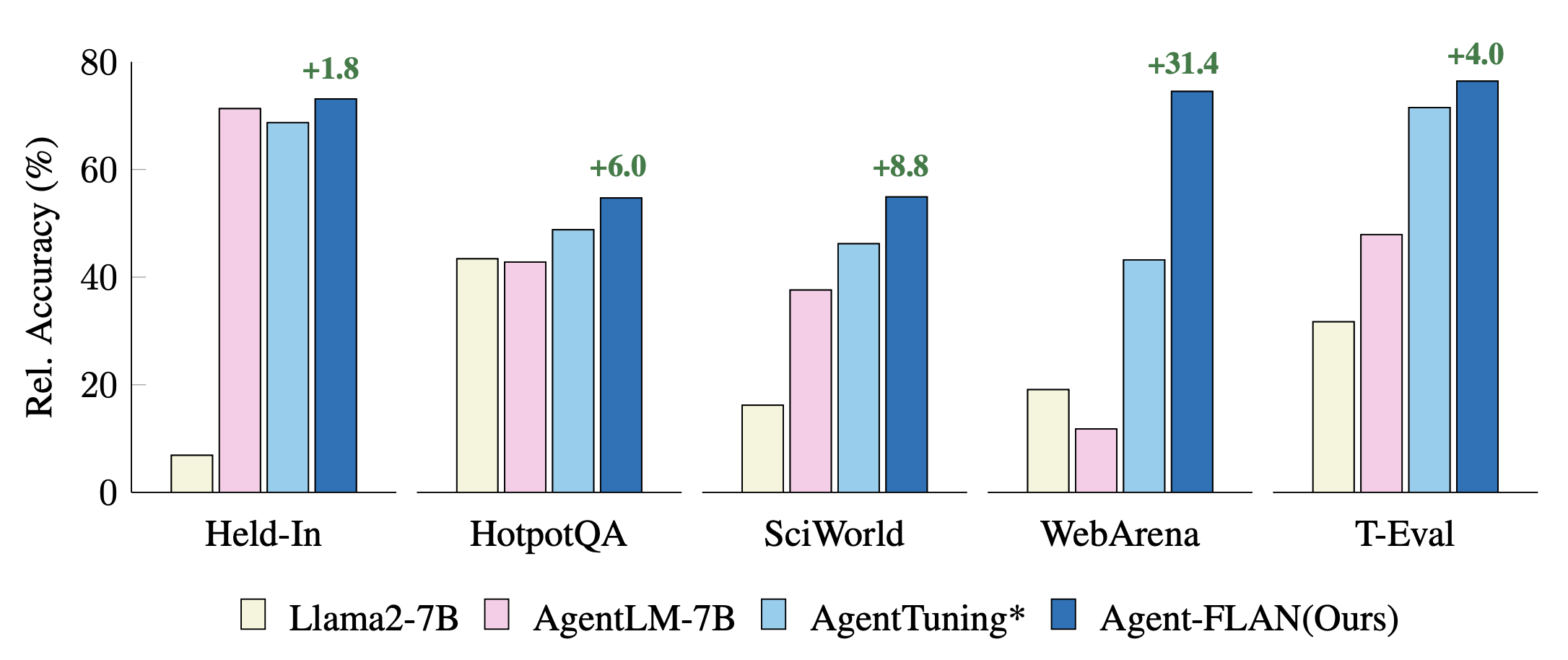
最近代理调优方法在Held-In和Held-Out任务上的比较。性能用GPT-4结果进行标准化以便更好地可视化。*表示我们的重新实现以便公平比较。
🤗 HuggingFace模型及数据集
Agent-FLAN是通过混合训练AgentInstruct、ToolBench和ShareGPT数据集中的Llama2-chat系列产生的。
这些模型遵循Llama-2-chat的对话格式,模板协议如下:
dict(role='user', begin='<|Human|>', end='\n '),
dict(role='system', begin='<|Human|>', end='\n '),
dict(role='assistant', begin='<|Assistant|>', end='\n '),
7B模型可在Huggingface和OpenXLab模型中心获取。
Agent-FLAN数据集亦可在Huggingface数据集中心获取。
| 数据集 | Huggingface仓库 |
|---|---|
| Agent-FLAN | 数据集链接 |
💫 详细结果

Agent-FLAN的主要结果。Agent-FLAN在Held-In和Held-Out任务上显著优于之前的代理调优方法。*表示我们使用相同量的训练数据重新实现以便公平比较。由于FireAct未在AgentInstruct数据集上训练,我们省略其在HELD-IN集合上的表现。粗体:API-based和开源模型中表现最好的。
❤️ 致谢
Agent-FLAN是基于Lagent和T-Eval构建的。感谢他们出色的工作!
🖊️ 引用
如果您觉得这个项目对您的研究有帮助,请考虑引用:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
💳 许可证
该项目已根据Apache 2.0 许可证发布。











