
 Github
Github Huggingface
Huggingface介绍Whisper-TikTok 🤖🎥
Star历史
目录
简介
Whisper-TikTok是一款创新的AI驱动工具,它利用Edge TTS、OpenAI-Whisper和FFMPEG的强大功能来制作引人入胜的TikTok视频。借助OpenAI的Whisper模型,Whisper-TikTok可以轻松地从提供的音频文件中生成准确的转录文本,为通过FFMPEG创建引人入胜的TikTok视频奠定基础。此外,该程序无缝集成了Microsoft Edge Cloud文本转语音(TTS) API,为视频配上生动的画外音。选择Microsoft Edge Cloud TTS API的画外音是经过深思熟虑的,因为它能提供remarkably自然真实的听觉体验,这与许多TikTok视频中常见的单调人工画外音形成鲜明对比。
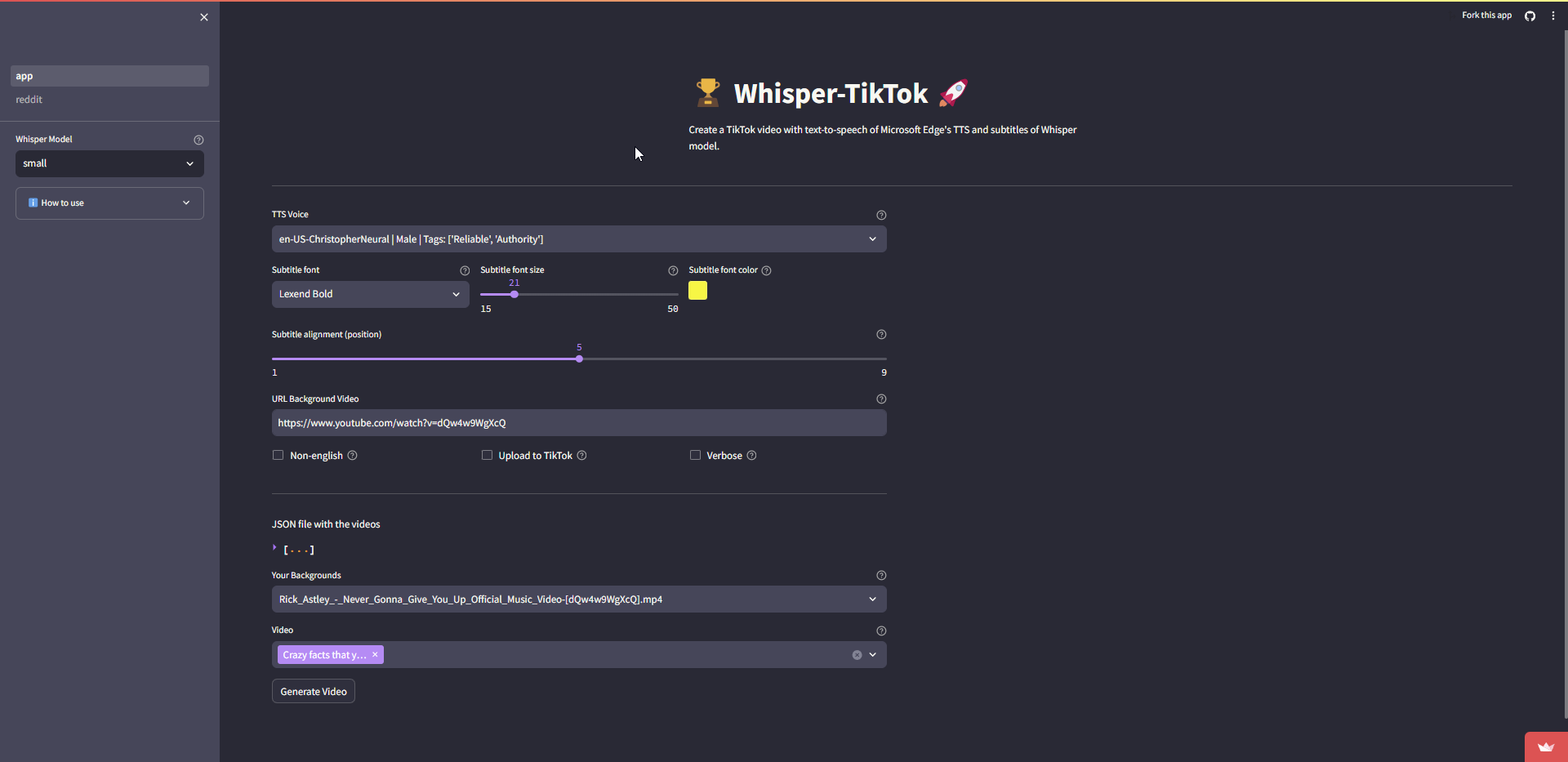
Streamlit网页应用
视频演示
https://github.com/MatteoFasulo/Whisper-TikTok/assets/74818541/68e25504-c305-4144-bd39-c9acc218c3a4
工作原理
使用Whisper-TikTok非常简单:只需修改video.json文件。JSON文件包含以下字段:
series:系列名称。part:视频的部分编号。text:视频中要朗读的文本。outro:视频中要朗读的结束语。tags:用于视频的标签。
程序功能概述:
提供包含系列名称、视频部分编号、视频文本和结束语等详细信息的结构化JSON数据集后,程序会编排合成一个包含所提供文本和结束语的视频。随后,生成的视频将存储在指定的
output文件夹中。
详细信息
该程序执行以下操作顺序:
- 从可选的.env文件中检索环境变量。
- 验证是否安装了具有CUDA功能的PyTorch。如果缺少必需的依赖项,程序将使用CPU而不是GPU。
- 从YouTube等平台下载随机视频,例如Minecraft跑酷游戏片段。
- 将OpenAI Whisper模型加载到内存中。
- 从提供的JSON文件中提取视频文本,并向Microsoft Edge Cloud TTS API发起文本转语音请求,将响应保存为.mp3音频文件。
- 使用OpenAI Whisper模型为.mp3文件生成详细的**.srt格式转录文本**。
- 从专用文件夹中选择一个随机背景视频。
- 使用FFMPEG将srt文件集成到所选视频中,创建最终的.mp4输出。
- 使用TikTok会话cookie将视频上传到TikTok。这一步需要有TikTok账号并在浏览器中登录。然后可以使用这里提供的指南生成所需的
cookies.txt文件。cookies.txt文件必须放在项目的根文件夹中。 - 瞧!几分钟内,你就在品尝最喜欢的咖啡☕️的同时制作出了一个引人入胜的TikTok视频。
在线网页应用
有一个由Streamlit托管的网页应用,可在HuggingFace上公开使用,只需点击链接即可直接进入网页应用。
https://huggingface.co/spaces/MatteoFasulo/Whisper-TikTok-Demo
本地安装
Whisper-TikTok已在配备Python 3.8、3.9和3.11版本的Windows 10、Windows 11和Ubuntu 23.04系统上进行了严格测试。
如果你想在本地运行Whisper-TikTok,可以使用以下命令克隆仓库:
git clone https://github.com/MatteoFasulo/Whisper-TikTok.git
不过,Whisper-TikTok也提供了Docker镜像,可用于在容器化环境中运行程序。
依赖项
要简化必要依赖项的安装,请在终端中执行以下命令:
pip install -U -r requirements.txt
它还需要在系统上安装命令行工具FFMPEG,大多数包管理器都可以使用:
# Ubuntu或Debian系统
sudo apt update && sudo apt install ffmpeg
# Arch Linux系统
sudo pacman -S ffmpeg
# 在MacOS上使用Homebrew(<https://brew.sh/>)
brew install ffmpeg
# 在Windows上使用Chocolatey(<https://chocolatey.org/>)
choco install ffmpeg
# 在Windows上使用Scoop(<https://scoop.sh/>)
scoop install ffmpeg
请注意,为获得最佳性能,使用OpenAI Whisper模型进行语音识别时建议使用GPU。但是,即使没有GPU程序也能工作,只是运行速度会较慢。这种性能差异是因为GPU可以高效处理fp16计算,而CPU使用的是较慢的fp32或fp64(取决于你的机器)。
本地Web界面
要在本地运行Web界面,请在终端中执行以下命令:
streamlit run app.py --server.port=8501 --server.address=0.0.0.0
命令行
要从命令行运行程序,请在终端中执行以下命令:
python main.py
CLI选项
Whisper-TikTok支持以下命令行选项:
python main.py [选项]
选项:
--model TEXT 要使用的模型 [tiny|base|small|medium|large](默认:small)
--non_english 使用通用模型,而不是专门的英语模型。(标志)
--url TEXT 要下载作为背景视频的YouTube URL。(默认:https://www.youtube.com/watch?v=intRX7BRA90)
--tts TEXT 用于TTS的语音(默认:en-US-ChristopherNeural)
--list-voices 使用edge-tts --list-voices列出所有语音。
--random_voice 随机TTS语音(标志)
--gender TEXT 随机TTS语音的性别 [Male|Female]。
--language TEXT 随机TTS语音的语言(例如,en-US)
--sub_format TEXT 要使用的字幕格式 [u|i|b](默认:b)| b(粗体),u(下划线),i(斜体)
--sub_position INT 要使用的字幕位置 [1-9](默认:5)
--font TEXT 用于字幕的字体(默认:Lexend Bold)
--font_color TEXT 用于字幕的字体颜色,采用HEX格式(默认:#FFF000)。
--font_size INT 用于字幕的字体大小(默认:21)
--max_characters INT 每行最大字符数(默认:38)
--max_words INT 每段最大单词数(默认:2)
--upload_tiktok 将视频上传到TikTok(标志)
-v, --verbose 详细模式(标志)
如果使用--random_voice选项,请同时指定--gender和--language参数。此外,如果要使用非英语语音,还需要指定--non_english参数,否则程序将使用英语模型。Whisper模型将自动检测音频文件的语言并使用相应的模型。
使用示例
- 使用特定的TTS模型和语音生成TikTok视频:
python main.py --model medium --tts en-US-EricNeural
- 生成TikTok视频而不使用英语模型:
python main.py --non_english --tts de-DE-KillianNeural
- 使用自定义YouTube视频作为背景视频:
python main.py --url https://www.youtube.com/watch?v=dQw4w9WgXcQ --tts en-US-JennyNeural
- 修改字幕的字体颜色:
python main.py --sub_format b --font_color #FFF000 --tts en-US-JennyNeural
- 使用随机TTS语音生成TikTok视频:
python main.py --random_voice --gender Male --language en-US
- 列出所有可用的语音:
edge-tts --list-voices
额外资源
加速视频创作
由@duozokker贡献
reddit2json是一个Python脚本,可以将Reddit帖子URL转换为JSON文件,简化了创建video.json文件的过程。这个工具不仅可以转换Reddit链接,还提供了使用DeepL翻译Reddit帖子内容和通过自定义OpenAI GPT调用修改内容等功能。
reddit2json:直接将Reddit链接转换为JSON
reddit2json旨在处理Reddit帖子URL列表,将它们转换为可直接用于视频创作的JSON格式。这个工具通过提供更快速、更高效的方式生成video.json文件,提升了视频创作过程。
这里是reddit2json的详细README,其中包括安装说明、设置.env文件、示例调用等更多信息。
行为准则
在为Whisper-TikTok做出贡献之前,请查看我们的行为准则。
贡献
我们欢迎社区的贡献!请查看我们的贡献指南以获取更多信息。
即将推出的功能
- 与OpenAI API集成,以生成更高级的响应。
- 通过从reddit提取内容生成内容 https://github.com/MatteoFasulo/Whisper-TikTok/issues/22
致谢
- 我们要特别感谢@rany2提供的edge-tts包,它使得Whisper-TikTok能够使用Microsoft Edge Cloud TTS API。
- 我们也要感谢@OpenAI的Whisper模型在大规模弱监督下实现了强大的语音识别功能。
- 还要感谢@jianfch提供的stable-ts包,它使得Whisper-TikTok能够以稳定的方式使用OpenAI Whisper模型,并提供字体颜色和字幕格式选项。
许可证
Whisper-TikTok使用Apache License, Version 2.0许可。











