
 Github
Github Huggingface
Huggingface 论文
论文:snake:VideoMamba
更新
- :warning: 2024/03/25:
由于bug,当前的视频模型在微调时未使用层衰减,这可能有助于提高性能,如MAE中所示。我们已修复该bug,但不打算重新训练它们。我们已将其应用于VideoMamba-M,但并未带来改善。 - 2024/03/13: 修复一些bug并添加:hugs:HuggingFace模型链接。
- :fire: 2024/03/12: 所有代码和模型已发布。
简介
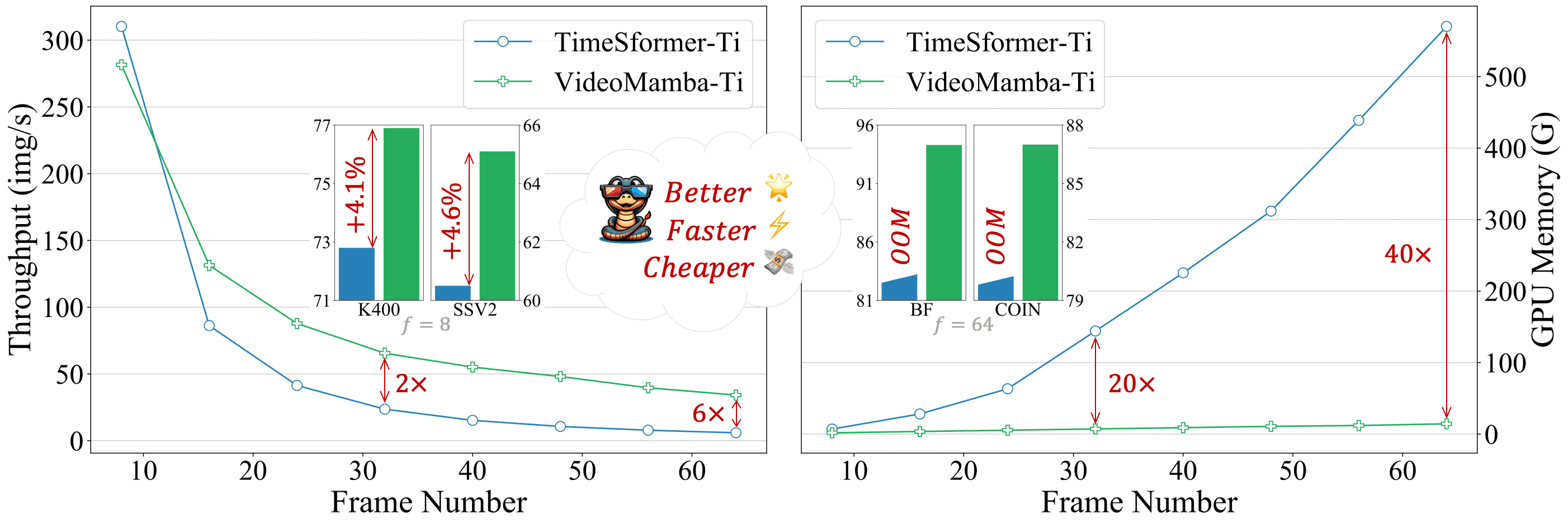
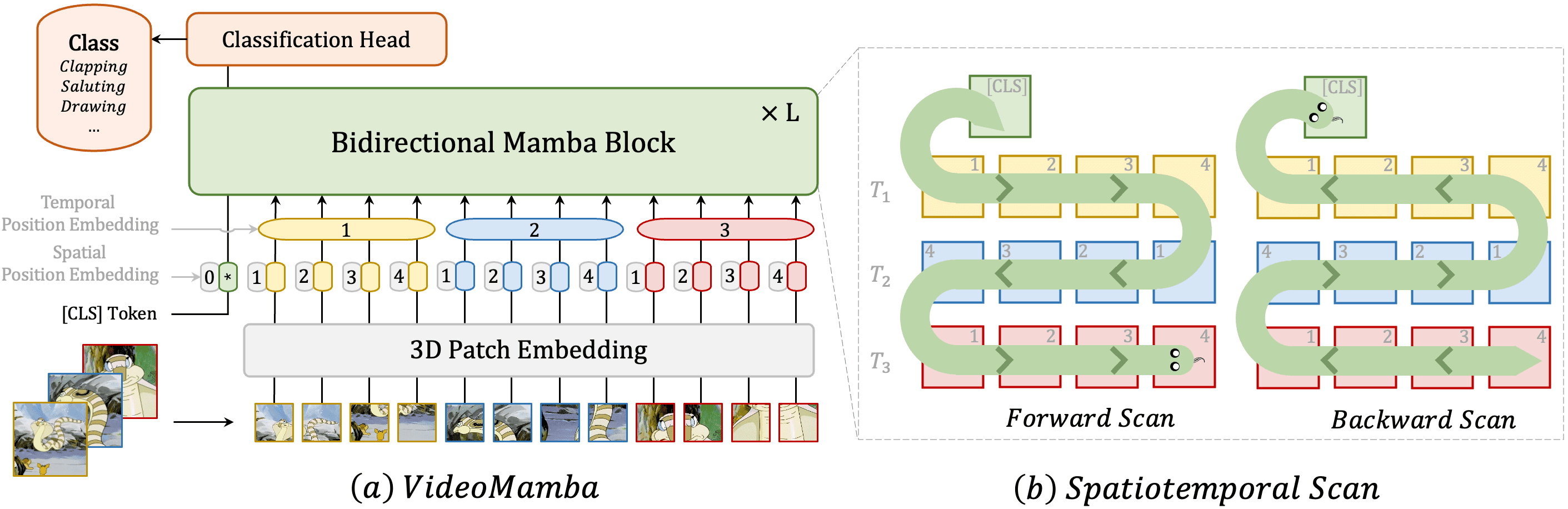 本工作针对视频理解中的局部冗余和全局依赖双重挑战,创新性地将Mamba适配到视频领域。提出的VideoMamba克服了现有3D卷积神经网络和视频Transformer的局限性。其线性复杂度算子能够实现高效的长期建模,这对于高分辨率长视频理解至关重要。广泛的评估揭示了VideoMamba的四个核心能力:(1) 无需大规模数据集预训练即可在视觉领域实现可扩展性,这得益于一种新颖的自蒸馏技术;(2) 对短期动作识别的敏感性,即使面对细粒度的运动差异;(3) 在长期视频理解方面的优越性,相比传统基于特征的模型展现出显著进步;(4) 与其他模态的兼容性,在多模态环境中表现出稳健性。通过这些独特优势,VideoMamba为视频理解树立了新的标杆,为全面的视频理解提供了一个可扩展且高效的解决方案。
本工作针对视频理解中的局部冗余和全局依赖双重挑战,创新性地将Mamba适配到视频领域。提出的VideoMamba克服了现有3D卷积神经网络和视频Transformer的局限性。其线性复杂度算子能够实现高效的长期建模,这对于高分辨率长视频理解至关重要。广泛的评估揭示了VideoMamba的四个核心能力:(1) 无需大规模数据集预训练即可在视觉领域实现可扩展性,这得益于一种新颖的自蒸馏技术;(2) 对短期动作识别的敏感性,即使面对细粒度的运动差异;(3) 在长期视频理解方面的优越性,相比传统基于特征的模型展现出显著进步;(4) 与其他模态的兼容性,在多模态环境中表现出稳健性。通过这些独特优势,VideoMamba为视频理解树立了新的标杆,为全面的视频理解提供了一个可扩展且高效的解决方案。
引用
如果您发现本仓库有用,请使用以下BibTeX条目进行引用。
@misc{li2024videomamba,
title={VideoMamba: State Space Model for Efficient Video Understanding},
author={Kunchang Li and Xinhao Li and Yi Wang and Yinan He and Yali Wang and Limin Wang and Yu Qiao},
year={2024},
eprint={2403.06977},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
许可证
本项目采用Apache 2.0许可证发布
致谢
本仓库基于UniFormer、Unmasked Teacher和Vim仓库构建。











