

🤗 Hugging Face | 🤖 ModelScope | 📑 博客 | 📖 文档
🖥️ 演示 | 💬 微信 | 🫨 Discord
访问我们的Hugging Face或ModelScope组织(点击上方链接),搜索以CodeQwen1.5-开头的检查点,您就能找到所需的一切!尽情使用吧!
简介
CodeQwen1.5是Qwen1.5的代码特定版本。它是一个基于transformer的仅解码器语言模型,在大量代码数据上进行预训练。
- ✨ 强大的代码生成能力,在一系列基准测试中表现出色;
- ✨ 支持长上下文理解和生成,上下文长度为64K个token;
- ✨ 支持92种编程语言;
['ada', 'agda', 'alloy', 'antlr', 'applescript', 'assembly', 'augeas', 'awk', 'batchfile', 'bluespec', 'c', 'c#', 'c++', 'clojure', 'cmake', 'coffeescript', 'common-lisp', 'css', 'cuda', 'dart', 'dockerfile', 'elixir', 'elm', 'emacs-lisp', 'erlang', 'f#', 'fortran', 'glsl', 'go', 'groovy', 'haskell', 'html', 'idris', 'isabelle', 'java', 'java-server-pages', 'javascript', 'json', 'julia', 'jupyter-notebook', 'kotlin', 'lean', 'literate-agda', 'literate-coffeescript', 'literate-haskell', 'lua', 'makefile', 'maple', 'markdown', 'mathematica', 'matlab', 'objectc++', 'ocaml', 'pascal', 'perl', 'php', 'powershell', 'prolog', 'protocol-buffer', 'python', 'r', 'racket', 'restructuredtext', 'rmarkdown', 'ruby', 'rust', 'sas', 'scala', 'scheme', 'shell', 'smalltalk', 'solidity', 'sparql', 'sql', 'stan', 'standard-ml', 'stata', 'swift', 'systemverilog', 'tcl', 'tcsh', 'tex', 'thrift', 'typescript', 'verilog', 'vhdl', 'visual-basic', 'vue', 'xslt', 'yacc', 'yaml', 'zig']
- ✨ 在文本到SQL转换、bug修复等方面表现出色。
详细性能和介绍请参阅此 📑 博客。
要求
python>=3.9transformers>=4.37.0,用于Qwen1.5密集模型。
[!警告]
🚨 这是必须的,因为`transformers`从`4.37.0`版本开始集成了Qwen2的代码。
您可以使用以下命令安装所需的包:
pip install -r requirements.txt
快速开始
[!重要]
CodeQwen1.5-7B-Chat 是用于聊天的指令模型;
CodeQwen1.5-7B 是基础模型,通常用于补全任务,是微调的更好起点。
👉🏻 与CodeQwen1.5-7B-Chat聊天
您只需使用transformers编写几行代码就可以与CodeQwen1.5-7B-Chat进行聊天。本质上,我们使用from_pretrained方法构建tokenizer和模型,并利用tokenizer提供的聊天模板使用generate方法进行聊天。以下是如何与CodeQwen1.5-7B-Chat聊天的示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # 加载模型的设备
# 现在您不需要添加"trust_remote_code=True"
tokenizer = AutoTokenizer.from_pretrained("Qwen/CodeQwen1.5-7B-Chat")
model = AutoModelForCausalLM.from_pretrained("Qwen/CodeQwen1.5-7B-Chat", device_map="auto").eval()
# 将输入标记化为tokens
# 我们直接使用model.generate(),而不是model.chat()
# 但您需要使用tokenizer.apply_chat_template()来格式化输入,如下所示
prompt = "写一个快速排序算法。"
messages = [
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 直接使用generate()和tokenizer.decode()获取输出。
# 使用`max_new_tokens`控制最大输出长度。
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2048
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
apply_chat_template()函数用于将消息转换为模型可以理解的格式。add_generation_prompt参数用于添加生成提示,即<|im_start|>assistant\n到输入中。值得注意的是,我们按照之前的做法为聊天模型应用ChatML模板。max_new_tokens参数用于设置响应的最大长度。tokenizer.batch_decode()函数用于解码响应。在输入方面,上述消息是一个示例,展示了如何格式化对话历史和系统提示。
👉🏻 使用CodeQwen1.5-7B-Base的代码
1. 基本用法
模型根据给定的提示完成代码片段,不进行任何额外的格式化,这通常在代码生成任务中称为"代码补全"。
本质上,我们使用from_pretrained方法构建分词器和模型,并使用generate方法执行代码补全。以下是如何与CodeQwen1.5-base进行对话的示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # 加载模型的设备
# 现在不需要添加"trust_remote_code=True"
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/CodeQwen1.5-7B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/CodeQwen1.5-7B", device_map="auto").eval()
# 将输入文本分词
input_text = "#编写一个快速排序算法"
model_inputs = TOKENIZER([input_text], return_tensors="pt").to(device)
# 使用`max_new_tokens`控制最大输出长度
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=False)[0]
# generated_ids包含prompt_ids,所以我们只需要解码prompt_ids之后的令牌
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)
print(f"提示:{input_text}\n\n生成的文本:{output_text}")
max_new_tokens参数用于设置响应的最大长度。
input_text可以是任何你希望模型继续的文本。
2. 文件级代码补全(填充中间)
代码插入任务,也称为"填充中间"挑战,要求以桥接给定代码上下文中的空白的方式插入代码段。
为了遵循最佳实践,我们建议遵循"Efficient Training of Language Models to Fill in the Middle"论文中概述的格式指南。这涉及使用三个专用标记<fim_prefix>、<fim_suffix>和<fim_middle>来表示代码结构的相应部分。
提示应按如下方式构建:
prompt = '<fim_prefix>' + prefix_code + '<fim_suffix>' + suffix_code + '<fim_middle>'
按照上述方法,一个示例将如下构建:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型
device = "cuda" # 加载模型的设备
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/CodeQwen1.5-7B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/CodeQwen1.5-7B", device_map="auto").eval()
input_text = """<fim_prefix>def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
<fim_suffix>
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)<fim_middle>"""
model_inputs = TOKENIZER([input_text], return_tensors="pt").to(device)
# 使用`max_new_tokens`控制最大输出长度
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=False)[0]
# generated_ids包含prompt_ids,我们只需要解码prompt_ids之后的令牌
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)
print(f"提示:{input_text}\n\n生成的文本:{output_text}")
3. 仓库级代码补全
仓库级代码补全任务涉及向模型提供来自同一仓库的多个文件的内容。这使模型能够理解这些文件中不同调用之间的相互关系,从而促进代码内容的补全。
我们建议使用两个特殊标记<reponame>和<file_sep>来指示仓库结构。
例如,假设仓库名称存储在repo_name中,它包含的文件及其各自的路径和内容列为[(file_path1, file_content1), (file_path2, file_content2)],最终输入提示的格式将如下:
input_text = f'''<reponame>{repo_name}
<file_sep>{file_path1}
{file_content1}
<file_sep>{file_path2}
{file_content2}'''
👇🏻 以下是仓库级代码补全任务的完整示例::: 点击展开 ::
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # 加载模型的设备
# 现在不需要添加"trust_remote_code=True"
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/CodeQwen1.5-7B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/CodeQwen1.5-7B", device_map="auto").eval()
# 将输入文本分词
input_text = """<reponame>library-system
<file_sep>library.py
class Book:
def __init__(self, title, author, isbn, copies):
self.title = title
self.author = author
self.isbn = isbn
self.copies = copies
def __str__(self):
return f"Title: {self.title}, Author: {self.author}, ISBN: {self.isbn}, Copies: {self.copies}"
class Library:
def __init__(self):
self.books = []
def add_book(self, title, author, isbn, copies):
book = Book(title, author, isbn, copies)
self.books.append(book)
def find_book(self, isbn):
for book in self.books:
if book.isbn == isbn:
return book
return None
def list_books(self):
return self.books
<file_sep>student.py
class Student:
def __init__(self, name, id):
self.name = name
self.id = id
self.borrowed_books = []
def borrow_book(self, book, library):
if book and book.copies > 0:
self.borrowed_books.append(book)
book.copies -= 1
return True
return False
def return_book(self, book, library): if book in self.borrowed_books: self.borrowed_books.remove(book) book.copies += 1 return True return False
<file_sep>main.py from library import Library from student import Student
def main(): # 设置图书馆并添加一些书籍 library = Library() library.add_book("了不起的盖茨比", "F·斯科特·菲茨杰拉德", "1234567890", 3) library.add_book("杀死一只知更鸟", "哈珀·李", "1234567891", 2)
# 设置一个学生
student = Student("爱丽丝", "S1")
# 学生借书
book = library.find_book("1234567890")
if student.borrow_book(book, library):
print(f"{student.name}借了{book.title}")
else:
print(f"{student.name}无法借到{book.title}")
# 学生还书
if student.return_book(book, library):
print(f"{student.name}归还了{book.title}")
else:
print(f"{student.name}无法归还{book.title}")
# 列出图书馆所有的书
print("图书馆所有的书:")
for book in library.list_books():
print(book)
if name == "main": main()
👉🏻 使用vLLM部署CodeQwen
作为Qwen1.5家族的一员,CodeQwen1.5受vLLM支持。详细教程可以在Qwen教程中找到。 这里,我们给你一个使用vLLM进行离线批处理推理的简单示例。
离线批处理推理
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# 初始化分词器
tokenizer = AutoTokenizer.from_pretrained("Qwen/CodeQwen1.5-7B")
# 传递Qwen1.5-7B-Chat的默认解码超参数
# max_tokens用于设置生成的最大长度。
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=1024)
# 输入模型名称或路径。可以是GPTQ或AWQ模型。
llm = LLM(model="Qwen/CodeQwen1.5-7B")
# 准备你的提示
prompt = "#write a quick sort algorithm.\ndef quick_sort("
# 生成输出
outputs = llm.generate([prompt], sampling_params)
# 打印输出
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"提示: {prompt!r}, 生成的文本: {generated_text!r}")
多GPU分布式服务
为了提高服务的吞吐量,分布式服务通过利用更多的GPU设备来帮助你。
当使用超长序列进行推理时,可能会导致GPU内存不足。在这里,我们演示如何通过传入参数tensor_parallel_size来运行CodeQwen1.5-7B的张量并行。
llm = LLM(model="Qwen/CodeQwen1.5-7B", tensor_parallel_size=4)
性能
EvalPlus (HumanEval, MBPP)
我们建议使用EvalPlus来评估HumaneEval和MBPP的效果。这里是我们的评估脚本。
| 模型 | 大小 |
HumanEval
零样本
|
HumanEval+
零样本
|
MBPP
零样本
|
MBPP+
零样本
|
MBPP
三样本
|
| CodeLlama-Base | 7B | 33.5 | 25.6 | 52.1 | 41.6 | 38.6 |
| StarCoder2 | 7B | 35.4 | 29.9 | 54.4 | 45.6 | 51.0 |
| DeepSeek-Coder-Base | 6.7B | 47.6 | 39.6 | 70.2 | 56.6 | 60.6 |
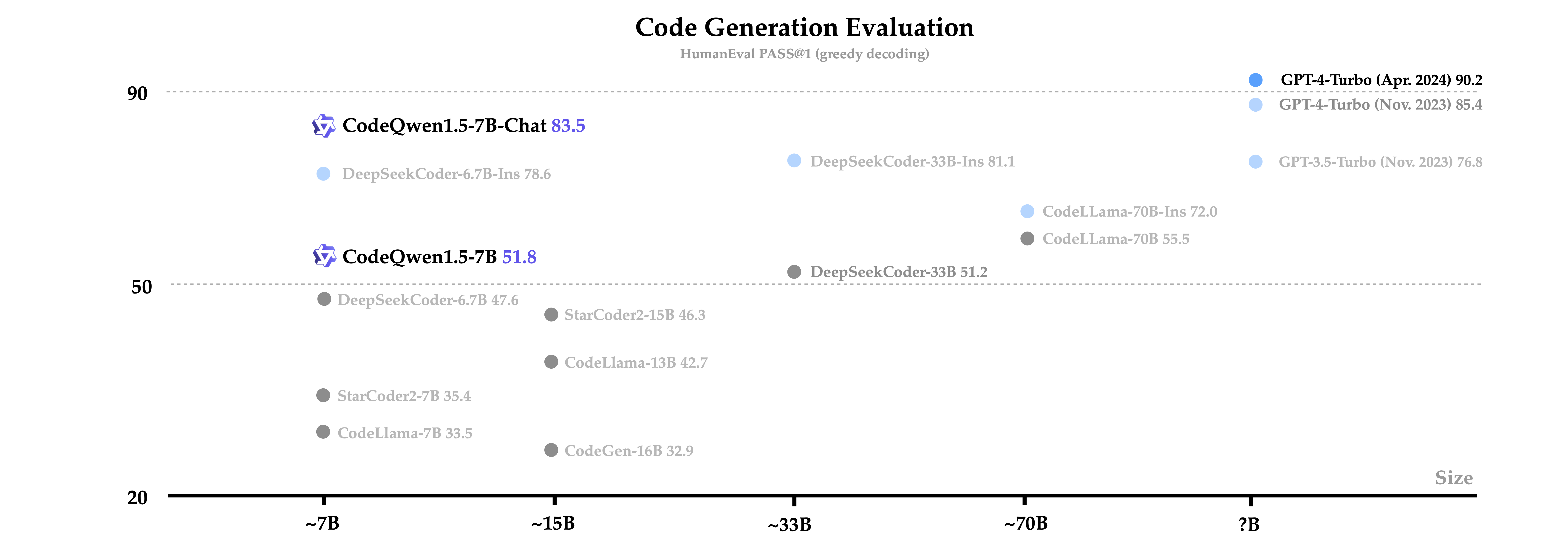
| CodeQwen1.5 | 7B | 51.8 | 45.7 | 72.2 | 60.2 | 61.8 |
| GPT-3.5-Turbo | - | 76.8 | 70.7 | 82.5 | 69.7 | 70.8 |
| GPT-4-Turbo(2023年11月) | - | 85.4 | 81.7 | 83.5 | 70.7 | 80.0 |
| DeepSeek-Coder-Instruct | 6.7B | 73.8 | 70.1 | 73.2 | 63.4 | 65.4 |
| CodeQwen1.5-Chat | 7B | 83.5 | 78.7 | 77.7 | 67.2 | 70.6 |
LiveCodeBench
LiveCodeBench提供了对大语言模型编码能力的全面且无污染的评估。特别是,LiveCodeBench持续从LeetCode、AtCoder和CodeForces三个竞赛平台收集新的问题。 这里是我们的评估脚本。
| 模型 | 规模 |
代码生成
全时段
Pass@1
|
代码生成
2023/9/1 ~ 2024/4/1
Pass@1
|
| CodeLlama-Base | 7B | 6.5 | 7.6 |
| StarCoder2 | 7B | 11.3 | 12.7 |
| DeepSeek-Coder-Base | 6.7B | 19.1 | 13.7 |
| CodeQwen1.5 | 7B | 21.8 | 19.3 |
| CodeLlama-Instruct | 7B | 10.6 | 12.4 |
| DeepSeek-Coder-Instruct | 6.7B | 21.6 | 19.2 |
| CodeQwen1.5-Chat | 7B | 25.0 | 23.2 |
MultiPL-E
MultiPL-E是一个用于评估多种编程语言的流行基准测试。 您可以在这里找到我们的复现过程。
| 模型 | 规模 | Python | C++ | Java | PHP | TS | C# | Bash | JS | 平均 |
| 基础模型 | ||||||||||
| CodeLlama-Base | 7B | 31.7 | 29.8 | 34.2 | 23.6 | 36.5 | 36.7 | 12.0 | 29.2 | 29.2 |
| StarCoder2-Base | 7B | 35.3 | 40.9 | 37.3 | 29.2 | 37.7 | 40.5 | 9.4 | 36.0 | 33.3 |
| DeepSeek-Coder-Base | 6.7B | 49.4 | 50.3 | 43.0 | 38.5 | 49.7 | 50.0 | 28.5 | 48.4 | 44.7 |
| CodeQwen1.5 | 7B | 52.4 | 52.2 | 42.4 | 46.6 | 52.2 | 55.7 | 36.7 | 49.7 | 48.5 |
| 对话模型 | ||||||||||
| GPT-3.5-Turbo | - | 76.2 | 63.4 | 69.2 | 60.9 | 69.1 | 70.8 | 42.4 | 67.1 | 64.9 |
| GPT-4 | - | 84.1 | 76.4 | 81.6 | 77.2 | 77.4 | 79.1 | 58.2 | 78.0 | 76.5 |
| DeepSeek-Coder-Instruct | 6.7B | 78.6 | 63.4 | 68.4 | 68.9 | 67.2 | 72.8 | 36.7 | 72.7 | 66.1 |
| CodeQwen1.5-Chat | 7B | 83.2 | 71.2 | 70.1 | 73.5 | 75.4 | 75.9 | 41.1 | 78.2 | 71.1 |
文本到SQL转换
我们在流行的文本到SQL基准测试Spider和BIRD上评估了CodeQwen1.5-7B-Chat。这里您可以找到我们使用的提示,源自Chang等人和Li等人的研究。
| 模型 | 规模 |
Spider
执行准确率
开发集
|
Bird
执行准确率
开发集
|
| GPT-3.5-Turbo | - | 70.1 | 37.2 |
| GPT-4 | - | 85.3 | 50.7 |
| CodeLlama-Instruct | 7B | 59.5 | 22.4 |
| DeepSeek-Coder-Instruct | 6.7B | 70.1 | 39.4 |
| CodeQwen1.5-Chat | 7B | 77.9 | 42.0 |
引用
如果您觉得我们的工作有帮助,欢迎引用。
@article{qwen,
title={Qwen技术报告},
author={白金泽 and 白帅 and 楚云飞 and 崔泽宇 and 党恺 and 邓晓东 and 范洋 and 葛文斌 and 韩宇 and 黄飞 and 惠斌远 and 纪珞 and 李梅 and 林君扬 and 林润基 and 刘代恒 and 刘高 and 卢承强 and 卢科铭 and 马建鑫 and 门瑞 and 任星彰 and 任宣丞 and 谭传奇 and 谭思楠 and 屠剑宏 and 王鹏 and 王世杰 and 王炜 and 吴圣光 and 徐奔奔 and 徐进 and 杨安 and 杨浩 and 杨健 and 杨树胜 and 姚洋 and 于博文 and 袁宏毅 and 袁铮 and 张建伟 and 张星轩 and 张义昌 and 张振儒 and 周昌 and 周靖人 and 周晓欢 and 朱天航},
journal={arXiv预印本 arXiv:2309.16609},
year={2023}
}












{kind=link}