
LLMChat 🎉
👋 欢迎来到 LLMChat 仓库,这是一个使用 Python FastAPI 构建的全栈 API 服务器实现,以及由 Flutter 提供支持的美丽前端。 💬 该项目旨在通过先进的 ChatGPT 和其他 LLM 模型提供无缝的聊天体验。 🔝 提供现代基础设施,可以在 GPT-4 的多模态和插件功能可用时轻松扩展。 🚀 享受您的停留!
演示
享受 Flutter 提供的美丽 UI 和丰富的可自定义组件集。
- 支持
移动和PC环境。 Markdown也被支持,因此您可以使用它来格式化消息。
Web 浏览
-
Duckduckgo
您可以使用 Duckduckgo 搜索引擎在网络上找到相关信息。只需激活“浏览”切换按钮!
观看完整浏览演示视频:https://www.youtube.com/watch?v=mj_CVrWrS08
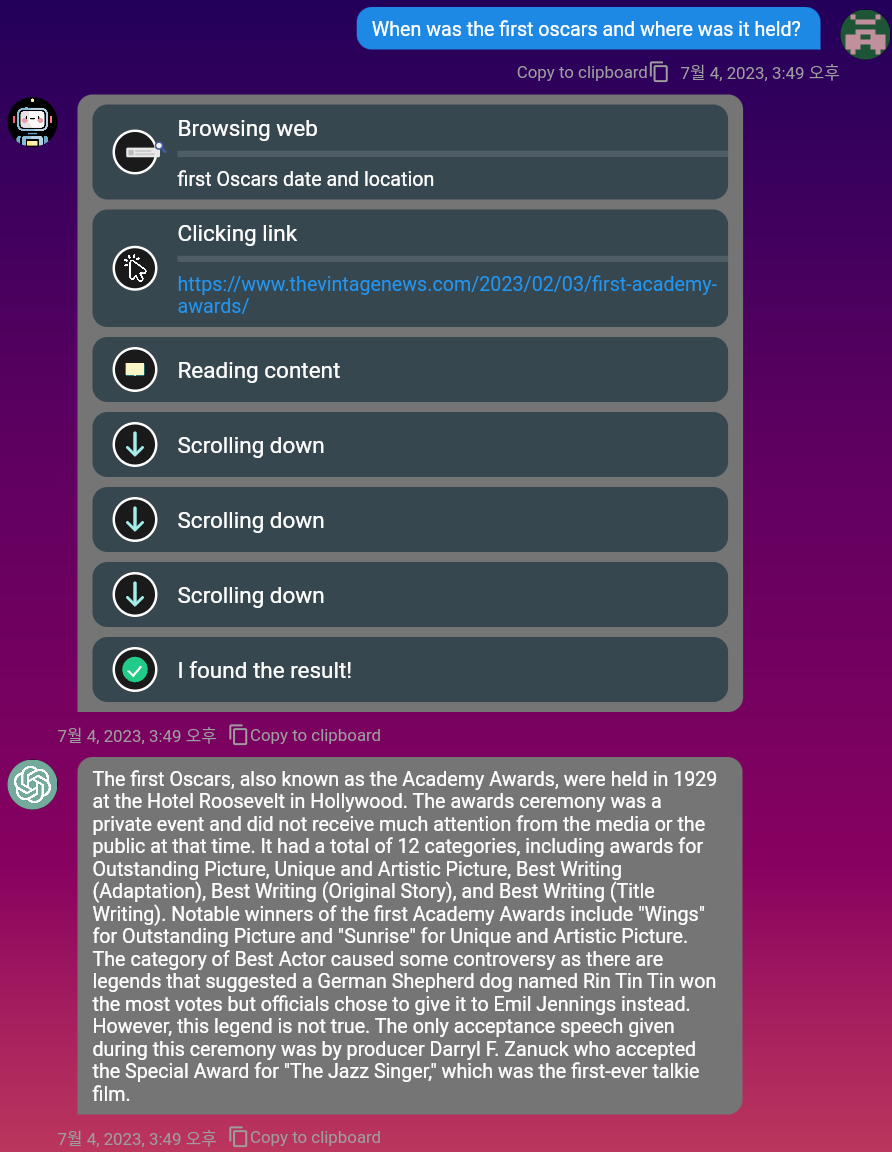
向量嵌入
-
嵌入任何文本
使用
/embed命令,您可以将文本无限期地存储到自己的私有向量数据库,并可以随时查询。如果使用/share命令,文本将存储在公共向量数据库中,供所有人共享。启用Query切换按钮或/query命令有助于 AI 通过在公共和私有数据库中搜索文本相似性生成上下文化的答案。这解决了语言模型的 记忆 限制。 -
上传您的 PDF 文件
您可以通过点击左下角的
Embed Document按钮嵌入 PDF 文件。几秒钟后,PDF 的文本内容会被转换为向量并嵌入到 Redis 缓存中。

-
更改您的聊天模型
您可以通过下拉菜单更改您的聊天模型。您可以在app/models/llms.py中的LLMModels定义您希望使用的模型。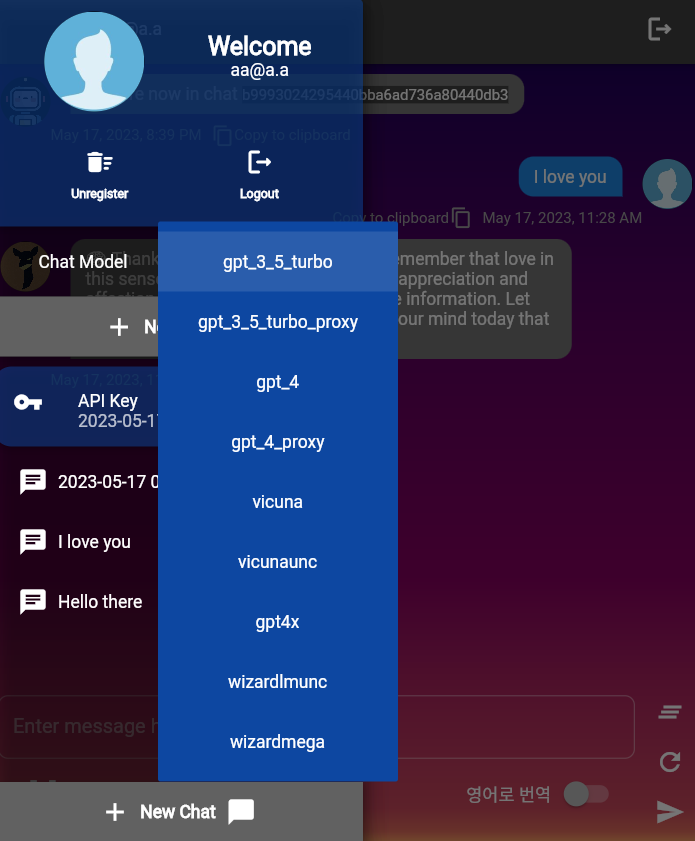
-
更改您的聊天标题
您可以通过点击聊天标题来更改您的聊天标题。这将被存储,直到您更改或删除它!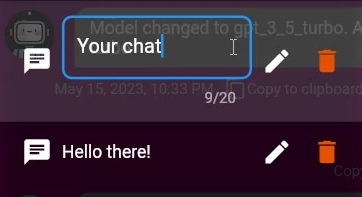
🦙 本地 LLMs

对于本地 Llalam LLMs,假定仅在本地环境中工作,并使用 http://localhost:8002/v1/completions 端点。每秒一次通过连接 http://localhost:8002/health 检查 llama API 服务器的状态,看是否返回 200 OK 响应,如果没有,它会自动运行一个单独的进程来创建 API 服务器。
Llama.cpp
llama.cpp 的主要目标是使用 GGML 4 位量化通过普通 C/C++ 实现运行 LLaMA 模型,无需依赖项。您需要从 huggingface 下载 GGML bin 文件,并将其放置在 llama_models/ggml 文件夹中,并在 app/models/llms.py 中定义 LLMModel。有一些示例,您可以轻松定义自己的模型。
有关更多信息,请参阅 llama.cpp 仓库:https://github.com/ggerganov/llama.cpp
Exllama
Llama 的独立 Python/C++/CUDA 实现,用于使用 4 位 GPTQ 权重,旨在在现代 GPU 上快速且内存高效地运行。它使用 pytorch 和 sentencepiece 运行模型。假定仅在本地环境中工作,并且至少需要一个 NVIDIA CUDA GPU。您需要从 huggingface 下载 tokenizer、config 和 GPTQ 文件,并将其放置在 llama_models/gptq/YOUR_MODEL_FOLDER 文件夹中,并在 app/models/llms.py 中定义 LLMModel。有一些示例,您可以轻松定义自己的模型。有关更多详细信息,请参阅 exllama 仓库:https://github.com/turboderp/exllama
主要特征
- FastAPI - 高性能
web 框架用于用 Python 构建 API。 - Flutter -
Webapp前端具有美丽的 UI 和丰富的可自定义组件集。 - ChatGPT - 与
OpenAI API无缝集成,用于文本生成和消息管理。 - LLAMA - 支持 LocalLLM、
LlamaCpp和Exllama模型。 - WebSocket 连接 - 使用 Flutter 前端 webapp,与 ChatGPT 和其他 LLM 模型进行
实时、双向通信。 - 向量存储 - 使用
Redis和Langchain,存储和检索向量嵌入以进行相似性搜索。这将帮助 AI 生成更相关的响应。 - 自动摘要 - 使用 Langchain 的摘要链,总结对话并将其存储在数据库中。这将帮助节省大量 token。
- Web 浏览 - 使用
Duckduckgo搜索引擎浏览网页并找到相关信息。 - 并发性 - 使用
async/await语法进行并发和并行的异步编程。 - 安全性 - 令牌验证和身份验证以保持 API 安全。
- 数据库 - 管理数据库连接并执行
MySQL查询。使用sqlalchemy.asyncio轻松执行创建、读取、更新和删除操作。 - 缓存 - 使用 aioredis 管理缓存连接并执行
Redis查询。使用aioredis轻松执行创建、读取、更新和删除操作。
入门 / 安装
要在本地计算机上设置,请按照以下简单步骤操作。
在开始之前,请确保您的计算机上安装了 docker 和 docker-compose。如果您想在没有 docker 的情况下运行服务器,则必须另外安装 Python 3.11。即便如此,您需要 Docker 来运行数据库服务器。
1. 克隆仓库
要递归克隆子模块以使用 Exllama 或 llama.cpp 模型,请使用以下命令:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.git
您只想使用核心功能(OpenAI),请使用以下命令:
git clone https://github.com/c0sogi/llmchat.git
2. 切换到项目目录
cd LLMChat
3. 创建 .env 文件
请参考 .env-sample 文件设置 env 文件。输入数据库信息以创建、OpenAI API 密钥以及其他必要的配置。可选项不是必需的,只需保留它们原样。
4. 运行服务器
执行这些命令。第一次启动服务器可能需要几分钟:
docker-compose -f docker-compose-local.yaml up
5. 停止服务器
docker-compose -f docker-compose-local.yaml down
6. 享受吧
现在您可以访问 http://localhost:8000/docs 上的服务器和 db:3306 或 cache:6379 上的数据库。您还可以访问 http://localhost:8000/chat 上的应用程序。
-
在没有 docker 的情况下运行服务器 如果您想在没有 docker 的情况下运行服务器,则必须另外安装
Python 3.11。即便如此,您需要Docker来运行数据库服务器。关闭已经通过docker-compose -f docker-compose-local.yaml down api运行的 API 服务器。不要忘记在 Docker 上运行其他数据库服务器!然后,运行以下命令:python -m main在这种情况下,您的服务器现在应该在
http://localhost:8001上运行。
许可证
该项目在 MIT 许可证 下授权,允许免费使用、修改和分发,只要在任何软件的副本或重要部分中包含原始版权和许可证声明。
为什么选择 FastAPI?
🚀 FastAPI 是一个用于用 Python 构建 API 的现代 web 框架。
💪 它具有高性能,易于学习,快速编码,并且准备好用于生产。
👍 FastAPI 的主要特点之一是支持并发和 async/await 语法。
🤝 这意味着您可以编写可以同时处理多个任务而不会阻塞彼此的代码,特别是在处理 I/O 密集型操作(如网络请求、数据库查询、文件操作等)时。
为什么选择 Flutter?
📱 Flutter 是 Google 开发的一个开源 UI 工具包,用于从单一代码库构建移动、网页和桌面平台的原生用户界面。
👨💻 它使用现代面向对象编程语言 Dart,并提供丰富的可自定义组件集,可以适应任何设计。
WebSocket 连接
您可以通过两个模块使用 WebSocket 连接访问 ChatGPT 或 LlamaCpp:app/routers/websocket 和 app/utils/chat/chat_stream_manager。这些模块通过 WebSocket 促进 Flutter 客户端和聊天模型之间的通信。通过 WebSocket,您可以建立一个实时的、双向的通信渠道来与 LLM 互动。
用法
要开始对话,请使用数据库中注册的有效 API 密钥连接到 WebSocket 路由 /ws/chat/{api_key}。请注意,此 API 密钥不同于 OpenAI API 密钥,仅供您的服务器验证用户使用。连接后,您可以发送消息和命令与 LLM 模型互动。WebSocket 将实时发送回复消息。此 WebSocket 连接通过 Flutter 应用程序建立,可以通过 /chat 端点访问。
websocket.py
websocket.py 负责设置 WebSocket 连接并处理用户身份验证。它定义了 WebSocket 路由 /chat/{api_key},接受 WebSocket 和 API 密钥作为参数。
当客户端连接到 WebSocket 时,它首先检查 API 密钥以验证用户身份。如果 API 密钥有效,stream_manager.py 模块中的 begin_chat() 函数将被调用以开始对话。
在未注册的 API 密钥或意外错误的情况下,会向客户端发送适当消息并关闭连接。
@router.websocket("/chat/{api_key}")
async def ws_chat(websocket: WebSocket, api_key: str):
...
stream_manager.py
stream_manager.py 负责管理对话并处理用户消息。它定义了 begin_chat() 函数,该函数接受 WebSocket 和用户 ID 作为参数。
该函数首先从缓存管理器初始化用户的聊天上下文。然后,向客户通过 WebSocket 发送初始消息历史记录。
对话在循环中继续,直到连接关闭。在对话过程中,处理用户的消息并生成相应的 GPT 响应。
class ChatStreamManager:
@classmethod
async def begin_chat(cls, websocket: WebSocket, user: Users) -> None:
...
发送消息到 WebSocket
SendToWebsocket 类用于发送消息和流到 WebSocket。它有两个方法:message() 和 stream()。message() 方法向 WebSocket 发送完整消息,而 stream() 方法向 WebSocket 发送流。
class SendToWebsocket:
@staticmethod
async def message(...):
...
@staticmethod
async def stream(...):
...
处理 AI 响应
MessageHandler 类还处理 AI 响应。ai() 方法将 AI 响应发送到 WebSocket。如果启用翻译,则在发送到客户端之前使用 Google 翻译 API 将响应进行翻译。
class MessageHandler:
...
@staticmethod
async def ai(...):
...
处理自定义命令
用户消息使用 HandleMessage 类处理。如果消息以 / 开头,例如 /YOUR_CALLBACK_NAME,它会被视为命令并生成相应的命令响应。否则,处理用户的消息并将其发送到 LLM 模型以生成响应。
命令使用 ChatCommands 类处理。它根据命令执行相应的回调函数。您可以通过简单地在 app.utils.chat.chat_commands 中的 ChatCommands 类中添加回调来添加新命令。
🌟向量嵌入
使用 Redis 存储对话的向量嵌入 🗨️ 可以通过多个方面帮助 ChatGPT 模型 🤖,例如高效快速地检索对话上下文 🕵️♀️,处理大量数据 📊,并通过向量相似性搜索 🔎 提供更相关的回答。 一些有趣的示例说明了这种方法在实际中是如何工作的:
- 想象一个用户正在与ChatGPT聊天,讨论他们最喜欢的电视节目📺 并提到一个特定的角色👤。使用Redis,ChatGPT可以检索以前的对话,在这些对话中提到了该角色,并利用这些信息提供更详细的见解或有关该角色的趣事🤔。
- 另一个场景是用户正在与ChatGPT讨论他们的旅行计划✈️。如果他们提到一个特定的城市🌆或地标🏰,ChatGPT可以使用向量相似性搜索来检索以前讨论过相同地点的对话,并根据这些背景提供推荐或建议🧳。
- 如果用户提到某种特定的菜系🍝或菜肴🍱,ChatGPT可以检索以前讨论过这些话题的对话,并根据这些背景提供推荐或建议🍴。
1. 使用/embed命令嵌入文本
当用户在聊天窗口中输入类似/embed <text_to_embed>的命令时,VectorStoreManager.create_documents方法被调用。该方法使用OpenAI的text-embedding-ada-002模型将输入文本转换为向量并存储在Redis向量存储中。
@staticmethod
@command_response.send_message_and_stop
async def embed(text_to_embed: str, /, buffer: BufferedUserContext) -> str:
"""Embed the text and save its vectors in the redis vectorstore.\n
/embed <text_to_embed>"""
...
2. 使用/query命令查询嵌入的数据
当用户输入/query <query>命令时,asimilarity_search函数用于查找与Redis向量存储中的嵌入数据具有最高向量相似性的三条结果。这些结果暂时存储在聊天的上下文中,这有助于AI通过参考这些数据回答查询。
@staticmethod
async def query(query: str, /, buffer: BufferedUserContext, **kwargs) -> Tuple[str | None, ResponseType]:
"""从Redis向量存储中查询\n
/query <query>"""
...
3. 自动嵌入上传的文本文件
当运行begin_chat函数时,如果用户上传了一个包含文本的文件(例如PDF或TXT文件),文本将自动从文件中提取,并其向量嵌入将保存到Redis中。
@classmethod
async def embed_file_to_vectorstore(cls, file: bytes, filename: str, collection_name: str) -> str:
# 如果用户上传文件,就将其嵌入
...
4. commands.py功能
在commands.py文件中,有几个重要的组件:
command_response:该类用于在命令方法上设置装饰器,以指定下一个操作。它有助于定义各种响应类型,例如发送消息并停止、发送消息并继续、处理用户输入、处理AI响应等。command_handler:该函数负责根据用户输入的文本执行命令回调方法。arguments_provider:该函数会根据命令方法的注释类型自动提供所需的参数。
📝 自动摘要
通过添加一个摘要任务给LLM,可以节省tokens。这项自动摘要任务是增强聊天机器人效率的关键功能。让我们分解一下该功能的详细信息:
- 任务触发:该功能在用户输入消息或AI响应消息时激活。此时,将生成一个自动摘要任务以压缩文本内容。
- 任务存储:自动摘要任务会存储在
BufferUserChatContext的task_list属性中。这充当了管理与用户聊天上下文关联的任务的队列。 - 任务收集:在
MessageHandler完成一个用户与AI的问题和解答循环后,调用harvest_done_tasks函数。此函数收集摘要任务的结果,确保不会遗漏任何内容。 - 摘要应用:在收集过程之后,当我们的聊天机器人请求来自语言模型(如OPENAI和LLAMA_CPP)的回答时,摘要结果会替换原始消息。这样,我们就能发送比初始冗长消息更为简练的提示。
- 用户体验:从用户的角度来看,他们只会看到原始消息。摘要版本的消息不会显示给他们,从而保持透明度并避免可能的混淆。
- 并发任务:该自动摘要任务的另一个关键特点是它不会阻碍其他任务。换句话说,当聊天机器人忙于摘要文本时,其他任务仍然可以执行,从而提高整体效率。
默认情况下,摘要链仅适用于长度为512个tokens或更多的消息。可以在ChatConfig中打开/关闭该功能或设置阈值。
📚 大语言模型(LLM)
此代码库包含定义在llms.py中的不同大语言模型。每个LLM模型类都继承自基类LLMModel。LLMModels枚举是这些LLM的集合。
所有操作都异步处理,不会中断主线程。然而,本地的大语言模型无法同时处理多个请求,因为它们计算量太大。因此,使用了Semaphore来将请求数量限制为1。
📌 用法
通过UserChatContext.construct_default函数使用的默认LLM模型是gpt-3.5-turbo。你可以改变该函数的默认设置。
📖 模型描述
1️⃣ OpenAIModel
OpenAIModel通过请求OpenAI服务器的聊天完成异步生成文本。它需要一个OpenAI API密钥。
2️⃣ LlamaCppModel
LlamaCppModel读取本地存储的GGML模型。LLama.cpp GGML模型必须放在llama_models/ggml文件夹中,作为.bin文件。例如,如果你从"https://huggingface.co/TheBloke/robin-7B-v2-GGML"下载了一个q4_0量化模型,
那么模型路径应为"robin-7b.ggmlv3.q4_0.bin"。
3️⃣ ExllamaModel
ExllamaModel读取本地存储的GPTQ模型。Exllama GPTQ模型必须放在llama_models/gptq文件夹中作为一个文件夹。例如,如果你从"https://huggingface.co/TheBloke/orca_mini_7B-GPTQ/tree/main"下载了3个文件:
- orca-mini-7b-GPTQ-4bit-128g.no-act.order.safetensors
- tokenizer.model
- config.json
那么你需要将它们放在一个文件夹中。 模型路径应该是文件夹名称,比如"orca_mini_7b",其中包含这3个文件。
📝 处理异常
处理可能在文本生成过程中发生的异常。如果抛出ChatLengthException,会自动执行一个例程,以将消息限制在cutoff_message_histories函数定义的tokens数量内,并重新发送。这样确保用户无论tokens限制如何,都能顺畅地聊天。
WebSocket连接背后...
此项目旨在创建一个API后端,以实现大语言模型聊天机器人服务。它使用缓存管理器将消息和用户配置文件存储在Redis中,并使用消息管理器安全缓存消息,以确保tokens数量不超过可接受的限制。
缓存管理器
缓存管理器(CacheManager)负责处理用户上下文信息和消息历史。它将这些数据存储在Redis中,以便于检索和修改。管理器提供了多种方法来与缓存进行交互,例如:
read_context_from_profile:根据用户的配置文件从Redis中读取用户的聊天上下文。create_context:在Redis中创建新的用户聊天上下文。reset_context:将用户的聊天上下文重置为默认值。update_message_histories:更新特定角色(用户、AI或系统)的消息历史。lpop_message_history/rpop_message_history:从列表的左端或右端删除并返回消息历史。append_message_history:将消息历史附加到列表的末尾。get_message_history:检索特定角色的消息历史。delete_message_history:删除特定角色的消息历史。set_message_history:为特定角色和索引设置特定消息历史。
消息管理器
消息管理器(MessageManager)确保消息历史中的tokens数量不会超过指定的限制。它安全地处理在用户聊天上下文中添加、删除和设置消息历史,同时保持tokens限制。管理器提供了多种方法来与消息历史进行交互,例如:
add_message_history_safely:在确保tokens限制不被超出的前提下,将消息历史添加到用户聊天上下文中。pop_message_history_safely:从列表的右端删除并返回消息历史,同时更新tokens计数。set_message_history_safely:在用户聊天上下文中设置特定消息历史,更新tokens计数并确保tokens限制不被超出。
用法
要在你的项目中使用缓存管理器和消息管理器,按以下方式导入它们:
from app.utils.chat.managers.cache import CacheManager
from app.utils.chat.message_manager import MessageManager
然后,可以使用它们的方法根据你的需求与Redis缓存进行交互并管理消息历史。
例如,创建一个新的用户聊天上下文:
user_id = "example@user.com" # email格式
chat_room_id = "example_chat_room_id" # 通常是32个字符的`uuid.uuid4().hex`
default_context = UserChatContext.construct_default(user_id=user_id, chat_room_id=chat_room_id)
await CacheManager.create_context(user_chat_context=default_context)
安全地将消息历史添加到用户聊天上下文:
user_chat_context = await CacheManager.read_context_from_profile(user_chat_profile=UserChatProfile(user_id=user_id, chat_room_id=chat_room_id))
content = "这是一个示例消息。"
role = ChatRoles.USER # 可以是枚举,例如ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager.add_message_history_safely(user_chat_context, content, role)
中间件
本项目使用token_validator中间件和其他在FastAPI应用程序中使用的中间件。这些中间件负责控制对API的访问,确保只有授权和认证的请求被处理。
示例
以下中间件被添加到FastAPI应用程序:
- 访问控制中间件:确保只有授权请求被处理。
- CORS中间件:允许来自特定来源的请求,如应用配置中所定义。
- 受信任主机中间件:确保请求来自受信任的主机,如应用配置中所定义。
访问控制中间件
访问控制中间件在token_validator.py文件中定义。它负责验证API密钥和JWT令牌。
状态管理器
StateManager类用于初始化请求状态变量。它设置请求时间、开始时间、IP地址和用户令牌。
访问控制
AccessControl类包含两个静态方法,用于验证API密钥和JWT令牌:
api_service:通过检查请求中所需的查询参数和标头的存在性来验证API密钥。它调用Validator.api_key方法来验证API密钥、密钥和时间戳。non_api_service:通过检查请求中是否存在'authorization'标头或'Authorization' cookie来验证JWT令牌。它调用Validator.jwt方法来解码和验证JWT令牌。
验证器
Validator类包含两个静态方法,用于验证API密钥和JWT令牌:
api_key:验证API访问密钥、哈希密钥和时间戳。如果验证成功,返回一个UserToken对象。jwt:解码和验证JWT令牌。如果验证成功,返回一个UserToken对象。
访问控制函数
access_control函数是一个异步函数,处理中间件的请求和响应流程。它使用StateManager类初始化请求状态,根据请求的URL确定所需的认证类型(API密钥或JWT令牌),并使用AccessControl类进行验证。如果在验证过程中发生错误,会引发适当的HTTP异常。
令牌
令牌实用程序在token.py文件中定义。它包含两个函数:
create_access_token:使用给定的数据和过期时间创建JWT令牌。token_decode:解码和验证JWT令牌。如果令牌过期或无法解码,会引发异常。
参数实用工具
params_utils.py文件包含一个实用函数,用于使用HMAC和SHA256哈希查询参数和密钥:
hash_params:接受查询参数和密钥作为输入,并返回一个base64编码的哈希字符串。
日期实用工具
date_utils.py文件包含UTC类,以及用于处理日期和时间戳的实用函数:
now:返回当前UTC时间,可选的小时差。timestamp:返回当前UTC时间戳,可选的小时差。timestamp_to_datetime:将时间戳转换为datetime对象,可选的小时差。
日志记录器
logger.py文件包含ApiLogger类,它记录API请求和响应信息,包括请求URL、方法、状态码、客户端信息、处理时间和错误详细信息(如适用)。日志记录函数在access_control函数结束时被调用,以记录处理的请求和响应。
用法
若要在你的FastAPI应用程序中使用token_validator中间件,只需导入access_control函数并将其添加为FastAPI实例的中间件:
from app.middlewares.token_validator import access_control
app = FastAPI()
app.add_middleware(dispatch=access_control, middleware_class=BaseHTTPMiddleware)
确保还添加 CORS 和 Trusted Host 中间件以实现全面的访问控制:
```python
app.add_middleware(
CORSMiddleware,
allow_origins=config.allowed_sites,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.add_middleware(
TrustedHostMiddleware,
allowed_hosts=config.trusted_hosts,
except_path=["/health"],
)
现在,任何传入到你的 FastAPI 应用的请求将由 token_validator 中间件和其他中间件处理,以确保只有授权和认证的请求会被处理。
数据库连接
该模块 app.database.connection 提供了一个易于使用的界面,用于使用 SQLAlchemy 和 Redis 管理数据库连接和执行 SQL 查询。它支持 MySQL,并且可以很方便地与这个项目集成。
特性
- 创建和删除数据库
- 创建和管理用户
- 授予用户权限
- 执行原始 SQL 查询
- 支持异步的数据库会话管理
- 支持 Redis 缓存以加快数据访问速度
用法
首先,从模块中导入所需的类:
from app.database.connection import MySQL, SQLAlchemy, CacheFactory
接下来,创建一个 SQLAlchemy 类的实例,并使用你的数据库设置对其进行配置:
from app.common.config import Config
config: Config = Config.get()
db = SQLAlchemy()
db.start(config)
现在,你可以使用 db 实例执行 SQL 查询并管理会话:
# 执行原始 SQL 查询
result = await db.execute("SELECT * FROM users")
# 使用 run_in_session 装饰器来管理会话
@db.run_in_session
async def create_user(session, username, password):
await session.execute("INSERT INTO users (username, password) VALUES (:username, :password)", {"username": username, "password": password})
await create_user("JohnDoe", "password123")
要使用 Redis 缓存,请创建一个 CacheFactory 类的实例,并用你的 Redis 设置对其进行配置:
cache = CacheFactory()
cache.start(config)
现在你可以使用 cache 实例与 Redis 进行交互:
# 在 Redis 中设置一个键
await cache.redis.set("my_key", "my_value")
# 从 Redis 中获取一个键
value = await cache.redis.get("my_key")
实际上,在这个项目中,MySQL 类在应用启动时进行初始设置,所有的数据库连接只需在模块末尾使用 db 和 cache 变量。😅
所有的数据库设置将在 app.common.app_settings 中的 create_app() 函数中进行。例如,app.common.app_settings 中的 create_app() 函数看起来像这样:
def create_app(config: Config) -> FastAPI:
# 初始化 app & db & js
new_app = FastAPI(
title=config.app_title,
description=config.app_description,
version=config.app_version,
)
db.start(config=config)
cache.start(config=config)
js_url_initializer(js_location="app/web/main.dart.js")
# 注册路由
# ...
return new_app
数据库 CRUD 操作
这个项目使用简单高效的方式,通过 SQLAlchemy 及两个模块和路径:app.database.models.schema 和 app.database.crud 来处理数据库的 CRUD(创建、读取、更新、删除)操作。
概述
app.database.models.schema
schema.py 模块负责使用 SQLAlchemy 定义数据库模型及其关系。它包含了一组继承于 Base(一个 declarative_base() 的实例)的类。每个类代表数据库中的一张表,其属性代表表中的列。这些类还继承自一个 Mixin 类,该类为所有模型提供了一些通用的方法和属性。
Mixin 类
Mixin 类为所有继承自它的类提供了一些通用的属性和方法。一些属性包括:
id: 表的整数主键。created_at: 记录创建时间。updated_at: 记录最后更新时间。ip_address: 创建或更新记录的客户端 IP 地址。
它还提供了几个使用 SQLAlchemy 执行 CRUD 操作的类方法,如:
add_all(): 添加多个记录到数据库。add_one(): 添加单个记录到数据库。update_where(): 基于过滤器更新数据库中的记录。fetchall_filtered_by(): 从数据库中获取与提供的过滤器匹配的所有记录。one_filtered_by(): 从数据库中获取与提供的过滤器匹配的单个记录。first_filtered_by(): 从数据库中获取与提供的过滤器匹配的第一条记录。one_or_none_filtered_by(): 获取单个记录,如果没有记录与过滤器匹配,则返回None。
app.database.crud
users.py 和 api_keys.py 模块包含了一组使用在 schema.py 中定义的类的函数,这些函数使用 Mixin 类提供的类方法与数据库进行交互。
一些此模块中的函数包括:
create_api_key(): 为用户创建新的 API 密钥。get_api_keys(): 获取用户的所有 API 密钥。get_api_key_owner(): 获取 API 密钥的所有者。get_api_key_and_owner(): 获取 API 密钥及其所有者。update_api_key(): 更新 API 密钥。delete_api_key(): 删除 API 密钥。is_email_exist(): 检查数据库中是否存在指定的邮箱。get_me(): 根据用户 ID 获取用户信息。is_valid_api_key(): 检查 API 密钥是否有效。register_new_user(): 在数据库中注册新用户。find_matched_user(): 在数据库中查找邮箱匹配的用户。
用法
要使用提供的 CRUD 操作,从 crud.py 模块导入相关函数,并用所需参数调用它们。例如:
import asyncio
from app.database.crud.users import register_new_user, get_me, is_email_exist
from app.database.crud.api_keys import create_api_key, get_api_keys, update_api_key, delete_api_key
async def main():
# `user_id` 是 MySQL 数据库中的整数索引,`email` 是用户的实际姓名
# 该邮箱将在聊天中用作 `user_id`。不要与 MySQL 中的 `user_id` 混淆
# 注册新用户
new_user = await register_new_user(email="test@test.com", hashed_password="...")
# 获取用户信息
user = await get_me(user_id=1)
# 检查数据库中是否存在指定邮箱
email_exists = await is_email_exist(email="test@test.com")
# 为 ID 为 1 的用户创建新的 API 密钥
new_api_key = await create_api_key(user_id=1, additional_key_info={"user_memo": "测试 API 密钥"})
# 获取 ID 为 1 的用户的所有 API 密钥
api_keys = await get_api_keys(user_id=1)
# 更新列表中的第一个 API 密钥
updated_api_key = await update_api_key(updated_key_info={"user_memo": "更新的测试 API 密钥"}, access_key_id=api_keys[0].id, user_id=1)
# 删除列表中的第一个 API 密钥
await delete_api_key(access_key_id=api_keys[0].id, access_key=api_keys[0].access_key, user_id=1)
if __name__ == "__main__":
asyncio.run(main())











