
go-json



与Go的encoding/json兼容的快速JSON编码器/解码器

路线图
* 版本 (预计发布日期)
* v0.9.0
|
| 在保持与encoding/json兼容的同时,我们将添加便捷的API
|
v
* v1.0.0
我们正在接受v0.9.0和v1.0.0之间将实现的功能请求。 如果您需要某个API,请在这里提交问题。
特性
- 可直接替代
encoding/json - 快速(参见基准测试部分)
- 可通过选项灵活定制
- 可对编码的字符串进行着色
- 可将context.Context传播到
MarshalJSON或UnmarshalJSON - 可以动态地以类型安全的方式过滤结构体的字段
安装
go get github.com/goccy/go-json
使用方法
将导入语句从encoding/json替换为github.com/goccy/go-json
-import "encoding/json"
+import "github.com/goccy/go-json"
JSON库比较
| 名称 | 编码器 | 解码器 | 与encoding/json兼容 |
|---|---|---|---|
| encoding/json | 是 | 是 | 不适用 |
| json-iterator/go | 是 | 是 | 部分 |
| easyjson | 是 | 是 | 否 |
| gojay | 是 | 是 | 否 |
| segmentio/encoding/json | 是 | 是 | 部分 |
| jettison | 是 | 否 | 否 |
| simdjson-go | 否 | 是 | 否 |
| goccy/go-json | 是 | 是 | 是 |
json-iterator/go在很多方面与encoding/json不兼容(例如 https://github.com/json-iterator/go/issues/229 ),但它已经很久没有得到支持了。segmentio/encoding/json对编码器支持得很好,但对于一些解码器API如Token(流式解码)不支持
其他库
我尝试进行基准测试,但没有成功。 此外,它似乎在收到意外值时会发生panic,因为没有错误处理...
基准测试结果非常慢。 似乎假定用户会正确使用缓冲池。 而且,开发似乎已经停止了
基准测试
$ cd benchmarks
$ go test -bench .
编码
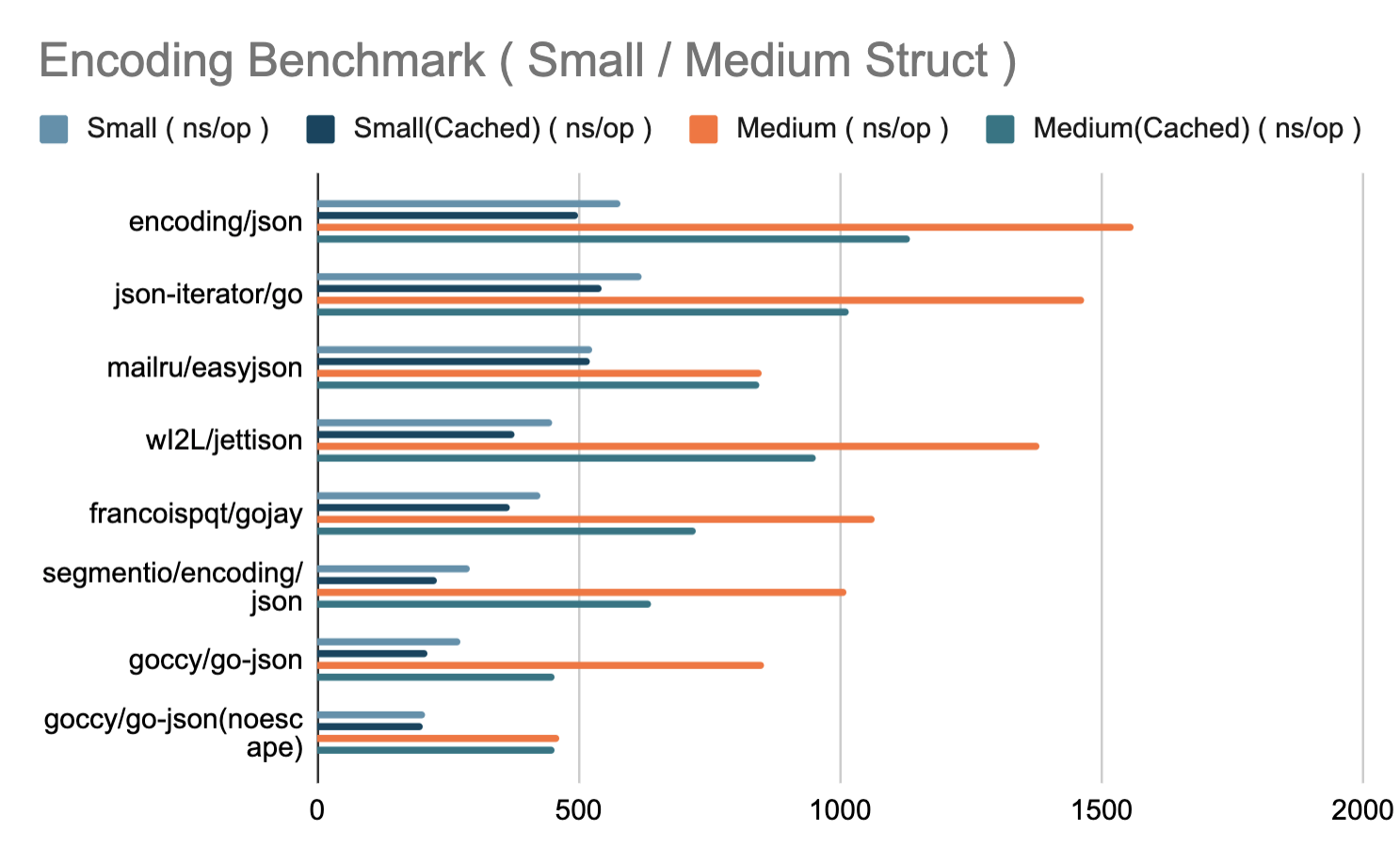
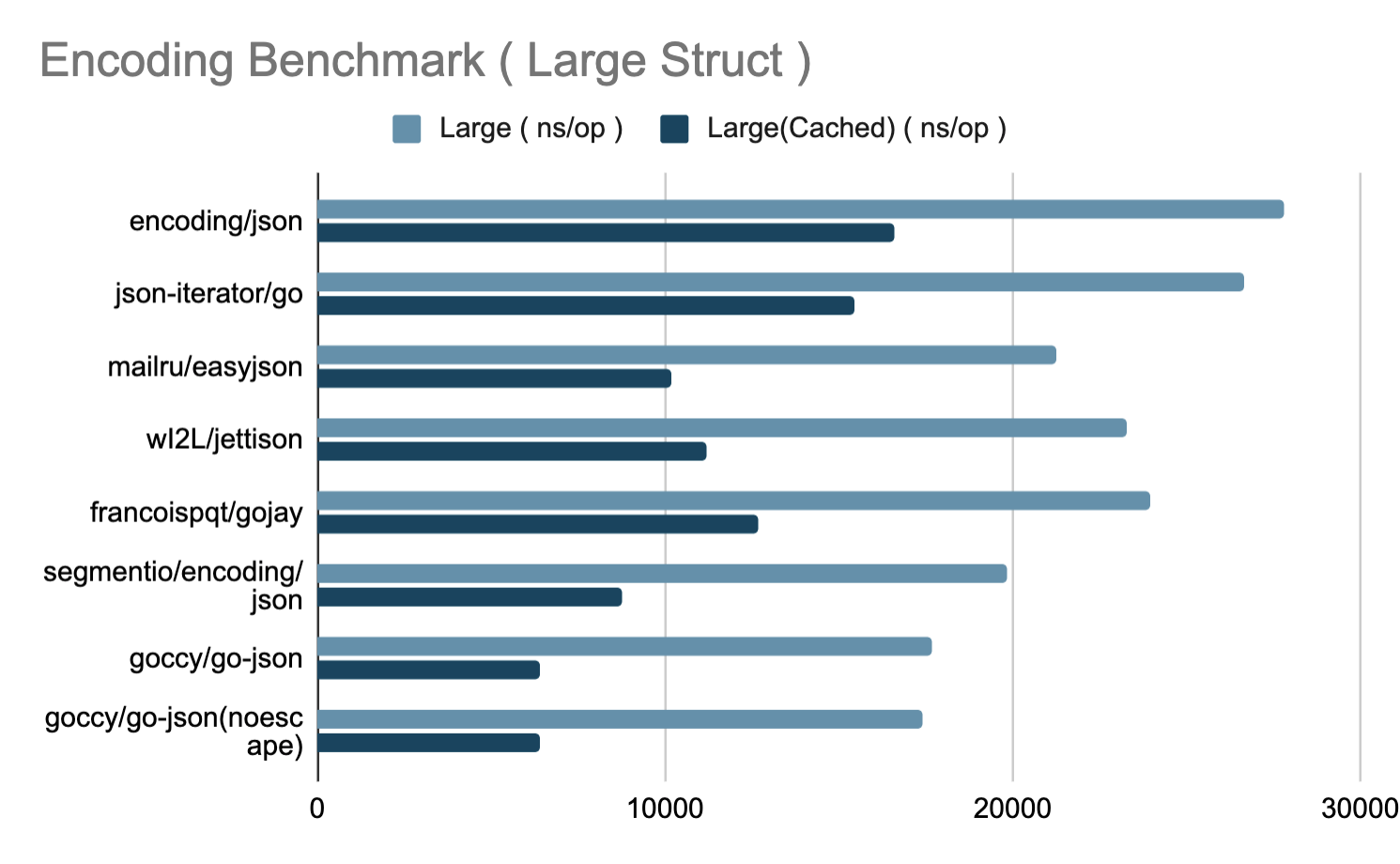
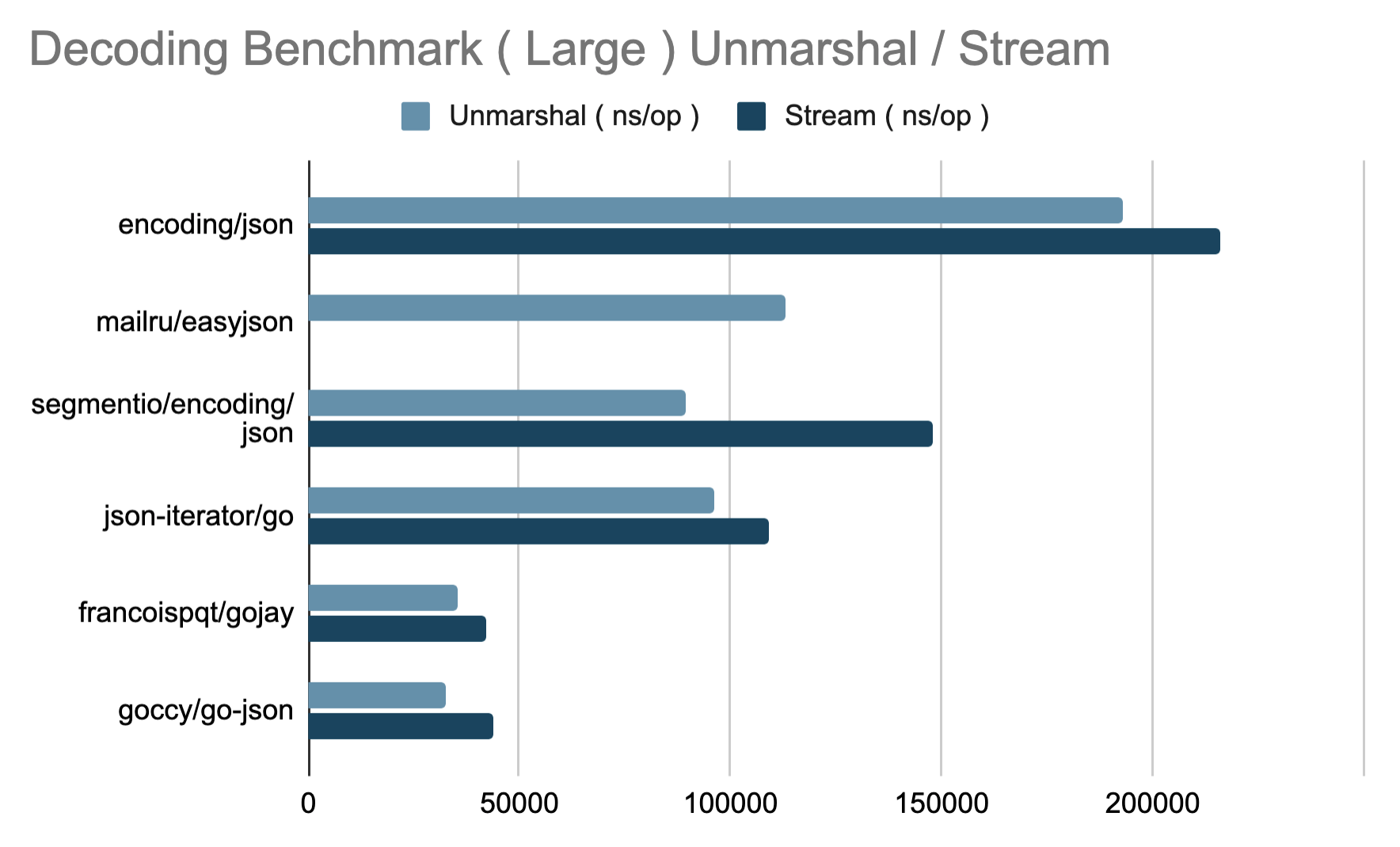
解码
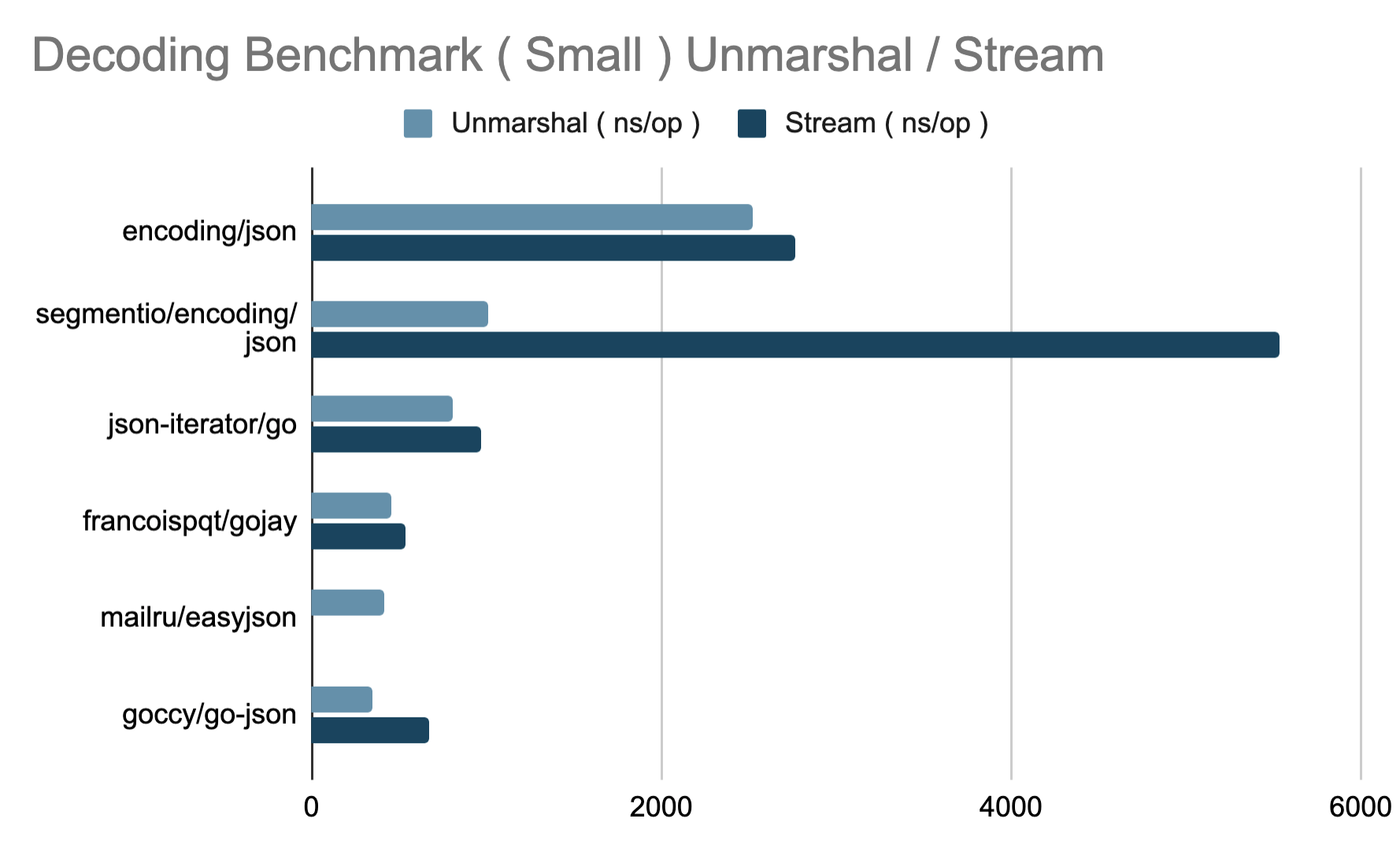
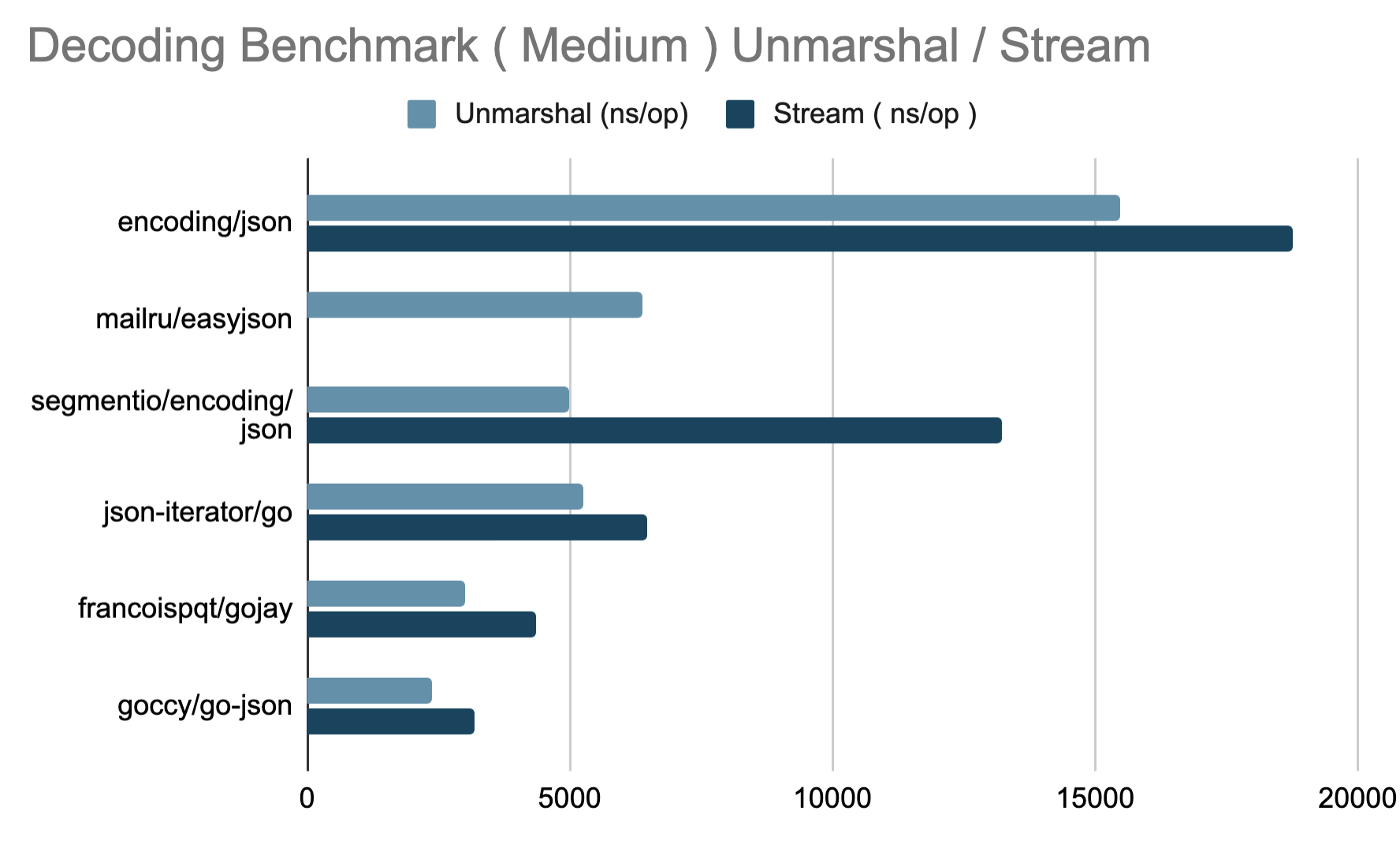
模糊测试
go-json-fuzz是用于模糊测试的仓库。 如果您在该仓库中运行测试并发现bug,请将测试用例提交到go-json-fuzz,并在go-json中报告问题。
工作原理
go-json在编码和解码方面都比其他库快得多。
通过使用自动代码生成来提高性能或使用专用接口可以更容易实现,但go-json敢于坚持与encoding/json的兼容性和简单接口。尽管如此,我们的开发目标是成为最快的库。
在这里,我们解释了go-json实现的各种加速技术。
基本技术
这里列出的技术是上面列出的大多数库使用的技术。
缓冲区重用
由于json.Marshal(interface{}) ([]byte, error)结果所需的唯一值是[]byte,因此在编码过程中必须分配的唯一值是返回值[]byte。
此外,随着分配次数的增加,性能会受到影响,因此在创建[]byte时应尽可能减少分配次数。
因此,有一种技术是通过使用sync.Pool重用先前编码使用的缓冲区来减少必须分配新缓冲区的次数。
最后,您分配一个与结果缓冲区一样长的缓冲区并将内容复制到其中,理论上只需要分配一次缓冲区。
type buffer struct {
data []byte
}
var bufPool = sync.Pool{
New: func() interface{} {
return &buffer{data: make([]byte, 0, 1024)}
},
}
buf := bufPool.Get().(*buffer)
data := encode(buf.data) // 重用 buf.data
newBuf := make([]byte, len(data))
copy(newBuf, buf)
buf.data = data
bufPool.Put(buf)
消除反射
众所周知,反射操作非常慢。
因此,利用每个二进制文件中存储类型信息的地址位置是固定的这一事实(我们称之为typeptr),
我们可以使用类型信息中的地址调用预先构建的优化过程。
例如,您可以从interface{}获取类型信息的地址,如下所示,并使用该信息调用没有反射的进程。
要在没有反射的情况下处理,传递一个指向存储值的指针(unsafe.Pointer)。
type emptyInterface struct {
typ unsafe.Pointer
ptr unsafe.Pointer
}
var typeToEncoder = map[uintptr]func(unsafe.Pointer)([]byte, error){}
func Marshal(v interface{}) ([]byte, error) {
iface := (*emptyInterface)(unsafe.Pointer(&v)
typeptr := uintptr(iface.typ)
if enc, exists := typeToEncoder[typeptr]; exists {
return enc(iface.ptr)
}
...
}
※ 实际上,typeToEncoder可以被多个goroutine引用,因此需要进行排他控制。
独特的加速技术
编码器
不转义Marshal的参数
json.Marshal和json.Unmarshal接收interface{}值,并动态执行类型确定以进行处理。
在正常情况下,您需要使用reflect库来动态确定类型,但由于reflect.Type被定义为interface,当您调用reflect.Type的方法时,反射的参数被转义。
因此,Marshal和Unmarshal的参数总是被转义到堆上。
然而,go-json可以使用reflect.Type的特性同时避免转义。
reflect.Type被定义为interface,但实际上reflect.Type只由reflect包中定义的结构rtype实现。
因此,到目前为止,reflect.Type与*reflect.rtype相同。
因此,通过直接处理reflect.Type的实现*reflect.rtype,可以避免转义,因为它从interface变为使用struct。
go-json直接处理*reflect.rtype的技术在rtype.go中实现
此外,同样的技术被作为一个库提取出来( https://github.com/goccy/go-reflect )
最初,这个特性是go-json的默认行为。
但经过仔细测试后,我发现如果将大值传递给json.Marshal(),并且参数无法分配到栈上,它就无法正确地转义到堆上(Go编译器的一个bug)。
因此,在解决这个问题之前,这个特性将作为可选提供。
要使用它,请添加NoEscape,如MarshalNoEscape()
使用操作码序列进行编码
我解释过,您可以使用typeptr从类型信息调用预先构建的过程。
在其他库中,这个专用过程通过将其作为匿名函数等进行函数调用来处理,但函数调用本质上是缓慢的过程,应尽可能避免。
因此,go-json采用了基于指令的执行处理系统,这也用于实现编程语言的虚拟机。
如果是第一次编码的类型,创建编码所需的操作码(指令)序列。
从第二次开始,使用typeptr获取缓存的预构建操作码序列并基于它进行编码。操作码序列的示例如下所示。
json.Marshal(struct{
X int `json:"x"`
Y string `json:"y"`
}{X: 1, Y: "hello"})
当编码像上面这样的结构时,创建像这样的操作码序列:
- opStructFieldHead ( `{` )
- opStructFieldInt ( `"x": 1,` )
- opStructFieldString ( `"y": "hello"` )
- opStructEnd ( `}` )
- opEnd
※ 处理每个操作时,写入右侧的字符。
此外,每个操作码由以下结构管理(伪代码)。
type opType int
const (
opStructFieldHead opType = iota
opStructFieldInt
opStructFieldStirng
opStructEnd
opEnd
)
type opcode struct {
op opType
key []byte
next *opcode
}
使用操作码序列进行编码的过程大致实现如下。
func encode(code *opcode, b []byte, p unsafe.Pointer) ([]byte, error) {
for {
switch code.op {
case opStructFieldHead:
b = append(b, '{')
code = code.next
case opStructFieldInt:
b = append(b, code.key...)
b = appendInt((*int)(unsafe.Pointer(uintptr(p)+code.offset)))
code = code.next
case opStructFieldString:
b = append(b, code.key...)
b = appendString((*string)(unsafe.Pointer(uintptr(p)+code.offset)))
code = code.next
case opStructEnd:
b = append(b, '}')
code = code.next
case opEnd:
goto END
}
}
END:
return b, nil
}
通过这种方式,使用巨大的switch-case通过操作链表操作码来进行编码,以避免不必要的函数调用。
操作码序列优化
使用操作码序列进行编码的优点之一是易于优化。 上面提到的操作码序列实际上被转换为以下优化的操作并使用。
- opStructFieldHeadInt ( `{"x": 1,` )
- opStructEndString ( `"y": "hello"}` )
- opEnd
它已经从5个操作码减少到3个操作码!
减少操作码的数量意味着减少switch-case的分支数。
换句话说,操作数越接近1,处理速度就越快。
在go-json中,像上面这样优化以减少操作码本身的数量,并通过准备具有优化路径的操作码来加速。
将递归调用从CALL更改为JMP
如果类型被递归定义如下,则在编码期间需要递归处理:
type T struct {
X int
U *U
}
type U struct {
T *T
}
b, err := json.Marshal(&T{
X: 1,
U: &U{
T: &T{
X: 2,
},
},
})
fmt.Println(string(b))
然而,如果类型信息过多,会占用大量内存,所以默认情况下我们只在切片大小在**2Mib**内时使用这种优化。
如果这种方法不可用,它将回退到上述基于`atomic`的处理。
如果你想了解更多,请参考[这里](https://github.com/goccy/go-json/blob/master/internal/runtime/type.go#L36-L100)的实现。
## 解码器
### 通过typeptr从map分派到切片
与编码器一样,解码器也使用typeptr调用专用处理。
### 使用NUL字符进行更快的终止字符检查
为了解码,你必须按位置遍历输入缓冲区。此时,如果检查缓冲区是否已到达末尾,会非常慢。
`buf`:`[]byte`类型变量。保存传递给解码器的字符串
`cursor`:`int64`类型变量。保存当前读取位置
```go
buflen := len(buf)
for ; cursor < buflen; cursor++ { // 始终比较cursor和buflen,这很慢。
switch buf[cursor] {
case ' ', '\n', '\r', '\t':
}
}
因此,通过在读取缓冲区末尾添加NUL(\000)字符,可以同时检查终止字符和其他字符。
for {
switch buf[cursor] {
case ' ', '\n', '\r', '\t':
case '\000':
return nil
}
cursor++
}
使用边界检查消除
由于NUL字符优化,Go编译器每次都会进行边界检查,尽管buf[cursor]不会导致越界访问。
因此,go-json通过指针操作获取热点字符来消除边界检查。例如,以下代码:
func char(ptr unsafe.Pointer, offset int64) byte {
return *(*byte)(unsafe.Pointer(uintptr(ptr) + uintptr(offset)))
}
p := (*sliceHeader)(&unsafe.Pointer(buf)).data
for {
switch char(p, cursor) {
case ' ', '\n', '\r', '\t':
case '\000':
return nil
}
cursor++
}
使用位图检查结构体字段的存在
我通过性能分析结果发现,在结构体解码中,字段查找过程耗时很长。
例如,考虑将像{"a":1,"b":2,"c":3}这样的字符串解码到以下结构:
type T struct {
A int `json:"a"`
B int `json:"b"`
C int `json:"c"`
}
此时,发现在解码过程中,从字段名获取对应的解码过程如下所示,这需要大量时间:
fieldName := decodeKey(buf, cursor) // "a"或"b"或"c"
decoder, exists := fieldToDecoderMap[fieldName] // 非常慢
if exists {
decoder(buf, cursor)
} else {
skipValue(buf, cursor)
}
为了改进这个过程,json-iterator/go进行了优化,当结构体的字段数不超过10个时,可以通过switch-case分支(switch-case比map快)。然而,由于使用FNV算法哈希的值进行条件分支,存在哈希冲突的风险。另外,gojay通过让库用户自己编写switch-case来高速处理这部分。
go-json考虑并实现了一种不同于这些的新方法。我称之为位图字段优化。
每个字符的值范围可以用[256]byte表示。此外,如果结构体的字段数不超过8个,int8类型可以表示每个字段的状态。
换句话说,它具有以下结构:
- 基础(8位):
00000000 - 键"a":
00000001(将键"a"分配给第一位) - 键"b":
00000010(将键"b"分配给第二位) - 键"c":
00000100(将键"c"分配给第三位)
位图结构如下:
| 键索引(0) |
------------------------
0 | 00000000 |
1 | 00000000 |
~~ | |
97 (a) | 00000001 |
98 (b) | 00000010 |
99 (c) | 00000100 |
~~ | |
255 | 00000000 |
你可以将其视为高度为256、宽度为字段名中最大字符串长度的位图。
换句话说,可以用以下类型表示:
[maxFieldKeyLength][256]int8
解码字段字符时,通过参考预先构建的位图来检查相应字符是否存在,如下所示:
var curBit int8 = math.MaxInt8 // 11111111
c := char(buf, cursor)
bit := bitmap[keyIdx][c]
curBit &= bit
if curBit == 0 {
// 未找到字段
}
如果直到字段字符串结束curBit都不为0,那么该字符串可能命中了其中一个字段。
但是,如果解码的字符串比字段字符串短,可能会出现误判。
- 输入:
{"a":1}
type T struct {
X int `json:"abc"`
}
※ 由于a比abc短,可以在字段字符结束前解码而不使curBit为0。
不用担心。在这种情况下,通过比较a的字符串长度与abc的字符串长度,你可以判断是否命中,所以没有问题。
最后,计算设置为1的位的位置并获取相应的值,就完成了。
使用这种技术,只需位操作和对切片的访问就可以进行字段查找。
go-json对9个及以上、16个及以下的字段使用类似的技术。此时,位图构造为[maxKeyLen][256]int16类型。
目前,除了字段数量的限制外,当字段名的最大长度较长(具体来说,64字节或更多)时,出于节省内存使用的考虑,不会执行此优化。
其他
我还进行了许多其他优化。我会找时间写about它们。如果你对这里写的内容或其他优化有任何问题,请访问gophers.slack.com上的#go-json频道。
参考
关于go-json的故事,以下文章仅有日语版本:
- https://speakerdeck.com/goccy/zui-su-falsejsonraiburariwoqiu-mete
- https://engineering.mercari.com/blog/entry/1599563768-081104c850/
寻找赞助商
我正在为这个库寻找赞助商。这个库是我在业余时间作为个人项目开发的。如果你在项目中使用这个库时需要快速响应或问题解决,请注册成为赞助商。我将尽可能合作。当然,这个库是以MIT许可证开发的,所以你可以免费自由使用它。
许可证
MIT









