


欢迎使用 H2O LLM Studio ,一个为调整最先进的大型语言模型(LLM)而设计的框架和零代码图形用户界面 (GUI)。
目录
- 使用 H2O LLM Studio,您可以
- 快速入门
- 新功能
- 安装
- 运行 H2O LLM Studio GUI
- 使用 Docker 运行 H2O LLM Studio GUI(夜间版本)
- 通过自建 Docker 镜像运行 H2O LLM Studio GUI
- 使用命令行界面(CLI)运行 H2O LLM Studio
- 数据格式和示例数据
- 训练您的模型
- 示例:通过 CLI 运行 OASST 数据
- 模型检查点
- 文档
- 贡献
- 许可证
使用 H2O LLM Studio,您可以
- 简单而高效地调整 LLMs 无需任何编码经验。
- 使用专为大型语言模型设计的 图形用户界面 (GUI) 。
- 使用大量超参数调整任意 LLM。
- 使用最新的微调技术,例如 低秩适配 (LoRA)和 8 位模型训练,内存占用较低。
- 使用强化学习 (RL) 微调您的模型(实验性)
- 使用先进的评估指标来判断模型生成的答案。
- 以可视化的方式跟踪和比较模型性能。此外,还可以使用 Neptune 和 W&B 集成。
- 与您的模型聊天并获取即时反馈。
- 轻松将您的模型导出到 Hugging Face Hub 并与社区分享。
快速入门
有问题、讨论或只是想闲聊,请加入我们的 Discord!
我们提供了几种快速入门的方法。
使用 CLI 微调 LLM:


新功能
- PR 788 新的因果回归建模问题类型允许使用 LLM 训练单目标回归数据。
- PR 747 完全删除 RLHF,支持 DPO/IPO/KTO 优化。
- PR 741 取消分开设置提示和答案的最大长度,改为单一
max_length设置,更好地模拟transformers的chat_template功能。 - PR 592 新增
KTOPairLoss用于 DPO 建模,允许使用简单的偏好数据训练模型。数据目前需要手动准备,将正负示例随机匹配成对。 - PR 592 开始逐步淘汰 RLHF,支持 DPO/IPO 优化。训练已禁用,但旧实验仍可查看。RLHF 将在未来版本中完全删除。
- PR 530 引入了 DPO/IPO 优化的新问题类型。这种优化技术可以替代 RLHF。
- PR 288 引入 Deepspeed 分步训练,允许在多 GPU 机器上训练更大的模型。需要 NVLink。此功能取代 FSDP 并提供更多灵活性。Deepspeed 需要系统安装 cudatoolkit,我们推荐使用版本 12.1。见推荐的安装方式。
- PR 449 因果分类建模的新问题类型允许使用 LLM 训练二元和多类模型。
- PR 364 用户机密信息现在处理得更加安全和灵活。增加了使用 'keyring' 库处理机密信息的支持。尝试自动迁移用户设置。
请注意,由于当前开发迅速,我们无法保证新功能的完全向后兼容。因此,我们建议将框架版本固定在您进行实验时使用的版本。要重置,请删除/备份您的 data 和 output 文件夹。
安装
H2O LLM Studio 要求运行 Ubuntu 16.04+ 并至少配备一个 Nvidia 驱动版本 >= 470.57.02 的 Nvidia GPU 的机器。对于更大的模型,我们推荐至少 24GB 的 GPU 内存。
有关安装先决条件的更多信息,请参阅文档中的设置 H2O LLM Studio 指南。
有关不同 GPU 性能比较的信息,请参阅文档中的 H2O LLM Studio 性能 指南。
推荐的安装方法
推荐使用 pipenv 并结合 Python 3.10 安装 H2O LLM Studio。在 Ubuntu 16.04+ 上安装 Python 3.10,请执行以下命令:
系统安装(Python 3.10)
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install python3.10
sudo apt-get install python3.10-distutils
curl -sS https://bootstrap.pypa.io/get-pip.py | python3.10
安装 NVIDIA 驱动(如有必要)
如果要在运行 Ubuntu 的“裸机”上部署,可能需要安装所需的 Nvidia 驱动和 CUDA。以下命令演示了如何获取运行 Ubuntu 20.04 的机器的最新驱动。可以根据自己的操作系统进行更新。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-ubuntu2004-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2004-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
或者,您可以在 cuda 环境中安装 cudatoolkits:
conda create -n llmstudio python=3.10
conda activate llmstudio
conda install -c "nvidia/label/cuda-12.1.0" cuda-toolkit
虚拟环境
我们提供了几种设置必要的 python 环境的方式。
Pipenv 虚拟环境
以下命令将使用 pipenv 创建一个虚拟环境,并使用 pipenv 安装依赖项:
make setup
如果在安装 flash_attn 包时遇到问题,请考虑运行
make setup-no-flash
此命令将在没有 flash_attn 包的情况下安装依赖项。注意,这将禁用 Flash Attention 2 的使用,模型训练会变慢并消耗更多内存。
Nightly Conda 虚拟环境
您还可以设置一个 conda 虚拟环境,该环境也可以偏离推荐设置。Makefile 包含一个命令 setup-conda-nightly,该命令会安装一个带有 CUDA 12.4 和当前 nightly PyTorch 的全新 conda 环境。
使用 requirements.txt
如果您希望使用其他虚拟环境,也可以使用 requirements.txt 文件安装依赖:
pip install -r requirements.txt
pip install flash-attn==2.6.1 --no-build-isolation # 可选,用于 Flash Attention 2
运行 H2O LLM Studio 图形界面
您可以使用以下命令启动 H2O LLM Studio:
make llmstudio
该命令将启动 H2O wave 服务器和应用程序。 导航至 http://localhost:10101/(推荐使用 Chrome 浏览器)访问 H2O LLM Studio 并开始微调您的模型!
如果您在 Pipenv 以外的自定义环境中运行 H2O LLM Studio,您需按以下方式启动应用程序:
H2O_WAVE_MAX_REQUEST_SIZE=25MB \
H2O_WAVE_NO_LOG=true \
H2O_WAVE_PRIVATE_DIR="/download/@output/download" \
wave run app
如果您使用的是每夜版 conda 环境,可以运行 make llmstudio-conda。
使用每夜构建 Docker 运行 H2O LLM Studio 图形界面
首先按照 NVIDIA Containers 的说明安装 Docker。确保按说明在您的机器上安装 nvidia-container-toolkit。
H2O LLM Studio 镜像存储在 h2oai GCR vorvan 容器库中。
mkdir -p `pwd`/llmstudio_mnt
# 如果您有之前版本的缓存,请确保拉取最新镜像
docker pull gcr.io/vorvan/h2oai/h2o-llmstudio:nightly
# 运行容器
docker run \
--runtime=nvidia \
--shm-size=64g \
--init \
--rm \
--it \
-u `id -u`:`id -g` \
-p 10101:10101 \
-v `pwd`/llmstudio_mnt:/home/llmstudio/mount \
-v ~/.cache:/home/llmstudio/.cache \
gcr.io/vorvan/h2oai/h2o-llmstudio:nightly
导航至 http://localhost:10101/(推荐使用 Chrome 浏览器)访问 H2O LLM Studio 并开始微调您的模型!
(注:其他有用的 docker 命令包括 docker ps 和 docker kill。)
构建您自己的 Docker 镜像运行 H2O LLM Studio 图形界面
docker build -t h2o-llmstudio .
mkdir -p `pwd`/llmstudio_mnt
docker run \
--runtime=nvidia \
--shm-size=64g \
--init \
--rm \
--it \
-u `id -u`:`id -g` \
-p 10101:10101 \
-v `pwd`/llmstudio_mnt:/home/llmstudio/mount \
-v ~/.cache:/home/llmstudio/.cache \
h2o-llmstudio
或者,您可以使用我们自托管的 Docker 镜像来运行 H2O LLM Studio 图形界面,可在 此处 获取。
使用命令行界面 (CLI) 运行 H2O LLM Studio
您也可以使用命令行界面 (CLI) 运行 H2O LLM Studio,并指定包含所有实验参数的配置 .yaml 文件。要使用 CLI 微调,首先运行 make shell 启动 pipenv 环境,然后使用以下命令:
python train.py -Y {path_to_config_yaml_file}
要在多 GPU 的 DDP 模式下运行,请运行以下命令:
bash distributed_train.sh {NR_OF_GPUS} -Y {path_to_config_yaml_file}
默认情况下,框架将在前 k 个 GPU 上运行。如果您想指定特定的 GPU 运行,请在命令前使用 CUDA_VISIBLE_DEVICES 环境变量。
要与训练好的模型进行互动聊天,请使用以下命令:
python prompt.py -e {experiment_name}
其中 experiment_name 是您想聊天的实验的输出文件夹(见配置)。
与 UI 微调的模型也能进行互动聊天。
要将模型发布到 Hugging Face,请使用以下命令:
make shell
python publish_to_hugging_face.py -p {path_to_experiment} -d {device} -a {api_key} -u {user_id} -m {model_name} -s {safe_serialization}
path_to_experiment 是实验的输出文件夹。
device 是运行模型的目标设备,可以是 'cpu' 或 'cuda:0'。默认值是 'cuda:0'。
api_key 是 Hugging Face 的 API 密钥。如果用户已登录,可以省略。
user_id 是 Hugging Face 的用户 ID。如果用户已登录,可以省略。
model_name 是要在 Hugging Face 上发布的模型名称,可以省略。
safe_serialization 是一个标志,表示是否使用安全序列化,默认值是 True。
数据格式和示例数据
有关导入您的数据或可用于试验 H2O LLM Studio 的示例数据所需的数据格式的详细信息,请参见 H2O LLM Studio 文档中的 Data format。
训练您的模型
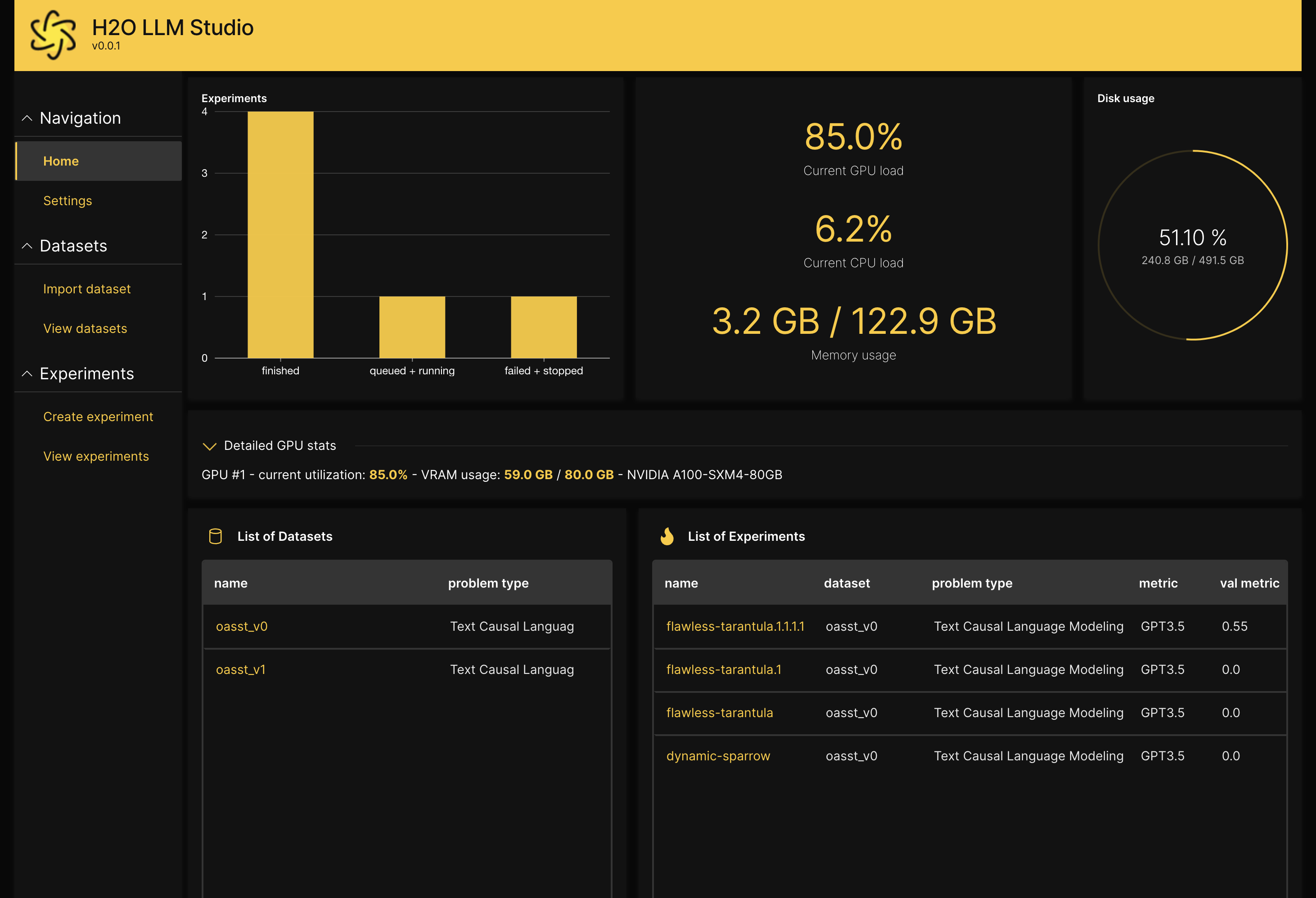
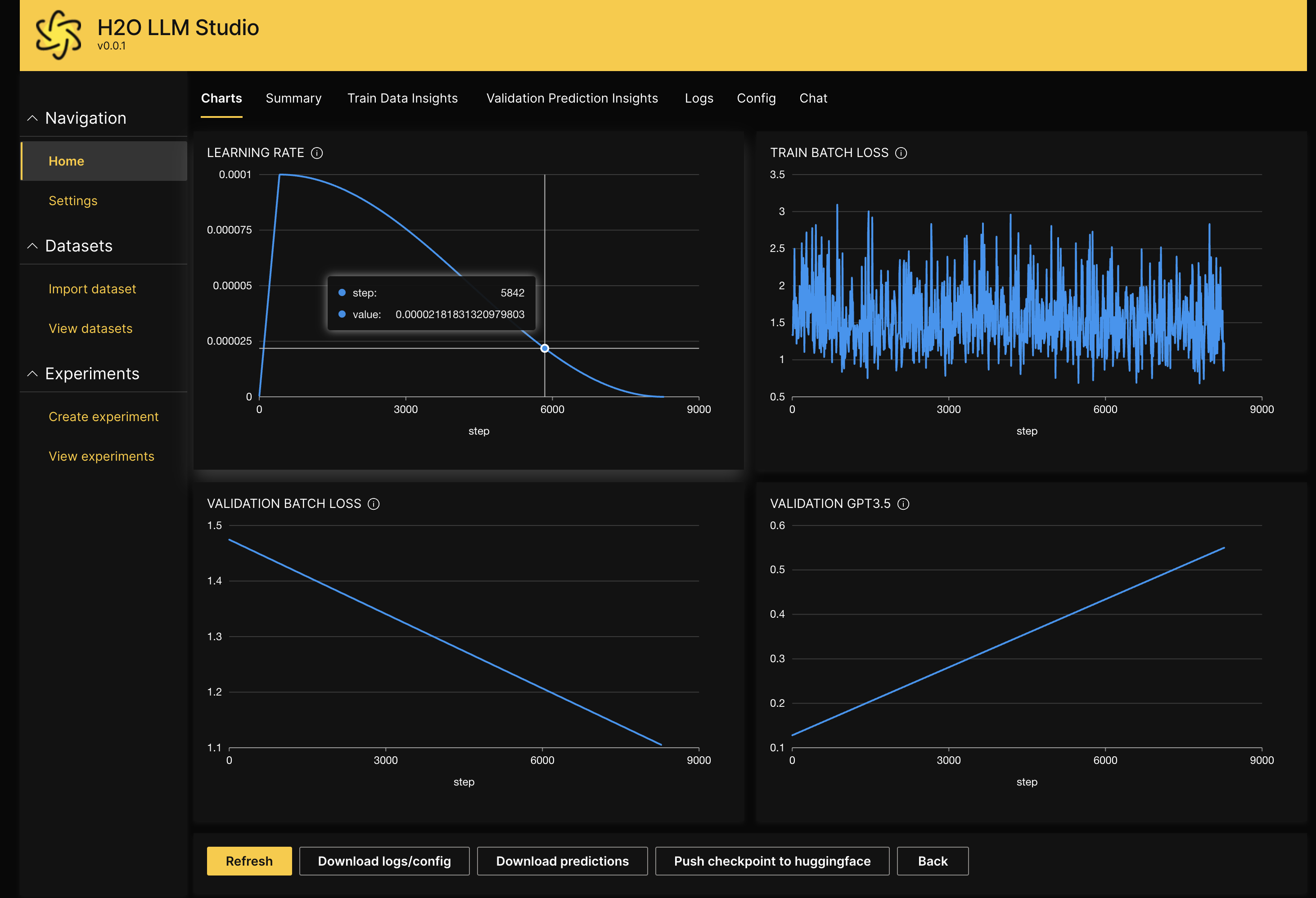
使用 H2O LLM Studio,训练您的大型语言模型既简单又直观。首先,上传您的数据集,然后开始训练您的模型。首先创建实验。然后您可以监控和管理您的实验、比较实验或将模型推送到 Hugging Face 与社区共享。
示例:通过 CLI 运行 OASST 数据
作为示例,您可以通过 CLI 在 OASST 数据上运行实验。有关说明,请参见 H2O LLM Studio 文档中的 Run an experiment on the OASST data 指南。
模型检查点
所有开源数据集和模型均发布在 H2O.ai's Hugging Face 页面 和我们的 H2OGPT 仓库中。
文档
H2O LLM Studio 的详细文档和常见问题 (FAQ) 见 https://docs.h2o.ai/h2o-llmstudio/。如果您希望对文档做出贡献,请导航至此仓库的 /documentation 文件夹并参阅 README.md 了解更多信息。
贡献
我们欢迎对 H2O LLM Studio 项目的贡献。请参阅 CONTRIBUTING.md 文件了解更多信息。
License
H2O LLM Studio 依据 Apache 2.0 许可证授予许可。请参阅 LICENSE 文件获取更多信息。
















