
 访问官网
访问官网 Github
Github Huggingface
Huggingface Hotshot-XL
Hotshot-XL
🌐 立即体验 🃏 模型卡片 💬 Discord




Hotshot-XL是一个人工智能文本到GIF模型,经过训练可与Stable Diffusion XL配合使用。
Hotshot-XL可以使用任何经过微调的SDXL模型生成GIF。这意味着两点:
- 您可以使用任何现有或新微调的SDXL模型制作GIF。
- 如果您想制作个性化主题的GIF,可以加载自己的基于SDXL的LORA,而不必担心微调Hotshot-XL。这非常棒,因为通常找到合适的图像训练数据比找到视频更容易。它也希望能够适应每个人现有的LORA使用/工作流程:) 更多详情请参见此处。
Hotshot-XL与SDXL ControlNet兼容,可以按照您想要的构图/布局制作GIF。请参阅下方的ControlNet部分。
Hotshot-XL经过训练,可以生成1秒长、8帧每秒的GIF。
Hotshot-XL在各种纵横比上进行了训练。为了获得最佳效果,我们建议将基础Hotshot-XL模型与使用512x512图像微调的SDXL模型一起使用。您可以在这里找到我们为512x512分辨率微调的SDXL模型。
🌐 立即体验
在这里亲自试用Hotshot-XL:https://www.hotshot.co
或者,如果您想在本地运行Hotshot-XL,请继续阅读以下部分。
如果您自己运行Hotshot-XL,您将能够对模型有更多的灵活性和控制。举个简单的例子,您可以更改采样器。到目前为止,我们发现Euler-A效果最好,但您可能会发现其他采样器也有有趣的结果。
🔧 设置
环境设置
pip install virtualenv --upgrade
virtualenv -p $(which python3) venv
source venv/bin/activate
pip install -r requirements.txt
下载Hotshot-XL权重
# 确保已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://huggingface.co/hotshotco/Hotshot-XL
或访问https://huggingface.co/hotshotco/Hotshot-XL
下载我们微调的SDXL模型(或使用您自己的SDXL)
- 注意:为了最大化数据和训练效率,Hotshot-XL在512x512分辨率附近的各种纵横比上进行了训练。为了获得最佳效果,我们建议将基础Hotshot-XL模型与使用512x512左右分辨率图像微调的SDXL模型一起使用。您可以在下方下载我们使用512x512分辨率图像训练的SDXL模型,或者使用您自己的SDXL基础模型。
# 确保已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://huggingface.co/hotshotco/SDXL-512
或访问https://huggingface.co/hotshotco/SDXL-512
🔮 推理
文本到GIF
python inference.py \
--prompt="一只斗牛犬坐在宇宙飞船的船长椅上,高清,高质量" \
--output="output.gif"
预期效果:
| 提示词 | 大脚怪潜水 | 骆驼吸烟 | 麦当劳叔叔坐在梳妆台前涂口红 | 德雷克舔嘴唇,透过窗户盯着纸杯蛋糕 |
|---|---|---|---|---|
| 输出 |  |  | 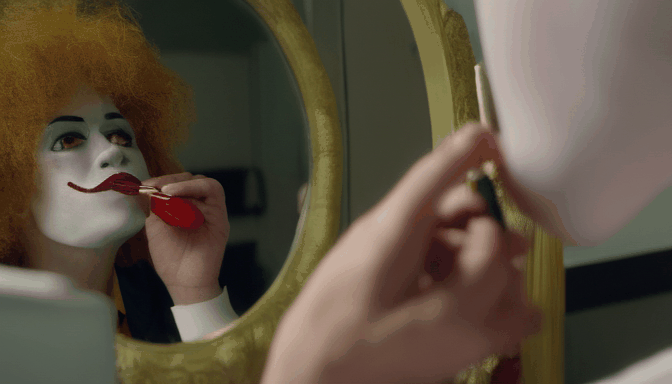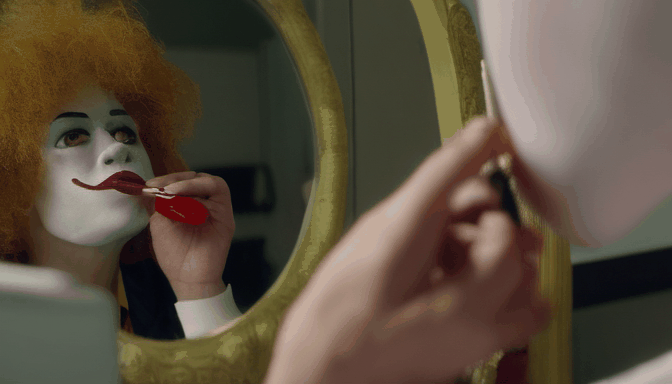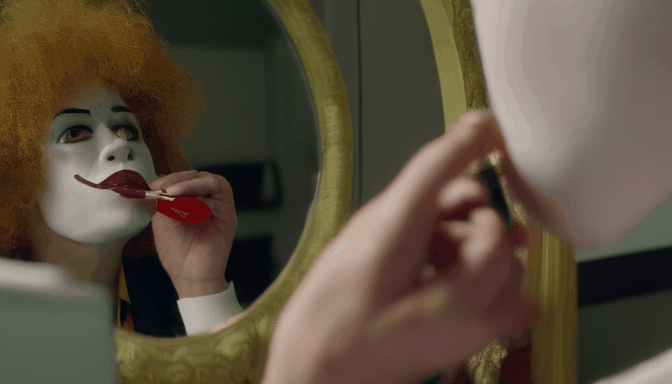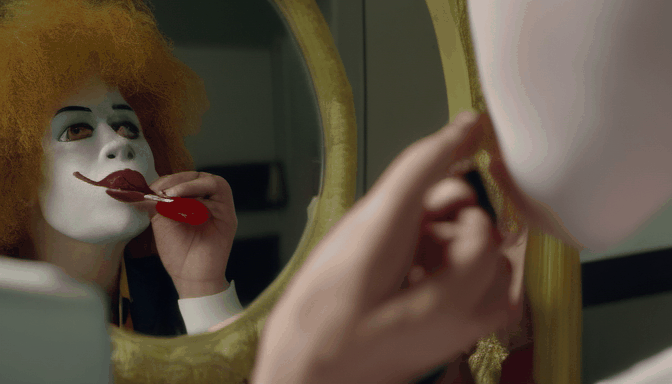 |  |
使用个性化LORA生成文本到GIF
python inference.py \
--prompt="一只斗牛犬坐在宇宙飞船的船长椅上,高清,高质量" \
--output="output.gif" \
--spatial_unet_base="path/to/stabilityai/stable-diffusion-xl-base-1.0/unet" \
--lora="path/to/lora"
预期效果:
注意:以下输出使用DDIMScheduler。
| 提示词 | sks 人对着可比日光大喊 | sks 人亲吻科米蛙 | sks 人穿着燕尾服举着香槟杯,背景有烟花,高清,高质量,4K |
|---|---|---|---|
| 输出 |  |  |  |
使用ControlNet的文本到GIF转换
python inference.py \
--prompt="一个女孩上下跳跃并挥舞拳头,高清,高质量" \
--output="output.gif" \
--control_type="depth" \
--gif="https://media1.giphy.com/media/v1.Y2lkPTc5MGI3NjExbXNneXJicG1mOHJ2dzQ2Y2JteDY1ZWlrdjNjMjl3ZWxyeWFxY2EzdyZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/YOTAoXBgMCmFeQQzuZ/giphy.gif"
默认情况下,Hotshot-XL将从您的源GIF中创建关键帧,使用8个等间距帧,并将关键帧裁剪为默认宽高比。要进行更精细的控制,请了解如何改变宽高比和改变帧率/长度。
Hotshot-XL目前支持一次使用一个ControlNet模型;支持多ControlNet将会是令人兴奋的。
预期效果:
| 提示词 | 皮克斯风格的女孩竖起两个大拇指,开心,高质量,8K,3D,动画迪士尼渲染 | 基努里维斯举着写有"救命"的牌子,高清,高质量 | 一个女人在笑,高清,高质量 | 贝拉克·奥巴马用双手做出彩虹,前面有"魔法"一词,身穿蓝白条纹连帽衫,高清,高质量 |
|---|---|---|---|---|
| 输出 |  |  |  |  |
| 控制 |  |  |  |  |
改变宽高比
- 注意:基础SDXL模型经过训练,最适合创建1024x1024分辨率左右的图像。为了最大化数据和训练效率,Hotshot-XL在512x512分辨率左右的宽高比进行了训练。请参阅附加说明以了解基础Hotshot-XL模型训练的宽高比列表。
与SDXL一样,Hotshot-XL使用宽高比分组在各种宽高比下进行了训练,并包括对SDXL参数如目标大小和原始大小的支持。这意味着您可以仅使用基础Hotshot-XL模型就能创建多种不同宽高比和分辨率的GIF。
python inference.py \
--prompt="一只斗牛犬坐在宇宙飞船的船长椅上,高清,高质量" \
--output="output.gif" \
--width=<宽度> \
--height=<高度>
预期效果:
| 512x512 | 672x384 | 384x672 | |
|---|---|---|---|
| 一只猴子弹吉他,自然镜头,高清,高质量 |  |  |  |
改变帧率和长度(实验性)
默认情况下,Hotshot-XL经过训练可以生成1秒长、8FPS的GIF。如果您想尝试生成不同帧率和时长的GIF,可以尝试使用video_length和video_duration参数。
video_length设置帧数。默认值为8。
video_duration设置输出GIF的运行时间(以毫秒为单位)。默认值为1000。
请注意,在修改这些参数时,您应该预期结果会不稳定或"抖动",因为模型仅使用1秒长度、每秒8帧的视频进行训练。您可以通过微调Hotshot-XL来改善不同时长和帧率结果的稳定性。如果您这样做了,请告诉我们!
python inference.py \
--prompt="一只斗牛犬坐在宇宙飞船的船长椅上,高清,高质量" \
--output="output.gif" \
--video_length=16 \
--video_duration=2000
仅使用空间层
Hotshot-XL经过训练可以与SDXL一起生成GIF。如果您只想生成一张图片,只需在推理调用中设置video_length=1,Hotshot-XL的时间层就会被忽略,正如您所期望的那样。
python inference.py \
--prompt="一只斗牛犬坐在宇宙飞船的船长椅上,高清,高质量" \
--output="output.jpg" \
--video_length=1
其他注意事项
支持的宽高比
Hotshot-XL在以下宽高比下进行了训练;要可靠地生成这些宽高比范围之外的GIF,您需要使用目标宽高比分辨率的视频对Hotshot-XL进行微调。
| 宽高比 | 尺寸 |
|---|---|
| 0.42 | 320 x 768 |
| 0.57 | 384 x 672 |
| 0.68 | 416 x 608 |
| 1.00 | 512 x 512 |
| 1.46 | 608 x 416 |
| 1.75 | 672 x 384 |
| 2.40 | 768 x 320 |
💪 微调
以下部分与使用额外的文本/视频对来微调Hotshot-XL时间模型有关。如果您想生成个性化概念/主题的GIF,我们建议不要微调Hotshot-XL,而是训练您自己的基于SDXL的LORA,然后直接加载它们。
微调Hotshot-XL
数据集准备
fine_tune.py脚本期望您的样本结构如下:
fine_tune_dataset
├── sample_001
│ ├── 0.jpg
│ ├── 1.jpg
│ ├── 2.jpg
...
...
│ ├── n.jpg
│ └── prompt.txt
每个样本目录应包含您的n个关键帧和一个包含提示的prompt.txt文件。
最终的检查点将保存到output_dir。
我们发现每隔一段时间将验证GIF发送到Weights & Biases很有用。如果您选择使用Weights & Biases进行验证,可以通过validate_every_steps参数设置运行频率。
accelerate launch fine_tune.py \
--output_dir="<OUTPUT_DIR>" \
--data_dir="fine_tune_dataset" \
--report_to="wandb" \
--run_validation_at_start \
--resolution=512 \
--mixed_precision=fp16 \
--train_batch_size=4 \
--learning_rate=1.25e-05 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--save_n_steps=20 \
--validate_every_steps=50 \
--vae_b16 \
--gradient_checkpointing \
--noise_offset=0.05 \
--snr_gamma \
--test_prompts="一个男人坐在咖啡馆的桌子旁,他微笑着与另一个男人握手问好"
📝 未来工作
我们对改进Hotshot-XL有许多令人兴奋的方式。例如:
- 在更高帧率下微调Hotshot-XL,以创建更长/更高帧率的GIF
- 在更高分辨率下微调Hotshot-XL,以创建更高分辨率的GIF
- 训练潜在空间升采样器的时间层,以生成更高分辨率的GIF
- 训练一个以图像为条件的"帧预测"模型,以生成更连贯、更长的GIF
- 为VAE训练时间层,以减少输出中的闪烁/抖动
- 支持多重ControlNet,以更好地控制GIF生成
- 训练并集成不同的ControlNet模型,以进一步控制GIF生成(更精细的面部表情控制将非常酷)
- 将Hotshot-XL移植到AITemplate,以实现更快的推理时间
我们💗开源社区的贡献!如果您对这些改进或其他任何内容感兴趣,请在问题或PR中告诉我们!
📚 BibTeX
@software{Mullan_Hotshot-XL_2023,
author = {Mullan, John and Crawbuck, Duncan and Sastry, Aakash},
license = {Apache-2.0},
month = oct,
title = {{Hotshot-XL}},
url = {https://github.com/hotshotco/hotshot-xl},
version = {1.0.0},
year = {2023}
}
🙏 致谢
文本到视频模型正在快速改进,Hotshot-XL的开发受到以下令人惊叹的工作和团队的极大启发:
我们希望发布这个模型/代码库能帮助社区以开放和负责任的方式继续推动这些创意工具向前发展。










