

标题和故事文本的语义搜索
tldrstory 是一个针对故事相关标题和文本内容的语义搜索应用。tldrstory应用零样本标记技术处理文本,这使得内容可以被动态分类。该框架还构建了一个txtai索引,支持文本相似度搜索。定制化的 Streamlit 应用和 FastAPI 后端服务允许用户查看和分析处理的数据。
tldrstory 有一篇对应的 Medium 文章,涵盖了此 README 中的概念和更多内容。请查阅!
示例
以下链接是使用 tldrstory 构建的示例应用程序。
安装
最简单的安装方法是通过 pip 和 PyPI
pip install tldrstory
你也可以直接从 GitHub 安装 tldrstory。建议使用 Python 虚拟环境。
pip install git+https://github.com/neuml/tldrstory
支持 Python 3.8 以上版本
请参阅 此链接 以帮助解决特定环境的安装问题。
配置应用
安装完成后,必须配置应用才能运行。tldrstory 应用程序由三个独立进程组成:
- 索引
- API 后端
- Streamlit 应用
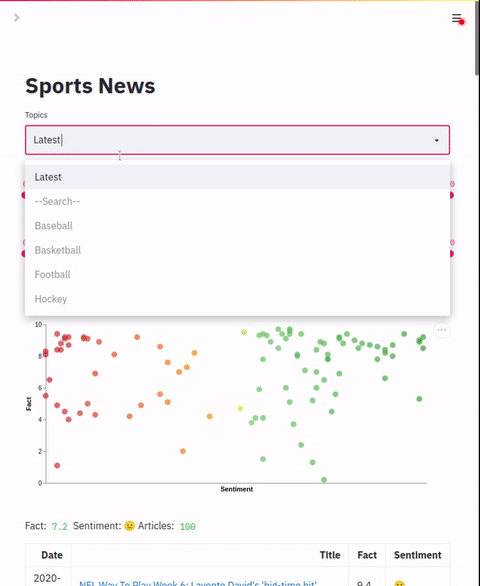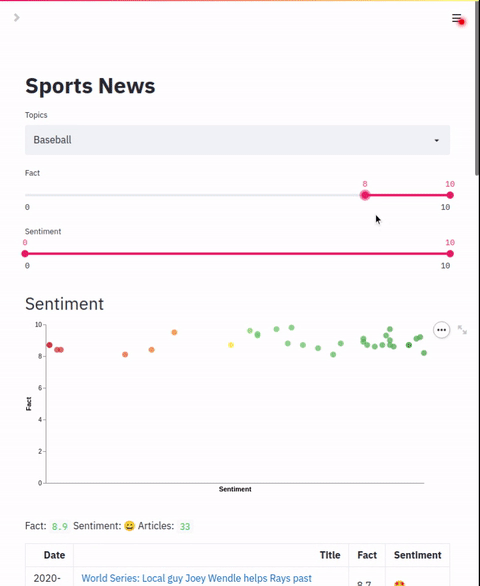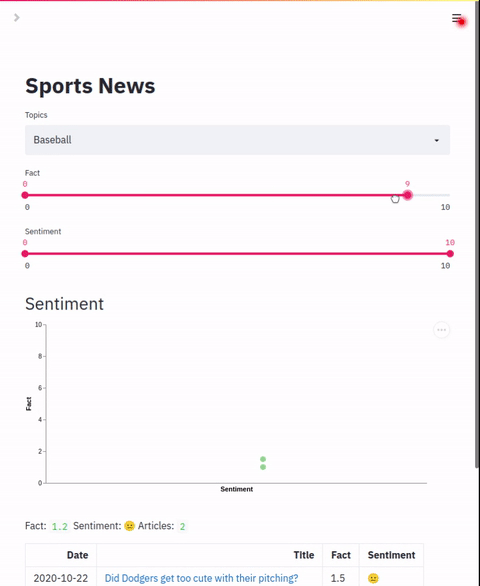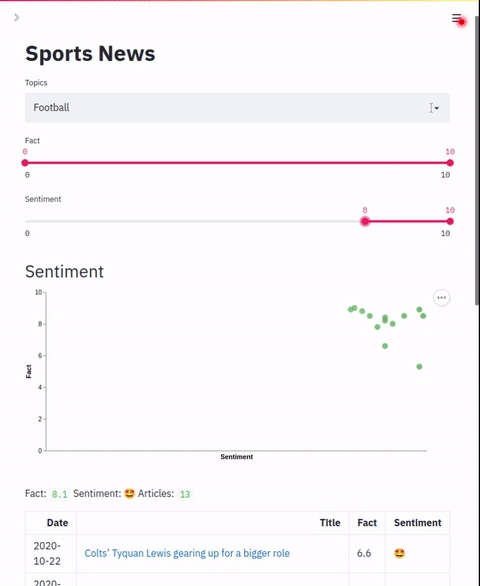
本节将展示如何启动“体育新闻”应用。
- 下载“体育新闻”应用配置。
mkdir sports
wget https://raw.githubusercontent.com/neuml/tldrstory/master/apps/sports/app.yml -O sports/app.yml
wget https://raw.githubusercontent.com/neuml/tldrstory/master/apps/sports/api.yml -O sports/api.yml
wget https://raw.githubusercontent.com/neuml/tldrstory/master/apps/sports/index-simple.yml -O sports/index.yml
wget https://raw.githubusercontent.com/neuml/tldrstory/master/src/python/tldrstory/app.py -O sports/app.py
- 启动索引进程。
python -m tldrstory.index sports/index.yml
- 启动 API 进程。
CONFIG=sports/api.yml API_CLASS=tldrstory.api.API uvicorn "txtai.api:app" &
- 启动 Streamlit。
streamlit run sports/app.py sports/app.yml "Sports" "🏆"
- 打开一个网页浏览器,访问 http://localhost:8501
自定义来源
tldrstory 支持通过 RSS 和 Reddit API 读取数据。可以定义和配置其他数据来源。
以下示例显示了一个自定义数据源定义。neuspo 是一个实时体育事件和新闻应用。 该数据源将 4 个预定义条目加载到文章数据库中。
from tldrstory.source.source import Source
class Neuspo(Source):
"""
文章具有以下模式:
uid - 唯一 ID
source - 来源名称
date - 文章日期
title - 文章标题
url - 数据参考 URL
entry - 条目日期
"""
def run(self):
# 创建的文章列表
articles = []
articles.append(self.article("0", "Neuspo", self.now(), "老鹰队以 22-21 战胜巨人队",
"https://neuspo.com/stream/34952e3919d685982c17735018b0197f", self.now()))
articles.append(self.article("1", "Neuspo", self.now(), "巨人队以 22-21 败给老鹰队",
"https://t.co/e9FFgo0wgR?amp=1", self.now()))
articles.append(self.article("2", "Neuspo", self.now(), "光线队以 6 比 4 击败道奇队",
"https://neuspo.com/stream/6cb820b3ebadc086aa36b5cc4a0f575d", self.now()))
articles.append(self.article("3", "Neuspo", self.now(), "道奇队第二场比赛以 6-4 落败",
"https://t.co/1hEQAShVnP?amp=1", self.now()))
return articles
让我们重新运行上面的步骤,使用 neuspo 作为数据源。首先删除 sports/data 目录,以确保我们创建一个新的数据库。然后我们可以下载上面的代码到 sports 目录。
# 运行前删除 sports/data 目录
wget https://gist.githubusercontent.com/davidmezzetti/9a6064d9a741acb89bd46eba9f906c26/raw/7058e97da82571005b2654b4ab908f25b9a04fe2/neuspo.py -O sports/neuspo.py
编辑 sports/index.yml 并删除 rss 部分。替换为以下内容。
# neuspo 的自定义数据源
source: sports.neuspo.Neuspo
现在重新运行上面配置应用中的步骤 2–4。
参数参考
以下部分定义了 tldrstory 应用的每个过程的配置参数。
索引
配置内容索引。目前支持通过 Reddit API、RSS 和自定义用户定义的数据源拉取数据。
名称
name: string
应用名称
调度
schedule: string
Cron 风格的字符串,启用索引工作的计划运行。请参阅此链接以获取有关 Cron 字符串的更多信息。
数据源
数据源配置。
reddit.subreddit: 要拉取的 subreddit 名称
reddit.sort: 排序类型
reddit.time: 时间范围
reddit.queries: 要运行的文本查询列表
运行一系列 Reddit API 查询。需要创建和配置一个 Reddit API 密钥才能使用此方法。身份验证参数可以设置在环境中或 praw.ini 文件中。有关设置 Reddit API 帐户的更多信息,请参阅此链接,只需只读访问权限。
有关如何配置查询设置的更多详细信息,请参阅PRAW 文档。
rss
rss: RSS url 列表
读取一系列 RSS 源并为找到的每个文章链接构建文章。
源
source: string
配置自定义来源。此参数以字符串的形式获取完整类路径,例如 "tldrstory.source.rss.RSS"
自定义源可以使用任何具有日期、文本字符串和参考 URL 的数据。有关如何创建自定义源的信息,请参阅 source.py 中的文档。rss.py 和 reddit.py 是示例实现。
忽略
ignore: url 模式列表
要忽略的 URL 模式列表。支持字符串和正则表达式。
标签
labels: dict
零样本分类器的标签配置。此配置设置类别及其对应主题值。
示例:
labels:
topic:
values: [标签1, 标签2]
上面的示例配置了类别 “topic” 具有两个可能的标签 “标签1” 和 “标签2”。在这里可以设置任何标签,大规模 NLP 模型将用于将输入文本分类到这些标签中。
路径
path: string
存储模型输出的位置,如果路径不存在会自动创建。
嵌入
embeddings: dict
配置用于搜索主题的 txtai 索引。有关更多详细信息,请参阅 txtai 配置。
API
配置 FastAPI 支持的接口以拉取索引数据。
路径
path: string
模型索引的路径。
应用
默认应用由 Streamlit 驱动并通过 YAML 配置文件配置。配置文件设置应用名称、用于拉取内容的 API 端点和组件配置。定制的 Streamlit 应用或其他任何应用可以代替此应用直接从 API 端点拉取内容。
名称
name: string
应用名称
api
api: url
用于拉取内容的 API 端点。
布局
description: string
用于构建侧边栏描述的 Markdown 字符串。
查询
queries.name: 查询下拉框头部
queries.values: 查询下拉框中使用的值列表
配置查询下拉框。这应该是一个预定义查询的列表。如果包含 "Latest" 的值,它将查询最近的 N 篇文章。如果包含 "--Search--" 的值,它将显示另一个文本框以允许输入自定义查询。
过滤器
filters: 列表
滑块过滤器列表。这应该映射到索引部分配置的零样本标签。
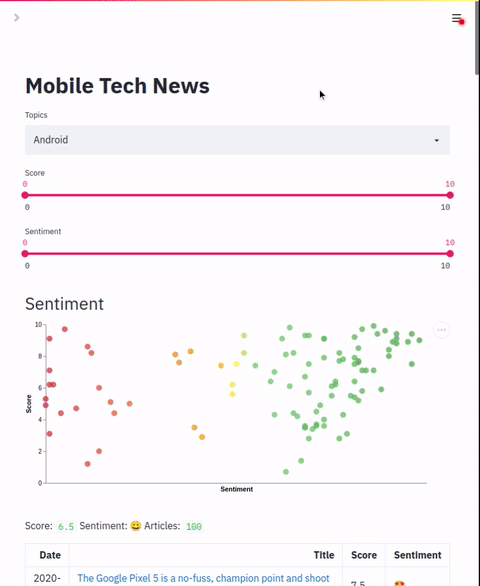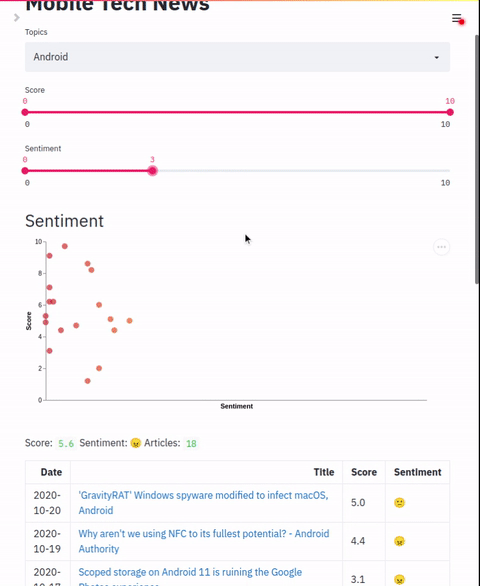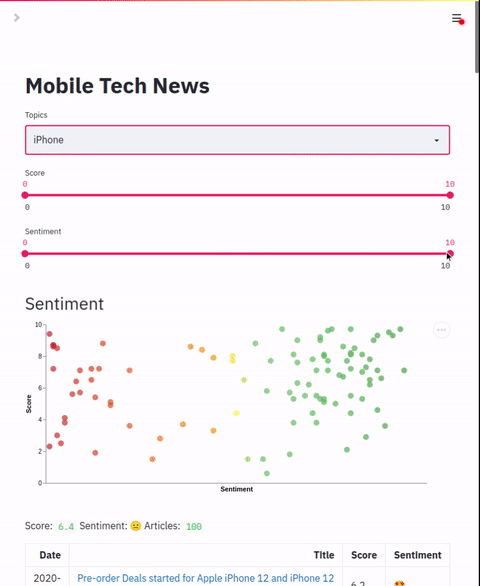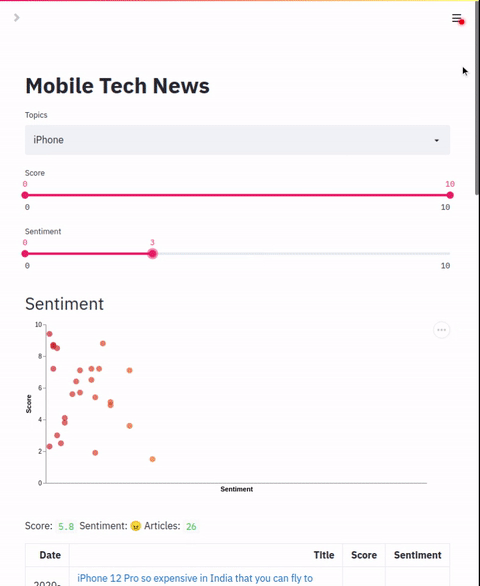
图表
chart.name: 图表名称
chart.x: 图表 x 轴列
chart.y: 图表 y 轴列
chart.scale: 颜色缩放列表
chart.colors: 颜色列表
允许配置一个散点图,该图用来绘制和应用标签的两点。此图表可用于绘制和应用颜色到应用的标签。
表格
"column name": 动态颜色范围
显示结果详细信息的数据表。除了默认列外,此部分允许根据应用的零样本标签添加附加列。默认模式是显示标签的数值,但也可以应用一系列文本标签。
例如:
- [0, 5.0, 标签1, "color: #F00"]
- [5.0, 10.0, 标签2, "color: #0F0"]
上述将为值在 0 到 5 之间的输出红色文字 "标签1"。值在 5 到 10 之间的输出绿色文字 "标签2"。











