

工作坊:2小时将pgvector部署至生产环境
创建一个生产就绪的MVP,用于安全地与您的文档进行聊天。
☑️ 功能
- 互动聊天界面: 利用OpenAI的GPT模型和检索增强生成(RAG)功能与您的文档互动。
- 第三方登录: 集成一键第三方登录,支持我们18个身份验证提供商和用户/密码。
- 文档存储: 安全上传、存储和检索用户上传的文档。
- REST API: 提供一个灵活的REST API,我们将使用它来构建互动的前端。
- 行级别安全: 使用生产就绪的行级别安全保护您的所有用户数据。
🎥 YouTube视频
整个工作坊已被录制为YouTube视频。可以在这里观看:
https://www.youtube.com/watch?v=ibzlEQmgPPY
📄 工作坊说明
感谢您的参与!让我们开始吧。

-
克隆仓库: 在标签
step-1克隆此仓库:git clone -b step-1 https://github.com/supabase-community/chatgpt-your-files.git这将自动克隆到第1步,即我们的起点。
-
Git检查点: 工作坊分为若干步骤(git标签)。每个主要功能我们都设有一个步骤。
您可以跟随演示者的现场进度。当需要跳到下一步时,运行:
git stash push -u # 储存您的工作目录 git checkout step-X # 跳到检查点(用步骤编号替换X) -
逐步指南: 这些步骤按行详细说明。可以跟随使用下面的步骤进行操作。
🧱 前提条件
- Unix系操作系统(如果是Windows,请使用WSL2)
- Docker
- Node.js 18+
💿 示例数据
该仓库包含3个示例Markdown文件,我们将使用它们测试应用程序:
./sample-files/roman-empire-1.md
./sample-files/roman-empire-2.md
./sample-files/roman-empire-3.md
🪜 逐步指南
跳转至某一步骤:
第0步 - 设置 (可选)
第0步 - 设置
使用此命令跳到step-0检查点。
git checkout step-0
第0步的开始部分等同于:
npx create-next-app -e with-supabase
如果您想了解我们在create-next-app基础上添加的内容以加快本次工作坊的启动进程,请参考此步骤_(VS Code设置、UI组件/样式/布局)_。否则,请直接跳到step-1。
-
安装Supabase作为开发依赖项。
npm i -D supabase@1.102.0 -
初始化Supabase项目。
npx supabase init -
(可选)设置VSCode环境。
mkdir -p .vscode && cat > .vscode/settings.json <<- EOF { "deno.enable": true, "deno.lint": true, "deno.unstable": false, "deno.enablePaths": [ "supabase" ], "deno.importMap": "./supabase/functions/import_map.json" } EOF -
(可选)设置VSCode推荐扩展。
cat > .vscode/extensions.json <<- EOF { "recommendations": [ "denoland.vscode-deno", "esbenp.prettier-vscode", "dbaeumer.vscode-eslint", "bradlc.vscode-tailwindcss", ], } EOF然后
cmd+shift+p→>显示推荐扩展→ 安装所有_(或您喜欢的)_ -
创建
import_map.json,包含我们Supabase Edge Functions的依赖项。我们将在第2步中详细讨论这一点。cat > supabase/functions/import_map.json <<- EOF { "imports": { "@std/": "https://deno.land/std@0.168.0/", "@supabase/supabase-js": "https://esm.sh/@supabase/supabase-js@2.21.0", "openai": "https://esm.sh/openai@4.10.0", "common-tags": "https://esm.sh/common-tags@1.8.2", "ai": "https://esm.sh/ai@2.2.13", "mdast-util-from-markdown": "https://esm.sh/mdast-util-from-markdown@2.0.0", "mdast-util-to-markdown": "https://esm.sh/mdast-util-to-markdown@2.1.0", "mdast-util-to-string": "https://esm.sh/mdast-util-to-string@4.0.0", "unist-builder": "https://esm.sh/unist-builder@4.0.0", "mdast": "https://esm.sh/v132/@types/mdast@4.0.0/index.d.ts", "https://esm.sh/v132/decode-named-character-reference@1.0.2/esnext/decode-named-character-reference.mjs": "https://esm.sh/decode-named-character-reference@1.0.2?target=deno" } } EOF
搭建前端
我们使用shadcn/ui作为UI组件。
-
初始化
shadcn-ui。npx shadcn-ui@latest init您想使用TypeScript(推荐)吗? 是 您想使用哪种样式? › 默认 您想使用哪种颜色作为基础色? › Slate 您的全局CSS文件在哪里? › › app/globals.css 您想使用CSS变量来设置颜色吗? › 是 tailwind.config.js位于哪里? › tailwind.config.js 配置组件的导入别名:› @/components 配置工具的导入别名:› @/lib/utils 您在使用React服务器组件吗? › 是 -
添加组件。
npx shadcn-ui@latest add button input toast -
安装依赖项。
npm i @tanstack/react-query three-dots -
将应用程序包裹在
<QueryClientProvider>中。 -
构建布局。
第1步 - 存储
使用此命令跳到step-1检查点。
git checkout step-1
我们将从处理文件上传开始。Supabase内置对象存储(由S3提供支持)直接与您的Postgres数据库集成。
安装依赖项
首先安装NPM依赖项。
npm i
设置Supabase堆栈
在Supabase中开发项目时,您可以选择本地开发或直接在云端开发。
本地
-
启动本地版本的Supabase_(在Docker中运行)_。
npx supabase start -
将Supabase URL和公共匿名密钥存储在Next.js的
.env.local中。npx supabase status -o env \ --override-name api.url=
接下来让我们更新 ./app/files/page.tsx 以支持文件上传。
-
在组件顶部设置 Supabase 客户端。
const supabase = createClientComponentClient(); -
在
<Input>的onChange属性中处理文件上传。await supabase.storage .from('files') .upload(`${crypto.randomUUID()}/${selectedFile.name}`, selectedFile);
改进上传 RLS 策略
我们可以改进之前的 RLS 策略,以在上传文件路径中要求 UUID。
-
创建
uuid_or_null()函数。create or replace function private.uuid_or_null(str text) returns uuid language plpgsql as $$ begin return str::uuid; exception when invalid_text_representation then return null; end; $$; -
修改插入策略以检查第一个路径段中的 UUID(Postgres 数组基于1)。
create policy "Authenticated users can upload files" on storage.objects for insert to authenticated with check ( bucket_id = 'files' and owner = auth.uid() and private.uuid_or_null(path_tokens[1]) is not null ); -
将迁移应用到我们的本地数据库。
npx supabase migration up如果你是在云上直接开发,将迁移推送到云端:
npx supabase db push
步骤 2 - 文档
跳转到某个步骤:
使用以下命令跳转到 step-2 检查点。
git stash push -u -m "my work on step-1"
git checkout step-2
接下来我们需要处理文件以用于检索增强生成(RAG)。特别是我们将按标题拆分 Markdown 文档的内容,这将允许我们查询更小和更有意义的部分。
让我们创建一个 documents 和 document_sections 表来存储我们的处理文件。
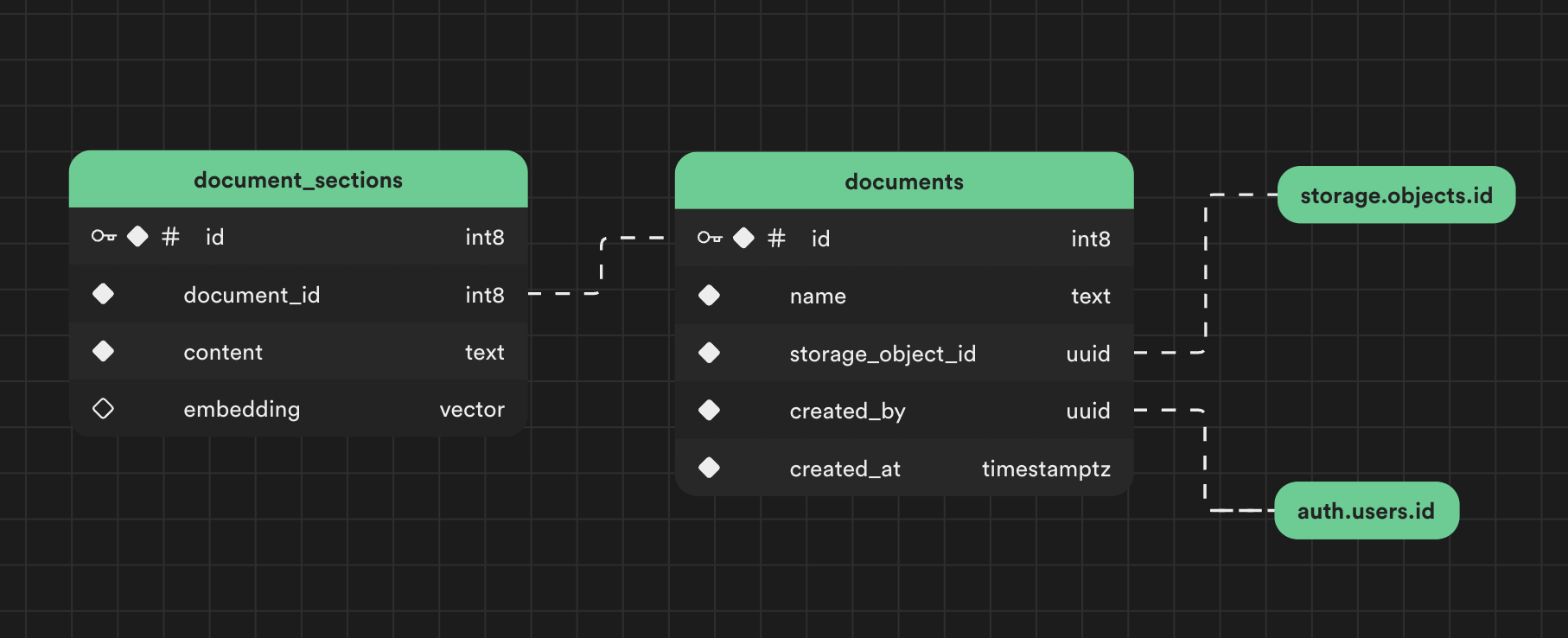
添加新的 SQL 迁移
-
创建迁移文件。
npx supabase migration new documents -
启用
pgvector和pg_net扩展。我们稍后会使用
pg_net发送 HTTP 请求到我们的边缘函数。create extension if not exists pg_net with schema extensions; create extension if not exists vector with schema extensions; -
创建
documents表。create table documents ( id bigint primary key generated always as identity, name text not null, storage_object_id uuid not null references storage.objects (id), created_by uuid not null references auth.users (id) default auth.uid(), created_at timestamp with time zone not null default now() ); -
我们还将创建一个视图
documents_with_storage_path,以便轻松访问存储对象路径。create view documents_with_storage_path with (security_invoker=true) as select documents.*, storage.objects.name as storage_object_path from documents join storage.objects on storage.objects.id = documents.storage_object_id; -
创建
document_sections表。create table document_sections ( id bigint primary key generated always as identity, document_id bigint not null references documents (id), content text not null, embedding vector (384) );注意:自视频发布以来,
on delete cascade被添加为新的迁移,以便document_sections的生命周期与其各自的文档相关联。alter table document_sections drop constraint document_sections_document_id_fkey, add constraint document_sections_document_id_fkey foreign key (document_id) references documents(id) on delete cascade; -
添加 HNSW 索引。
与 IVFFlat 索引不同,HNSW 索引可以立即在空表上创建。
create index on document_sections using hnsw (embedding vector_ip_ops); -
设置 RLS 以控制谁可以访问哪些文档。
alter table documents enable row level security; alter table document_sections enable row level security; create policy "Users can insert documents" on documents for insert to authenticated with check ( auth.uid() = created_by ); create policy "Users can query their own documents" on documents for select to authenticated using ( auth.uid() = created_by ); create policy "Users can insert document sections" on document_sections for insert to authenticated with check ( document_id in ( select id from documents where created_by = auth.uid() ) ); create policy "Users can update their own document sections" on document_sections for update to authenticated using ( document_id in ( select id from documents where created_by = auth.uid() ) ) with check ( document_id in ( select id from documents where created_by = auth.uid() ) ); create policy "Users can query their own document sections" on document_sections for select to authenticated using ( document_id in ( select id from documents where created_by = auth.uid() ) ); -
如果在本地开发,请将
supabase_url密钥添加到./supabase/seed.sql中。我们将在本地环境中使用它来查询我们的边缘函数。select vault.create_secret( 'http://api.supabase.internal:8000', 'supabase_url' );如果你是在云上直接开发,打开 SQL 编辑器 并将其设置为你的 Supabase 项目的 API URL:
select vault.create_secret( '<api-url>', 'supabase_url' );你可以从 API 设置页面 获取项目 API URL。
-
创建一个函数来检索 URL。
create function supabase_url() returns text language plpgsql security definer as $$ declare secret_value text; begin select decrypted_secret into secret_value from vault.decrypted_secrets where name = 'supabase_url'; return secret_value; end; $$; -
创建一个触发器,在插入新文档时处理它们。这将使用
pg_net向我们的边缘函数发送 HTTP 请求(接下来会讲)。create function private.handle_storage_update() returns trigger language plpgsql as $$ declare document_id bigint; result int; begin insert into documents (name, storage_object_id, created_by) values (new.path_tokens[2], new.id, new.owner) returning id into document_id; select net.http_post( url := supabase_url() || '/functions/v1/process', headers := jsonb_build_object( 'Content-Type', 'application/json', 'Authorization', current_setting('request.headers')::json->>'authorization' ), body := jsonb_build_object( 'document_id', document_id ) ) into result; return null; end; $$; create trigger on_file_upload after insert on storage.objects for each row execute procedure private.handle_storage_update(); -
将迁移应用到我们的本地数据库。
npx supabase migration up如果你是在云上直接开发,将迁移推送到云端:
npx supabase db push
process 的边缘函数
-
创建边缘函数文件。
npx supabase functions new process这将创建文件
./supabase/functions/process/index.ts。确保你安装了最新版本的
deno。brew install deno -
首先让我们注意依赖关系如何通过导入映射进行解析 -
./supabase/functions/import_map.json。在 Deno 中不需要导入映射,但它们可以简化导入并保持依赖版本的一致性。我们所有的依赖项都来自 NPM,但由于我们使用的是 Deno,我们从类似 https://esm.sh 或 https Deno.serve(async (req) => { if (!supabaseUrl || !supabaseAnonKey) { return new Response( JSON.stringify({ error: '缺少环境变量。', }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } });
注意:这些环境变量会自动注入到边缘运行时中。即便如此,我们仍然检查它们的存在,这是TypeScript最佳实践(类型缩小)。
-
(可选) 如果你使用VS Code,你可能会被提示缓存已导入的依赖项。你可以按下
cmd+shift+p,然后输入>Deno: Cache Dependencies来完成此操作。 -
创建Supabase客户端,并配置其通过授权头继承原始用户的权限。这样我们可以继续利用我们的RLS策略。
const authorization = req.headers.get('Authorization'); if (!authorization) { return new Response( JSON.stringify({ error: `未传递授权头` }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } const supabase = createClient(supabaseUrl, supabaseAnonKey, { global: { headers: { authorization, }, }, auth: { persistSession: false, }, }); -
从请求体中获取
document_id并进行查询。const { document_id } = await req.json(); const { data: document } = await supabase .from('documents_with_storage_path') .select() .eq('id', document_id) .single(); if (!document?.storage_object_path) { return new Response( JSON.stringify({ error: '未找到已上传的文档' }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } -
使用Supabase客户端通过存储路径下载文件。
const { data: file } = await supabase.storage .from('files') .download(document.storage_object_path); if (!file) { return new Response( JSON.stringify({ error: '下载存储对象失败' }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } const fileContents = await file.text(); -
处理Markdown文件,并将结果小节存储到
document_sections表中。注意:
processMarkdown()已预构建到此存储库中,方便使用。你可以随意阅读其代码,了解它如何拆分Markdown内容。const processedMd = processMarkdown(fileContents); const { error } = await supabase.from('document_sections').insert( processedMd.sections.map(({ content }) => ({ document_id, content, })) ); if (error) { console.error(error); return new Response( JSON.stringify({ error: '保存文档小节失败' }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } console.log( `已保存文件'${document.name}'的${processedMd.sections.length}个小节` ); -
返回成功响应。
return new Response(null, { status: 204, headers: { 'Content-Type': 'application/json' }, }); -
如果本地开发,打开一个新终端并启动边缘函数。
npx supabase functions serve注意:本地边缘函数会自动作为
npx supabase start的一部分提供服务,但此命令还允许我们监视其日志。如果你直接在云端开发,请部署你的边缘函数:
npx supabase functions deploy
在前端显示文档
让我们更新./app/files/page.tsx以列出上传的文档。
-
在组件顶部,使用
useQuery钩子获取文档:const { data: documents } = useQuery(['files'], async () => { const { data, error } = await supabase .from('documents_with_storage_path') .select(); if (error) { toast({ variant: 'destructive', description: '获取文档失败', }); throw error; } return data; }); -
在每个文档的
onClick处理程序中,下载相应的文件。const { data, error } = await supabase.storage .from('files') .createSignedUrl(document.storage_object_path, 60); if (error) { toast({ variant: 'destructive', description: '下载文件失败,请重试。', }); return; } window.location.href = data.signedUrl;
Step 3 - 嵌入
跳到步骤:
使用这些命令跳到step-3检查点。
git stash push -u -m "我在step-2的工作"
git checkout step-3
现在让我们添加逻辑,以便每当新行添加到document_sections表中时自动生成嵌入。
创建SQL迁移
-
创建迁移文件
npx supabase migration new embed -
创建
embed()触发函数。我们将使用此通用触发函数,通过一个新的embed边缘函数异步生成任意表的嵌入(即将到来)。create function private.embed() returns trigger language plpgsql as $$ declare content_column text = TG_ARGV[0]; embedding_column text = TG_ARGV[1]; batch_size int = case when array_length(TG_ARGV, 1) >= 3 then TG_ARGV[2]::int else 5 end; timeout_milliseconds int = case when array_length(TG_ARGV, 1) >= 4 then TG_ARGV[3]::int else 5 * 60 * 1000 end; batch_count int = ceiling((select count(*) from inserted) / batch_size::float); begin -- 遍历每个批次并调用一个边缘函数来处理嵌入生成 for i in 0 .. (batch_count-1) loop perform net.http_post( url := supabase_url() || '/functions/v1/embed', headers := jsonb_build_object( 'Content-Type', 'application/json', 'Authorization', current_setting('request.headers')::json->>'authorization' ), body := jsonb_build_object( 'ids', (select json_agg(ds.id) from (select id from inserted limit batch_size offset i*batch_size) ds), 'table', TG_TABLE_NAME, 'contentColumn', content_column, 'embeddingColumn', embedding_column ), timeout_milliseconds := timeout_milliseconds ); end loop; return null; end; $$; -
将嵌入触发器添加到
document_sections表create trigger embed_document_sections after insert on document_sections referencing new table as inserted for each statement execute procedure private.embed(content, embedding);请注意,我们向
embed()传递了2个触发器参数:- 第一个参数指定包含要嵌入的文本内容的列。
- 第二个参数指定保存嵌入的目标列。
还有2个可选的触发器参数可用:
create trigger embed_document_sections after insert on document_sections referencing new table as inserted for each statement execute procedure private.embed(content, embedding, 5, 300000);- 第三个参数指定批量大小(每次调用边缘函数包含的记录数)。默认值为5。
- 第四个参数指定每次调用边缘函数的HTTP连接超时时间。默认值为300000毫秒(5分钟)。
可以根据需要调整这些参数。较大的批量大小将需要更长的每次请求超时时间,因为每次调用将需要生成更多的嵌入。较小的批量大小可以使用较短的超时时间。
注意:触发边缘函数的生命周期
如果触发的边缘函数失败,你将会有缺少
创建一个 Supabase 客户端并配置为继承用户的权限。
const authorization = req.headers.get('Authorization');
if (!authorization) {
return new Response(
JSON.stringify({ error: `No authorization header passed` }),
{
status: 500,
headers: { 'Content-Type': 'application/json' },
}
);
}
const supabase = createClient(supabaseUrl, supabaseAnonKey, {
global: {
headers: {
authorization,
},
},
auth: {
persistSession: false,
},
});
从指定的表/列中获取文本内容。
const { ids, table, contentColumn, embeddingColumn } = await req.json();
const { data: rows, error: selectError } = await supabase
.from(table)
.select(`id, ${contentColumn}` as '*')
.in('id', ids)
.is(embeddingColumn, null);
if (selectError) {
return new Response(JSON.stringify({ error: selectError }), {
status: 500,
headers: { 'Content-Type': 'application/json' },
});
}
为每段文本生成嵌入并更新相应行。
for (const row of rows) {
const { id, [contentColumn]: content } = row;
if (!content) {
console.error(`No content available in column '${contentColumn}'`);
continue;
}
const output = (await model.run(content, {
mean_pool: true,
normalize: true,
})) as number[];
const embedding = JSON.stringify(output);
const { error } = await supabase
.from(table)
.update({
[embeddingColumn]: embedding,
})
.eq('id', id);
if (error) {
console.error(
`Failed to save embedding on '${table}' table with id ${id}`
);
}
console.log(
`Generated embedding ${JSON.stringify({
table,
id,
contentColumn,
embeddingColumn,
})}`
);
}
返回成功响应。
return new Response(null, {
status: 204,
headers: { 'Content-Type': 'application/json' },
});
如果你在云端直接开发,部署你的边缘函数:
npx supabase functions deploy
第 4 步 - 聊天
跳到步骤:
使用这些命令跳到 step-4 检查点。
git stash push -u -m "my work on step-3"
git checkout step-4
最后,让我们实现聊天功能。在本次研讨会中,我们将在客户端使用一个名为 usePipeline() 的新自定义钩子生成我们的查询嵌入。
更新前端
-
安装依赖
npm i @xenova/transformers ai我们将使用 Transformers.js 直接在浏览器中进行推理。
-
配置
next.config.js以支持 Transformers.jswebpack: (config) => { config.resolve.alias = { ...config.resolve.alias, sharp$: false, 'onnxruntime-node$': false, }; return config; }, -
引入依赖
import { usePipeline } from '@/lib/hooks/use-pipeline'; import { createClientComponentClient } from '@supabase/auth-helpers-nextjs'; import { useChat } from 'ai/react';注意:为了方便,
usePipeline()已预构建到本仓库中。它使用 Web Workers 通过 Transformers.js 在另一个线程中异步生成嵌入。 -
在
chat/page.tsx中创建一个 Supabase 客户端。const supabase = createClientComponentClient(); -
创建嵌入管道。
const generateEmbedding = usePipeline( 'feature-extraction', 'Supabase/gte-small' );注:在这里设置的嵌入模型必须与在边缘函数中使用的模型匹配,否则你将来的匹配逻辑将毫无意义。
Transformers.js 需要模型以 ONNX 格式存在。特别是在管道中指定的 Hugging Face 模型必须在
./onnx文件夹下有一个.onnx文件,否则你会看到错误Could not locate file [...] xxx.onnx。查看这个解释以获取更多细节。要将现有模型(例如 PyTorch、Tensorflow 等)转换为 ONNX,请参阅自定义使用文档。 -
使用
useChat()管理聊天消息和状态。const { messages, input, handleInputChange, handleSubmit, isLoading } = useChat({ api: `${process.env.NEXT_PUBLIC_SUPABASE_URL}/functions/v1/chat`, });注:
useChat()是由 Vercel 的ai包提供的便利钩子,用于处理聊天消息状态和流。我们将其指向一个名为chat的边缘函数(即将实现)。 -
在管道加载完成时将就绪状态设置为
true。const isReady = !!generateEmbedding; -
将
input和handleInputChange连接到我们的<Input>属性。<Input type="text" autoFocus placeholder="Send a message" value={input} onChange={handleInputChange} /> -
在表单提交时生成嵌入并提交消息。
if (!generateEmbedding) { throw new Error('Unable to generate embeddings'); } const output = await generateEmbedding(input, { pooling: 'mean', normalize: true, }); const embedding = JSON.stringify(Array.from(output.data)); const { data: { session }, } = await supabase.auth.getSession(); if (!session) { return; } handleSubmit(e, { options: { headers: { authorization: `Bearer ${session.access_token}`, }, body: { embedding, }, }, }); -
在组件准备好之前禁用发送按钮。
<Button type="submit" disabled={!isReady}> Send </Button>
SQL 迁移
-
为新的匹配功能创建迁移文件
npx supabase migration new match -
创建一个
match_document_sectionsPostgres 函数。create or replace function match_document_sections( embedding vector(384), match_threshold float ) returns setof document_sections language plpgsql as $$ #variable_conflict use_variable begin return query select * from document_sections where document_sections.embedding <#> embedding < -match_threshold order by document_sections.embedding <#> embedding; end; $$;此函数使用 pgvector 的负内积运算符
<#>执行相似性搜索。内积比其他距离函数(如余弦距离<=>)需要更少的计算,因此提供了更好的查询性能。注:我们的嵌入是规范化的,因此内积和余弦相似度在输出方面是等价的。不过,注意 pgvector 的
<=>运算符是余弦距离,而不是余弦相似度,所以inner product == 1 - cosine distance。我们还通过
match_threshold进行过滤,以仅返回最相关的结果(1 = 最相似,-1 = 最不相似)。注:
match_threshold是取反的,因为<#>是负内积。有关为什么<#>是负值的更多详情,请参阅 pgvector 文档。 -
将迁移应用到我们的本地数据库。
npx supabase migration up如果你在云端直接开发,可以将迁移推送到云端:
npx supabase db push
创建 chat 边缘函数
注意: 在本教程中,我们使用 OpenAI 提供的模型来实现聊天逻辑。 但是,自制作本教程以来,出现了许多新的 LLM 提供者,例如:
无论你选择哪个提供者,只要他们提供 OpenAI 兼容的 API(上面列出的所有提供者都提供),你都可以重用下面使用 OpenAI 库的代码。我们将在每一步使用 Ollama 讨论如何执行此操作,但相同的逻辑也适用于其他提供者。
-
首先从 OpenAI 生成一个 API 密钥并将其保存在
supabase/functions/.env中。cat > supabase/functions/.env <<- EOF OPENAI_API_KEY=<your-api-key> EOF -
创建边缘函数文件。
npx supabase functions new chat -
加载 OpenAI 和 Supabase 密钥。
import { createClient } from '@supabase/supabase-js'; import { OpenAIStream, StreamingTextResponse } from 'ai'; import { codeBlock } from 'common-tags'; import OpenAI from 'openai'; const openai = new OpenAI({ apiKey: Deno.env.get('OPENAI_API_KEY'), }); // 这些会被自动注入 const supabaseUrl = Deno.env.get('SUPABASE_URL'); const supabaseAnonKey = Deno.env.get('SUPABASE_ANON_KEY');注意:Ollama 支持
对于 Ollama(和其他 OpenAI 兼容的提供者),在实例化
openai时调整baseURL和apiKey:const openai = new OpenAI({ baseURL: 'http://host.docker.internal:11434/v1/', apiKey: 'ollama', });
我们假设您在本地运行 ollama serve,使用默认端口 :11434。由于本地的边缘函数运行在 Docker 容器内,为了访问运行在主机上的 Ollama,我们需要指定 host.docker.internal 而不是 localhost。
-
由于我们的前端服务与边缘函数位于不同的域名来源,因此我们必须处理跨域资源共享(CORS)。
export const corsHeaders = { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Headers': 'authorization, x-client-info, apikey, content-type', }; Deno.serve(async (req) => { // 处理 CORS if (req.method === 'OPTIONS') { return new Response('ok', { headers: corsHeaders }); } });通过检查
OPTIONSHTTP 请求并返回 CORS 头信息(*= 允许任何域名),简单处理 CORS。在生产环境中,考虑将来源限制为提供前端服务的特定域名。 -
检查环境变量并创建 Supabase 客户端。
if (!supabaseUrl || !supabaseAnonKey) { return new Response( JSON.stringify({ error: '缺少环境变量。', }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } const authorization = req.headers.get('Authorization'); if (!authorization) { return new Response( JSON.stringify({ error: `没有传递授权头信息` }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } const supabase = createClient(supabaseUrl, supabaseAnonKey, { global: { headers: { authorization, }, }, auth: { persistSession: false, }, }); -
RAG 的第一步是使用我们的
match_document_sections()函数执行相似性搜索。Postgres 函数使用.rpc()方法执行。const { chatId, message, messages, embedding } = await req.json(); const { data: documents, error: matchError } = await supabase .rpc('match_document_sections', { embedding, match_threshold: 0.8, }) .select('content') .limit(5); if (matchError) { console.error(matchError); return new Response( JSON.stringify({ error: '读取文档时出错,请重试。', }), { status: 500, headers: { 'Content-Type': 'application/json' }, } ); } -
RAG 的第二步是构建我们的提示语,将从之前的相似性搜索中检索到的相关文档注入其中。
const injectedDocs = documents && documents.length > 0 ? documents.map(({ content }) => content).join('\n\n') : '未找到文档'; const completionMessages: OpenAI.Chat.Completions.ChatCompletionMessageParam[] = [ { role: 'user', content: codeBlock` 你是一名回答关于文档问题的 AI 助手。 你是一个聊天机器人,所以保持回复简洁。 你只能使用下面的文档来回答问题。 如果问题与这些文档无关,请说: "抱歉,我找不到相关信息。" 如果以下文档中没有相关信息,请说: "抱歉,我找不到相关信息。" 请不要跑题。 文档: ${injectedDocs} `, }, ...messages, ];注意:
codeBlock模板标签是一个方便的函数,它会去除我们多行字符串中的缩进。这允许我们在保持预期缩进的同时,优雅地格式化代码。 -
最后,创建一个补全流并返回它。
const completionStream = await openai.chat.completions.create({ model: 'gpt-3.5-turbo-0125', messages: completionMessages, max_tokens: 1024, temperature: 0, stream: true, }); const stream = OpenAIStream(completionStream); return new StreamingTextResponse(stream, { headers: corsHeaders });OpenAIStream和StreamingTextResponse是 Vercel 的ai包中的便捷助手,它们将 OpenAI 的响应流转换为useChat()能在前端理解的格式。注意:我们在这里(或任何其他发送响应的地方)也必须返回 CORS 头信息。
注意:Ollama 支持
将模型更改为您在本地运行的模型,例如:- model: 'gpt-3.5-turbo-0125', + model: 'dolphin-mistral', -
如果您直接在云端开发,请在云端设置您的
OPENAI_API_KEY秘密:npx supabase secrets set OPENAI_API_KEY=<openai-key>然后部署您的边缘函数:
npx supabase functions deploy
试试吧!
让我们试试吧!以下是您可以尝试询问的一些问题:
- 他们住在什么样的建筑物里?
- 最常见的食物是什么?
- 人们用什么来娱乐?
第5步 - 数据库类型(奖励)
跳到某一步:
使用这些命令跳到 step-5 检查点。
git stash push -u -m "我的第4步工作"
git checkout step-5
您可能已经注意到,所有从 supabase 客户端返回的数据库数据都具有 any 类型(如 documents 或 document_sections)。这不太好,因为我们缺少相关的类型信息并且失去了类型安全性 (这使得我们的应用程序更容易出错)。
Supabase CLI 带有一个内置命令,可以根据数据库的架构生成 TypeScript 类型。
-
根据本地数据库架构生成 TypeScript 类型。
supabase gen types typescript --local > supabase/functions/_lib/database.ts -
在项目中的所有 Supabase 客户端中添加
<Database>泛型。-
在 React 中
import { Database } from '@/supabase/functions/_lib/database'; const supabase = createClientComponentClient<Database>();import { Database } from '@/supabase/functions/_lib/database'; const supabase = createServerComponentClient<Database>(); -
在边缘函数中
import { Database } from '../_lib/database.ts'; const supabase = createClient<Database>(...);
-
-
修复类型错误 😃
-
看来我们在
./app/files/page.tsx中发现了一个类型错误!让我们在文档的点击处理程序的顶部添加此检查 (类型缩小)。if (!document.storage_object_path) { toast({ variant: 'destructive', description: '文件下载失败,请重试。', }); return; }
-
完成了!
🎉 恭喜!您已在2小时内构建了自己的全栈 pgvector 应用程序。
如果您想直接跳转到已完成的应用程序,只需签出 main 分支:
git checkout main
跳到上一步:
🚀 部署到生产环境
如果您一直在本地开发应用程序,请按照以下说明将您的应用程序部署到生产 Supabase 项目。
-
在 https://database.new 上创建一个 Supabase 项目,或者通过 CLI:
npx supabase projects create -i "ChatGPT Your Files" -
将 CLI 与您的 Supabase 项目链接。
npx supabase link --project-ref=<project-ref>您可以在[项目设置](https://supabase











