
计时器(大规模时间序列模型)
本仓库提供了Timer: 生成式预训练Transformer是大规模时间序列模型的官方代码、数据集和检查点。[海报],[幻灯片]。
更新
:triangular_flag_on_post: 新闻 (2024.6) 预训练数据集(UTSD)现已在HuggingFace上可用。数据加载器也包含在内。
:triangular_flag_on_post: 新闻 (2024.5) 被ICML 2024接收,31页的camera-ready版本。
:triangular_flag_on_post: 新闻 (2024.4) 预训练规模已扩展,实现了零样本预测。
:triangular_flag_on_post: 新闻 (2024.2) 发布模型检查点和适应代码。
简介
Time Series Transformer (Timer)是一个用于通用时间序列分析的生成式预训练Transformer。您可以访问我们的主页获取更详细的介绍。

数据集
我们整理了[统一时间序列数据集(UTSD)](https://github.com/thuml/Large-Time-Series-Model/blob/main/(https://huggingface.co/datasets/thuml/UTSD),包含**10亿个时间点**和**4个卷**,以促进大规模时间序列模型和预训练的研究。
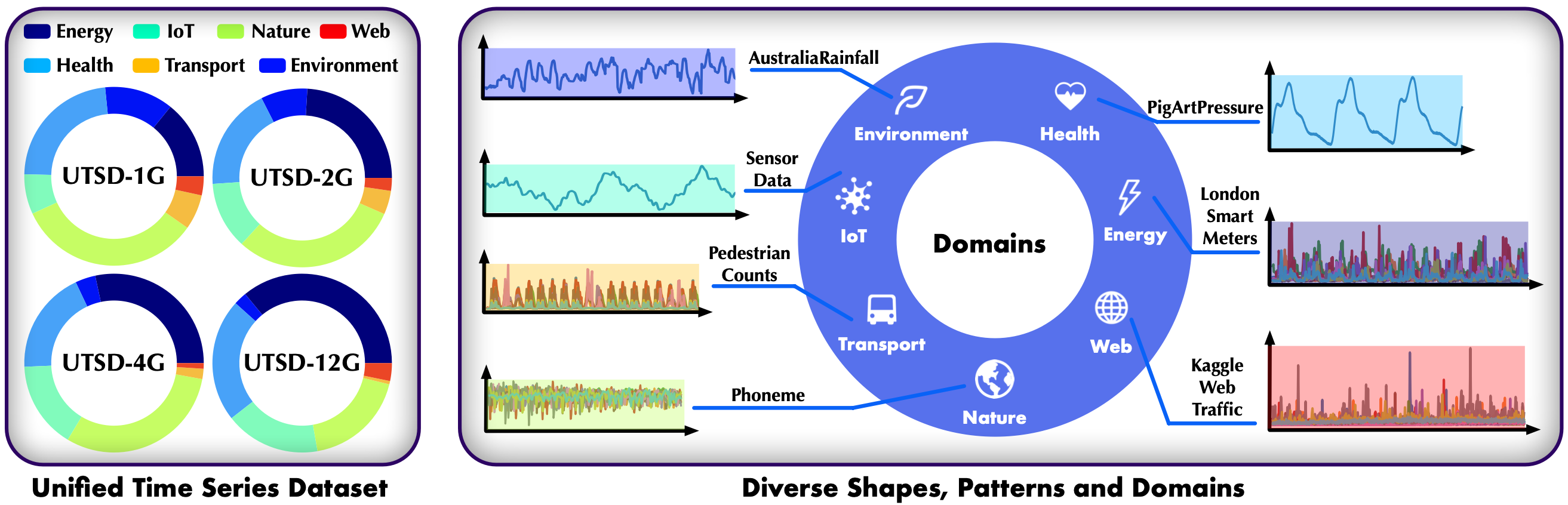
我们的数据集已在HuggingFace上发布,以促进时间序列领域的大模型和预训练研究。
使用方法
您可以基于以下方式访问和加载UTSD,风格类似于TSLib:
# huggingface-cli login
# export HF_ENDPOINT=https://hf-mirror.com
python ./scripts/UTSD/download_dataset.py
# 数据加载器
python ./scripts/UTSD/utsdataset.py
任务
**[异常检测](https://github.com/thuml/Large-Time-Series-Model/blob/main/scripts/anomaly_detection/README.md**:我们在[UCR异常归档](https://arxiv.org/pdf/2009.13807)上提供了预测性异常检测的新基准。
我们在./scripts/文件夹下提供了详细的README文件,说明每个任务。
微调代码
- 安装Pytorch和必要的依赖。
pip install -r requirements.txt
-
将来自Google Drive和清华云的下游数据集放在
./dataset/文件夹下。 -
将来自Google Drive和清华云的检查点放在
./checkpoints/文件夹下。 -
训练和评估模型。我们在
./scripts/文件夹下提供了上述任务。
# 预测
bash ./scripts/forecast/ECL.sh
# 段级插补
bash ./scripts/imputation/ECL.sh
# 异常检测
bash ./scripts/anomaly_detection/UCR.sh
在自定义数据集上训练
要在您的时间序列数据集上进行微调,您可以尝试以下步骤:
- 关键是重新加载自定义数据加载器并加载预训练的检查点(参见
./scripts/文件夹)。 data_provider文件夹中的CIDatasetBenchmark/CIAutoRegressionDatasetBenchmark可以在直接/迭代多步模式下训练和评估模型。
方法
预训练和适应
为了在异构时间序列上进行预训练,我们提出了单序列序列(S3),保留了统一上下文长度的序列变化。此外,我们将预测、插补和异常检测转换为统一的生成任务。
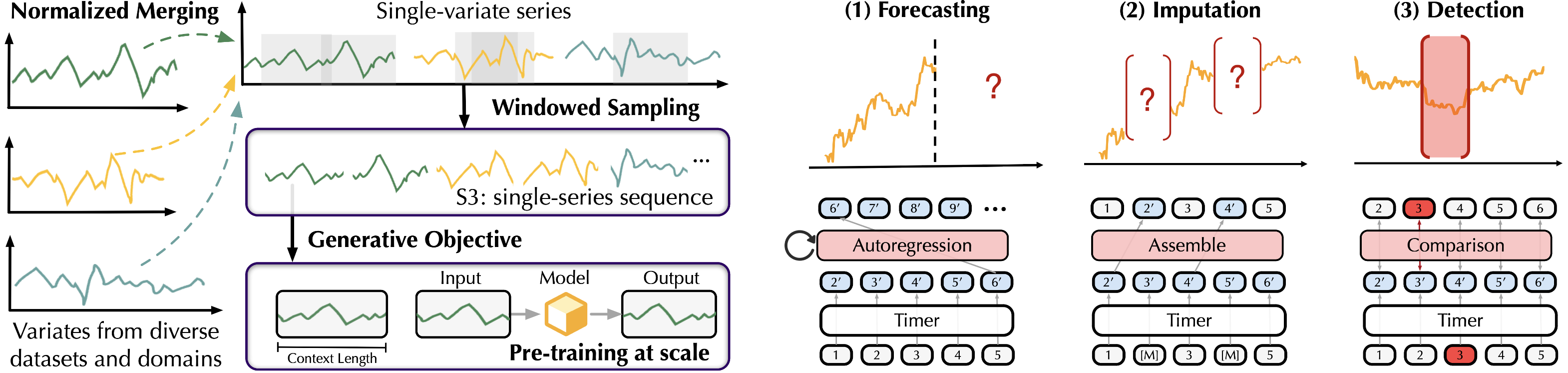
模型架构
鉴于对大规模时间序列模型的骨干网络的探索有限,我们对候选骨干网络进行了广泛评估,并采用了仅解码器的Transformer,通过自回归生成实现LTSMs。

性能
Timer在每个任务中都达到了最先进的性能,我们展示了在少样本场景下的预训练效果。
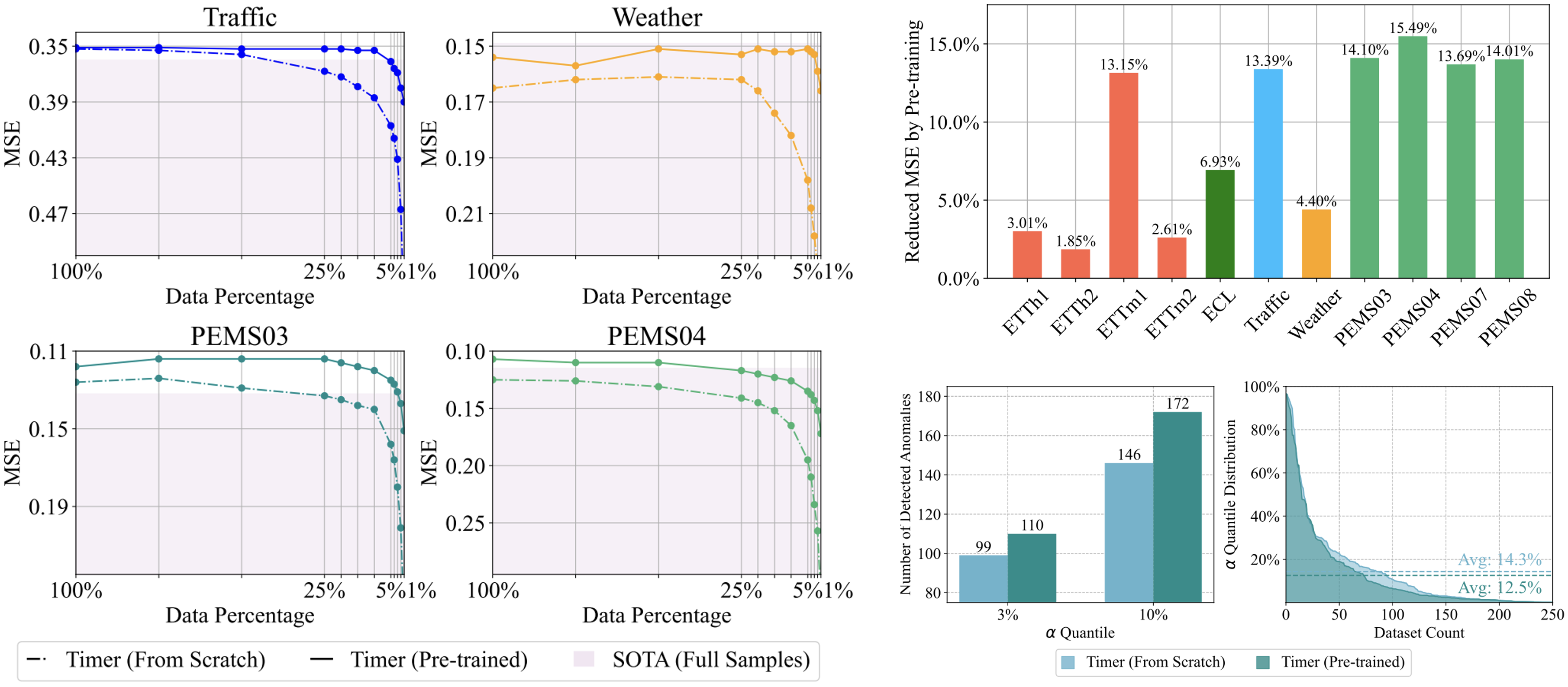
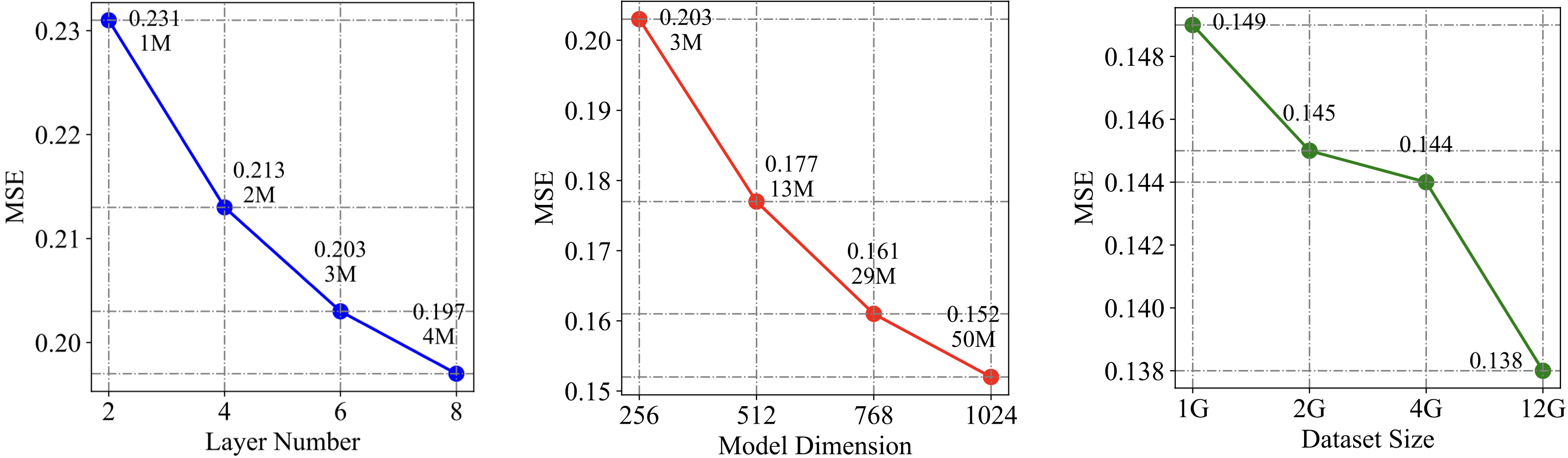
可扩展性
通过增加参数和预训练规模,Timer实现了显著的性能提升:0.231 → 0.138(-40.3%),超越了之前最先进的深度预测器。
灵活的序列长度
仅解码器架构提供了灵活性,可以适应不同回溯和预测长度的时间序列。
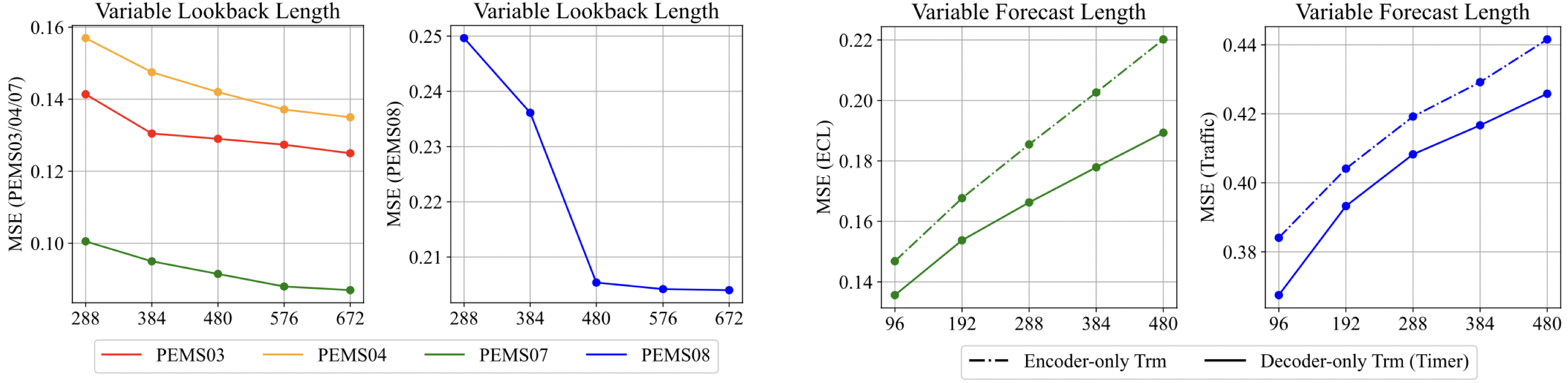
基准测试
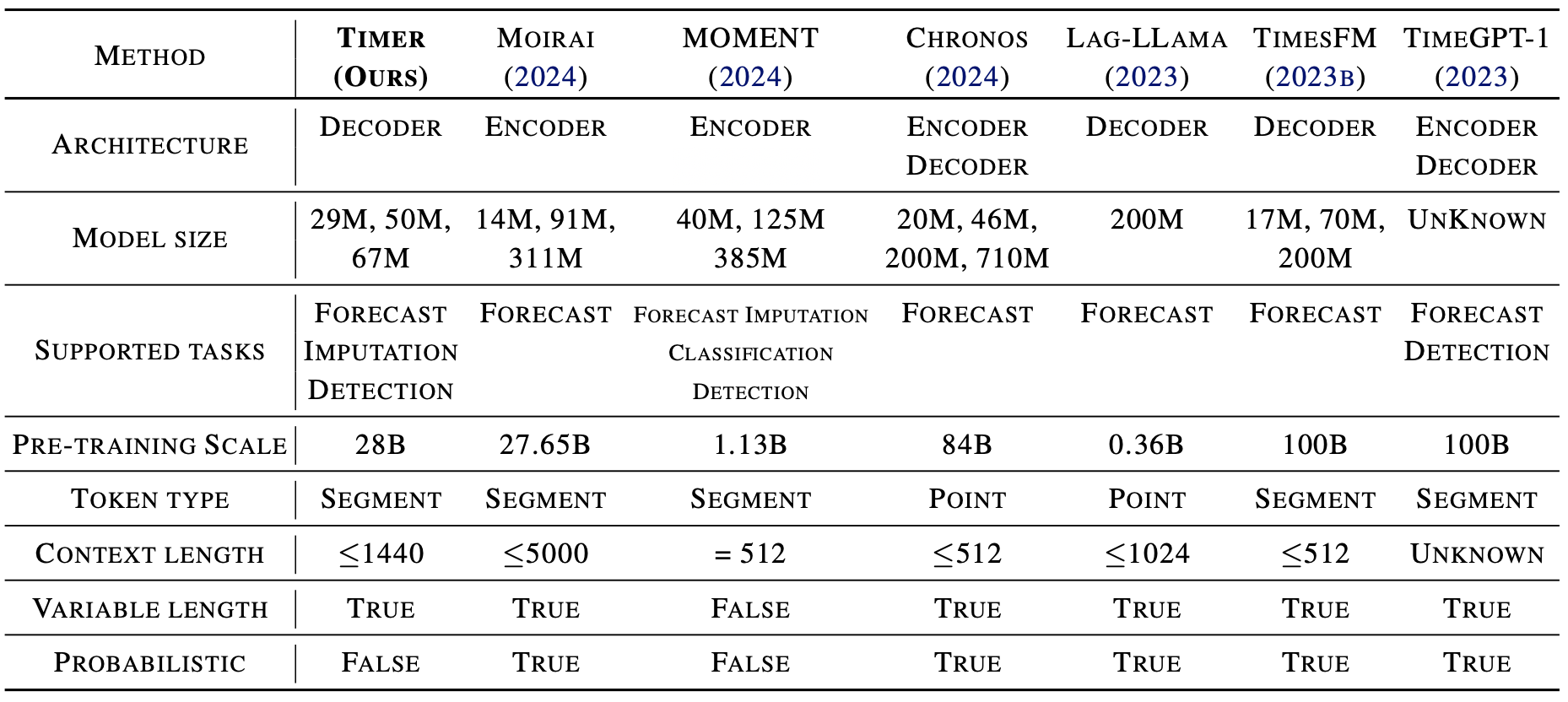
考虑到对研究人员和从业者的重要价值,我们提供了几个并发大型时间序列模型的总结:
- MOMENT 通过掩码建模进行大规模训练。它可以通过将回溯序列与预测长度的掩码连接起来,应用于零样本预测。
- Chronos 是由亚马逊开发的概率点级预测器。Chronos-S1采样一个预测轨迹,Chronos-S20使用20个采样轨迹的平均值。
- 谷歌的TimesFM在1000亿个时间点上进行了训练。我们使用[HuggingFace](https://github.com/thuml/Large-Time-Series-Model/blob/main/ https://huggingface.co/google/timesfm-1.0-200m)的官方检查点。它支持动态输入和输出预测长度。
- Moiria由Salesforce开发,擅长多变量时间序列。它有三个不同的检查点,标记为Moiria-S、Moiria-M和Moiria-L。
- Timer:我们评估了三个版本:Timer-1B在UTSD上预训练;Timer-16B在UTSD和Buildings900K上预训练;Timer-28B在UTSD和LOTSA上预训练。
我们还建立了第一个零样本基准来衡量LTSMs作为通用预测器的性能。
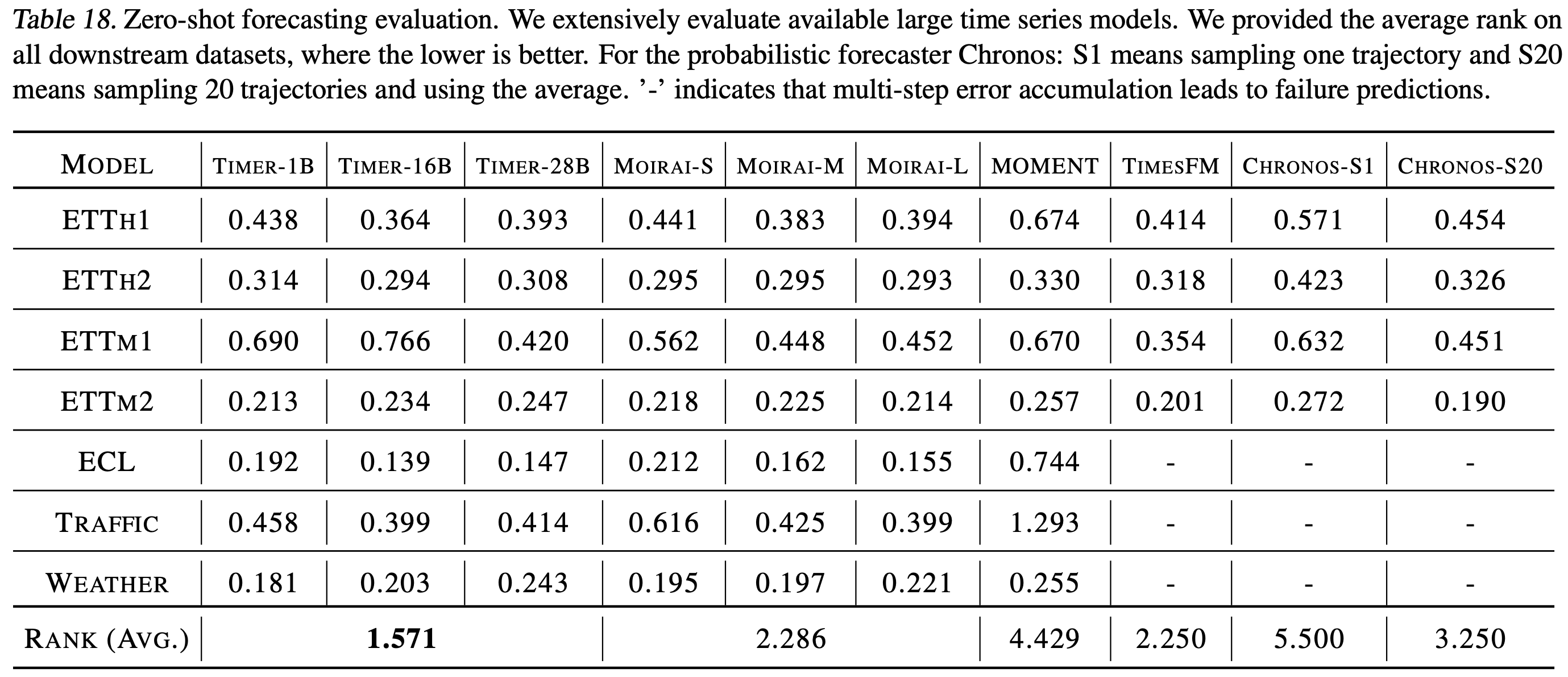
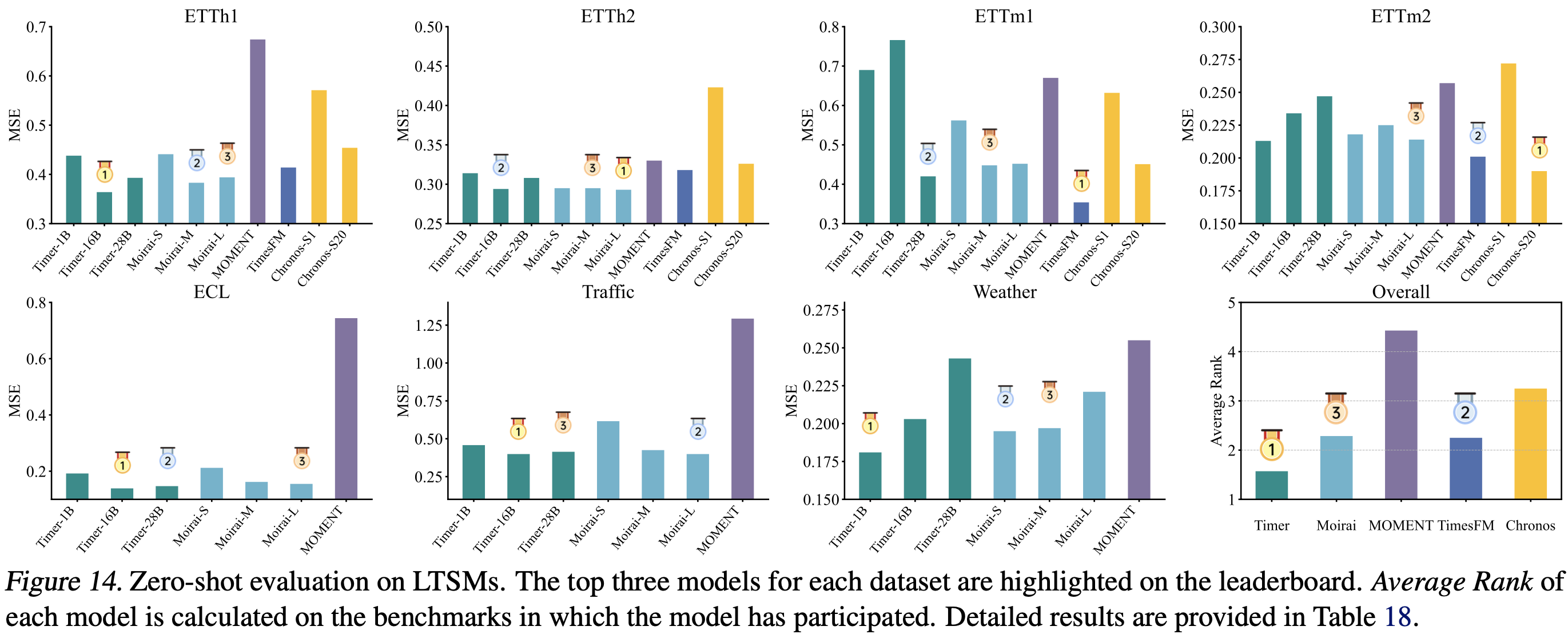
应当注意的是,当前大型时间序列模型的零样本性能仍然落后于基于少样本微调或端到端训练的大型模型(类似于2020年GPT-3面临的挑战)。
引用
如果您觉得这个仓库有帮助,请引用我们的论文。
@inproceedings{liutimer,
title={Timer: Generative Pre-trained Transformers Are Large Time Series Models},
author={Liu, Yong and Zhang, Haoran and Li, Chenyu and Huang, Xiangdong and Wang, Jianmin and Long, Mingsheng},
booktitle={Forty-first International Conference on Machine Learning}
}
致谢
我们非常感谢以下GitHub仓库的宝贵代码和努力。
- Time-Series-Library (https://github.com/thuml/Time-Series-Library)
- LOTSA (https://huggingface.co/datasets/Salesforce/lotsa_data)
- UCR Anomaly Archive (https://arxiv.org/abs/2009.13807)
贡献者
如果您有任何问题或想使用代码,请随时联系:











