
InfLLM:揭示LLMs理解超长序列的内在能力,无需训练的记忆
我们的论文《InfLLM:揭示LLMs理解超长序列的内在能力,无需训练的记忆》的代码[pdf]。
更新
- 2024年3月3日:初始代码发布。请参见init。
- 2024年3月24日:重构代码。提高推理速度并减少GPU内存使用。
- 2024年4月4日:支持使用faiss进行topk检索。
- 2024年4月20日:增加对LLaMA 3的支持。
快速链接
概述
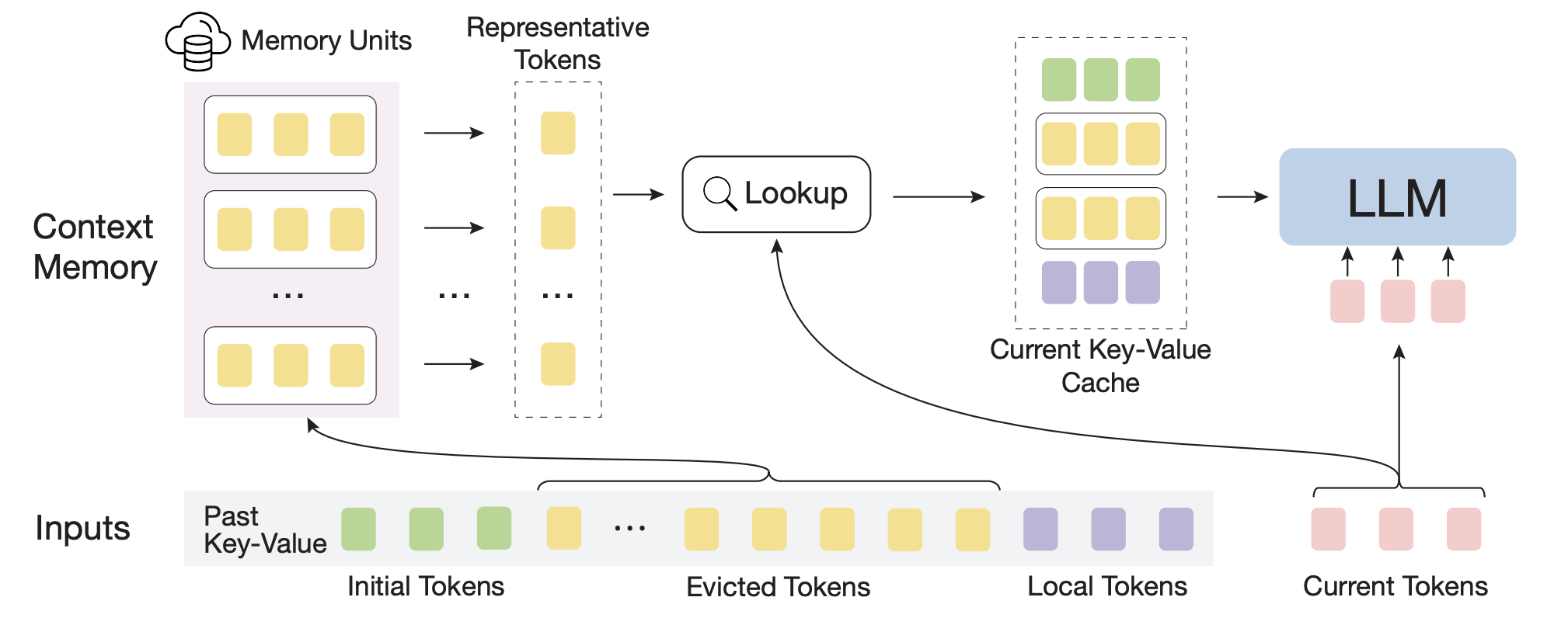
大型语言模型(LLMs)在具有长流式输入的实际应用中已成为基石,例如由LLM驱动的代理。然而,现有的LLMs由于在预训练时使用了有限的最大长度序列,不能推广到更长的序列,因为它们会遇到领域外和干扰问题。为了解决这些问题,目前的努力采用滑动注意窗口并丢弃远距离的token来处理超长序列。不幸的是,这些方法不可避免地无法捕捉序列内的长距离依赖关系,从而深入理解语义。本文介绍了一种基于无需训练记忆的方法InfLLM,以揭示LLMs处理长流式序列的内在能力。具体来说,InfLLM将远距离的上下文存储到额外的记忆单元中,并采用一种高效的机制来查找相关的记忆单元以进行注意力计算。因此,InfLLM使LLMs能够高效地处理长序列,同时保持捕捉长距离依赖关系的能力。在无需任何训练的情况下,InfLLM使预训练在几千个token上的LLMs在处理长序列时表现优于那些在长序列上不断训练的竞争基准模型。即使当序列长度扩展到1,024K时,InfLLM仍能有效捕捉长距离依赖关系。
要求
torch>=1.13.1
transformers>=4.37.2
fschat>=0.2.35
datasets>=2.17.0
omegaconf
flash-attn
rouge==1.0.1
fuzzywuzzy==0.18.0
jieba==0.42.1
使用
配置
我们使用YAML文件来进行配置,您可以在config/目录中看到我们用于基准测试的配置文件。
配置文件的描述如下:
model:
# attention类型
# inf-llm/infinite-lm/stream-lm/origin(full attention)
type: inf-llm
# huggingface或model-center模型路径
path: mistralai/Mistral-7B-Instruct-v0.2
# 是否使用flash-attention
# 对于inf-llm/infinite-lm/stream-llm,我们通过OpenAI的Triton实现了多阶段的flash-attention
fattn: false
# RoPE基线和距离缩放
base: 1000000
distance_scale: 1.0
# inf-llm/infinite-lm/stream-lm设置
# 初始tokens作为注意力汇
n_init: 128
# 本地滑动窗口大小
n_local: 4096
# inf-llm设置
# 在注意力计算中检索的记忆单元数量。
topk: 16
# 每个记忆单元中作为代表元素的top-scoring tokens数量。
repr_topk: 4
# 存储在GPU内存中的最大记忆单元数量。
max_cached_block: 32
# 每次执行查询的tokens数量。
exc_block_size: 512
# 缓存记忆单元的替换策略。
# 支持的策略包括LRU(最近最少使用),FIFO(先进先出),
# 和LRU-S(本文中的LRU)。
cache_strategy: lru
# LRU-S的得分衰减
# score_decay: 0.1
# 使用重叠的局部和全局计算。
# 可以加速但可能不兼容
async_global_stream: false
# 使用faiss进行记忆单元的topk检索。
# 它会增加推理时间并确保GPU内存使用量恒定。
faiss: false
# 使用perhead topk。
# 启用它将非常费时,仅限于研究用途。
# perhead: false
# 模型最大输入长度。
# 如果输入长度超过,将进行截断。
max_len: 2147483647
# 截断类型。现在仅支持suffix(后缀)。
truncation: suffix
# 解码中的分块输入。
# 节省GPU内存。(FFN块)
chunk_size: 8192
# 对话类型。
# mistral-inst/vicuna/qwen/minicpm/llama-3-inst
conv_type: mistral-inst
评估
数据准备 我们采用InfiniteBench和LongBench来进行模型评估。您可以运行以下命令下载数据集。
bash scripts/download.sh
响应生成 您可以运行以下命令来评估InfLLM。需要注意的是,提供的代码仅用于单个GPU的评估,您可以使用多个GPU加速实验。
bash scripts/[infinitebench,longbench].sh
运行InfLLM聊天机器人
我们集成了fastchat的CLI聊天。
python -m inf_llm.chat \
--model-path mistralai/Mistral-7B-Instruct-v0.2 \
--inf-llm-config-path config/mistral-inf-llm.yaml
引用
如果您认为InfLLM有用,请引用以下论文:
@article{xiao2024infllm,
author = {Chaojun Xiao and Pengle Zhang and Xu Han and Guangxuan Xiao and Yankai Lin and Zhengyan Zhang and Zhiyuan Liu and Song Han and Maosong Sun},
title = {InfLLM:揭示LLMs理解超长序列的内在能力,无需训练的记忆},
journal = {arXiv},
year = {2024}
}











