
 访问官网
访问官网产品介绍
豆包大模型是由字节跳动自主研发的一款大型语言模型,适用于多元场景,并能够提供每日千亿规模的数据处理支持。该模型具备多模态能力,能够处理文本、音频、视频等多种数据类型,旨在提升企业业务操作效率。豆包大模型拥有通用和专业两个版本,适合问答、生成、分类等应用场景,并支持代码生成、信息提取和逻辑推理等功能,旨在满足企业和开发者的多种需求。
产品功能
豆包大模型提供了众多功能,涵盖多种场景和业务需求。以下是主要功能的详细描述:
-
豆包·通用模型pro:
- 自研LLM模型专业版,支持256K长文本,全系列可精调,具备强大的理解、生成和逻辑能力。
- 适配多种丰富场景,如问答、总结、创作、分类等。
-
豆包·通用模型lite:
- 自研LLM模型轻量版,提供更低的token成本和更低延迟,适合高灵活性和经济性需求的企业。
-
豆包·视频生成模型:
- 通过精准的语义理解和强大的动态及运镜能力,创作高质量的视频,支持文本和图片生成两种模式。
-
豆包·文生图模型:
- 精美的文字理解能力,准确的图文匹配效果,擅长对中国文化元素的创作。
-
豆包·图生图模型:
- 快速生成精美写真,支持超过50种风格变换,并提供扩图、重绘和涂抹等创意延展功能。
-
豆包·同声传译模型:
- 提供超低延时且高质量的实时翻译,支持跨语言同音色翻译,打破沟通中的语言壁垒。
-
豆包·语音识别模型:
- 更高的准确率及灵敏度,低语音识别延迟,支持多语种正确识别。
-
豆包·语音合成模型:
- 提供自然生动的语音合成能力,能表达多种情绪,演绎多种场景。
-
豆包·声音复刻模型:
- 在5秒内实现声音1:1克隆,高度还原音色相似度和自然度,支持声音的跨语种迁移。
-
豆包·角色扮演模型:
- 个性化角色创作能力,上下文感知和剧情推动能力强,适用于灵活的角色扮演需求。
-
豆包·Function Call模型:
- 提供准确的功能识别和参数抽取能力,适用于复杂工具调用场景。
-
豆包·向量化模型:
- 聚焦向量检索场景,为LLM知识库提供核心理解能力,支持多语言。
应用场景
豆包大模型在以下场景中展现了其强大的适配能力:
-
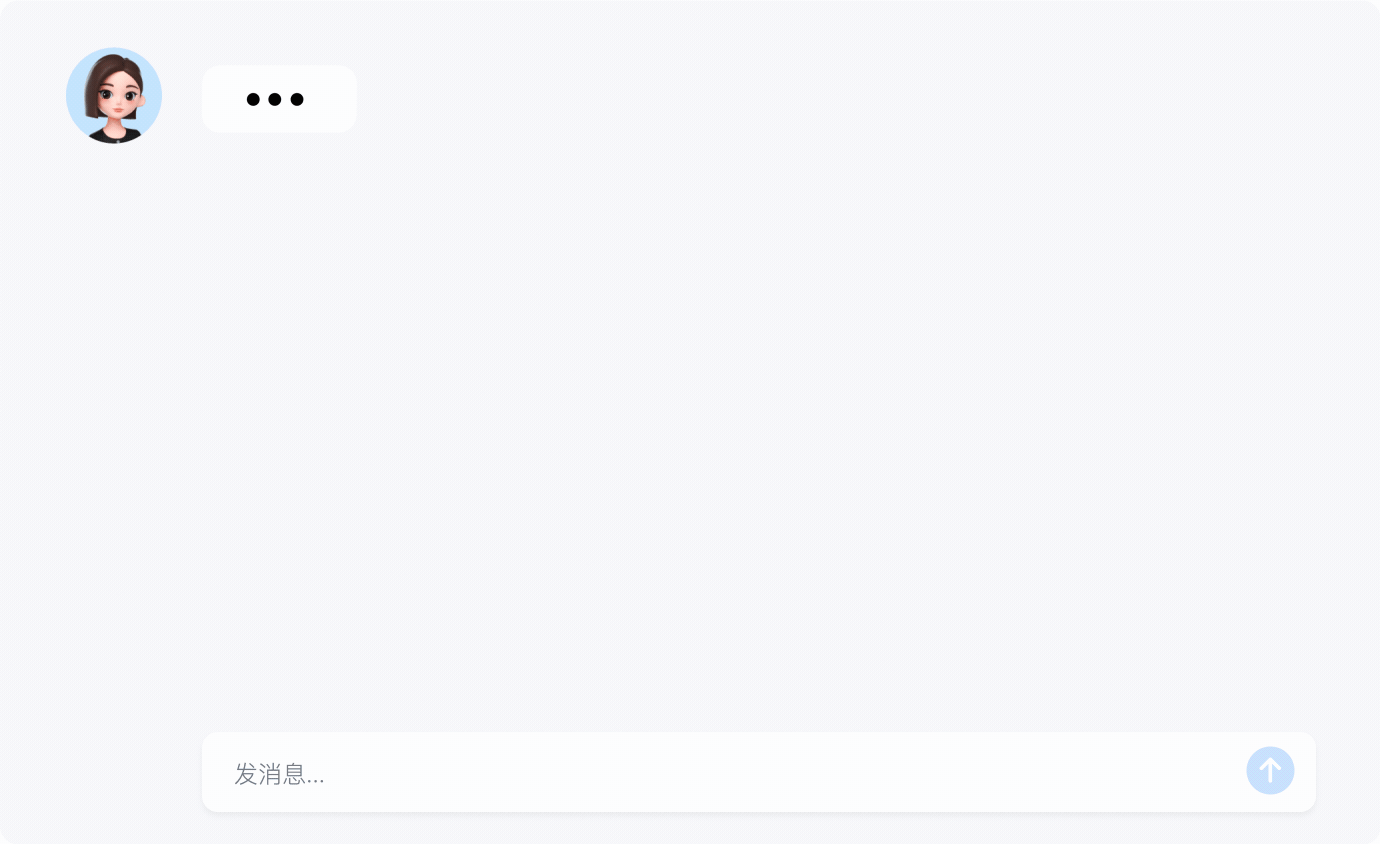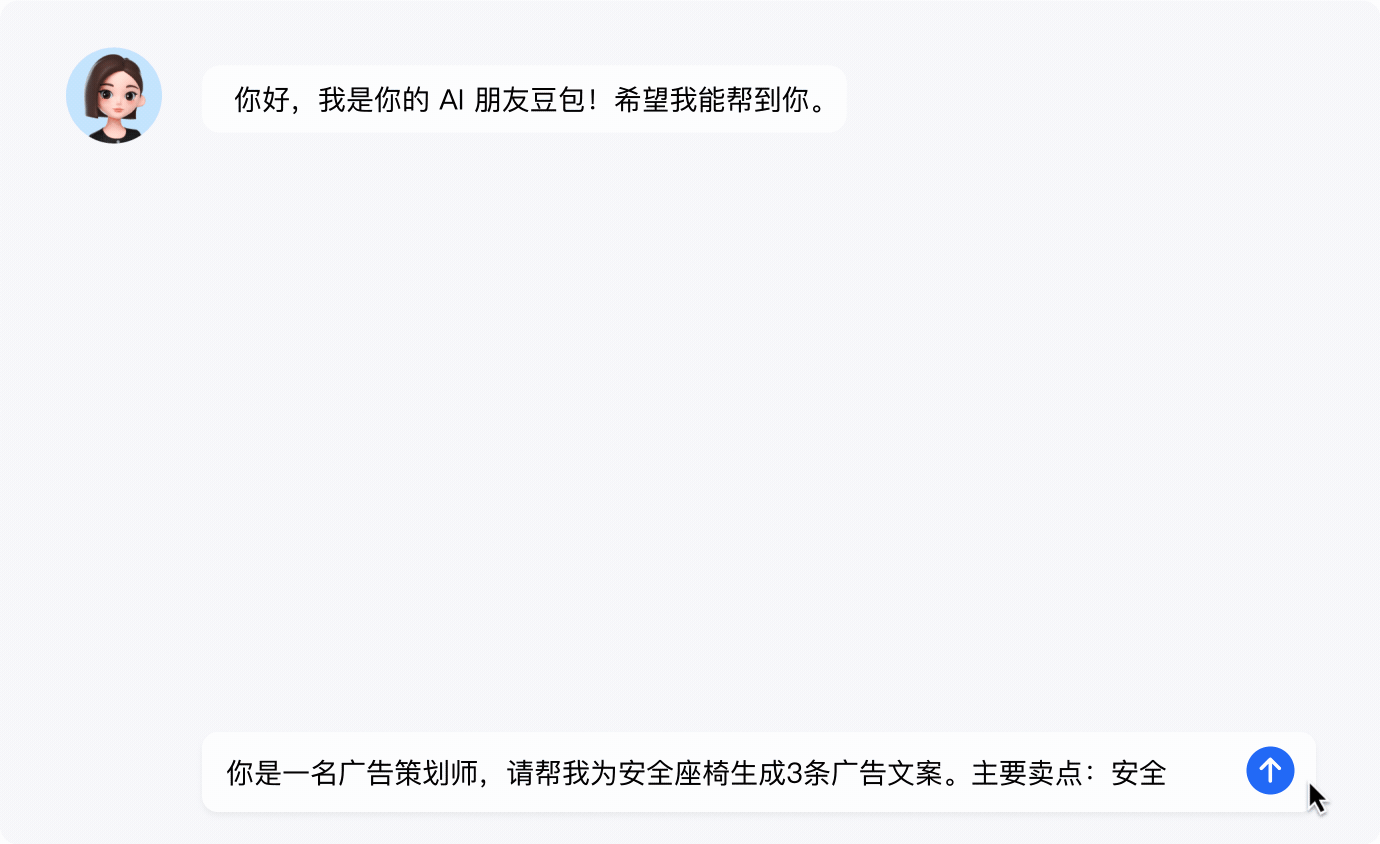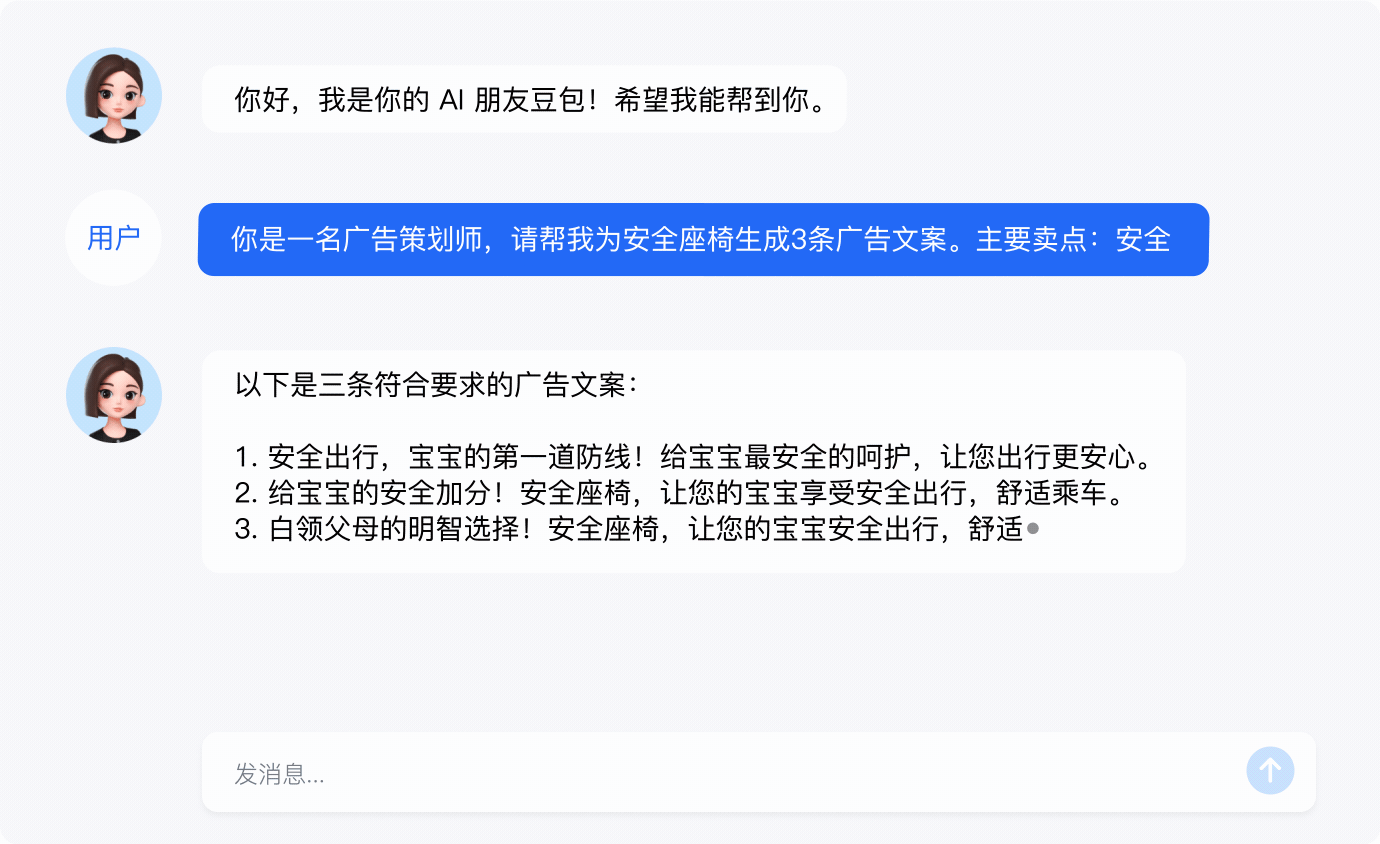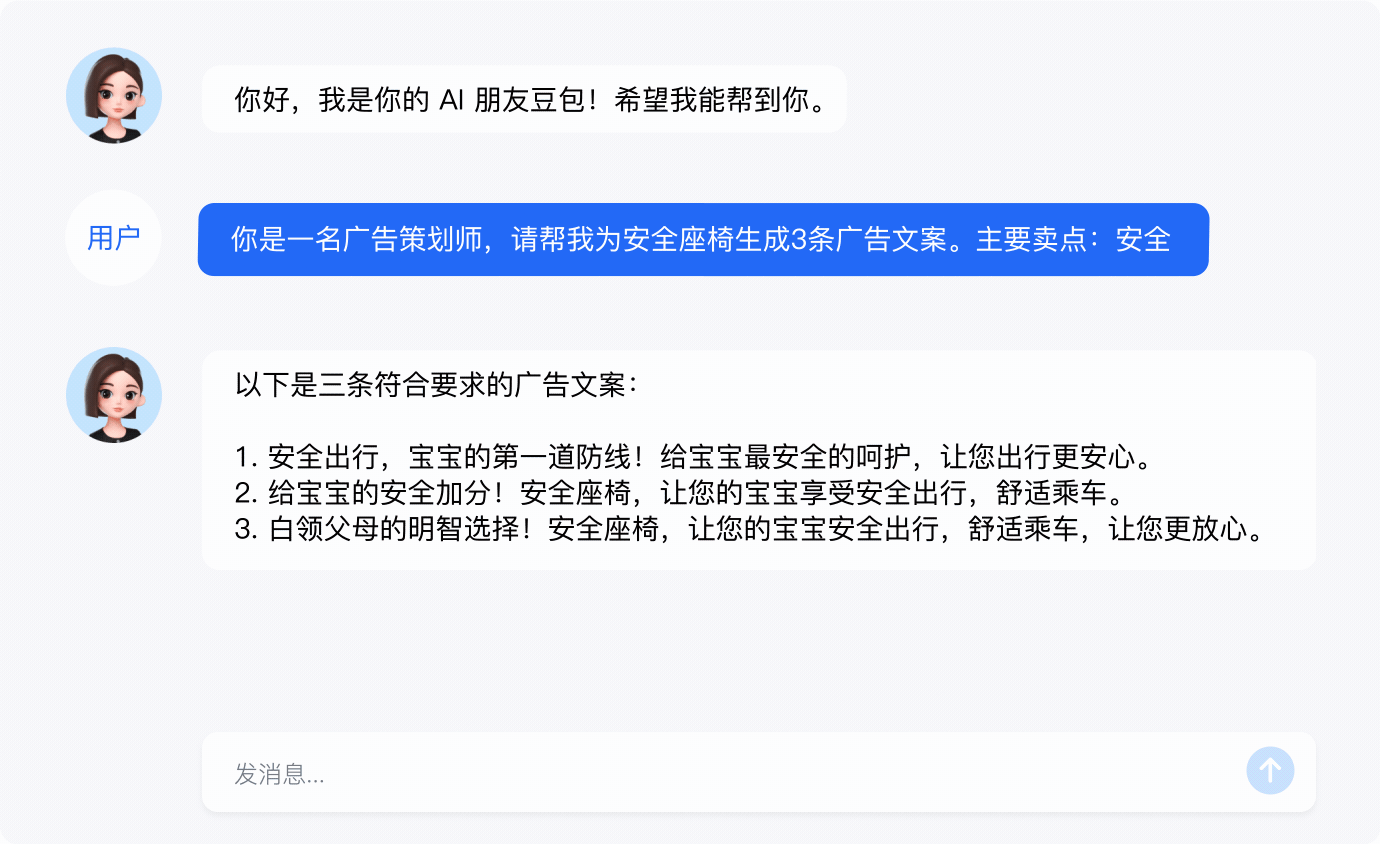
内容创作
- 丰富的文字创作能力,适用于大纲生成、营销文案生成等内容创作场景。
-
知识问答
- 集成海量知识库,高效解决工作、生活中的各种问题。

-
人设对话
- 生动精确的角色扮演能力,适用于社交陪伴、虚拟主播等人设对话场景。

-
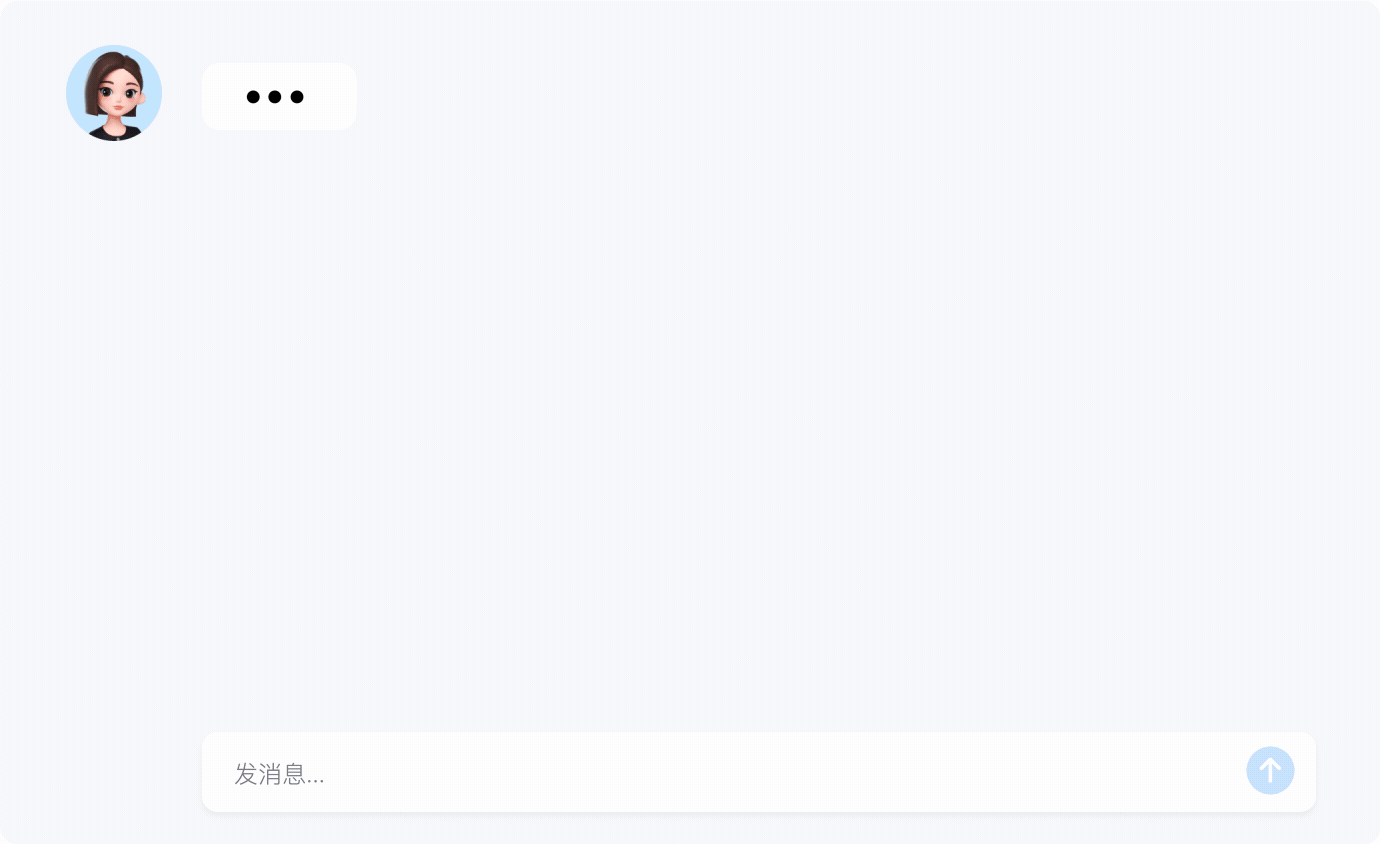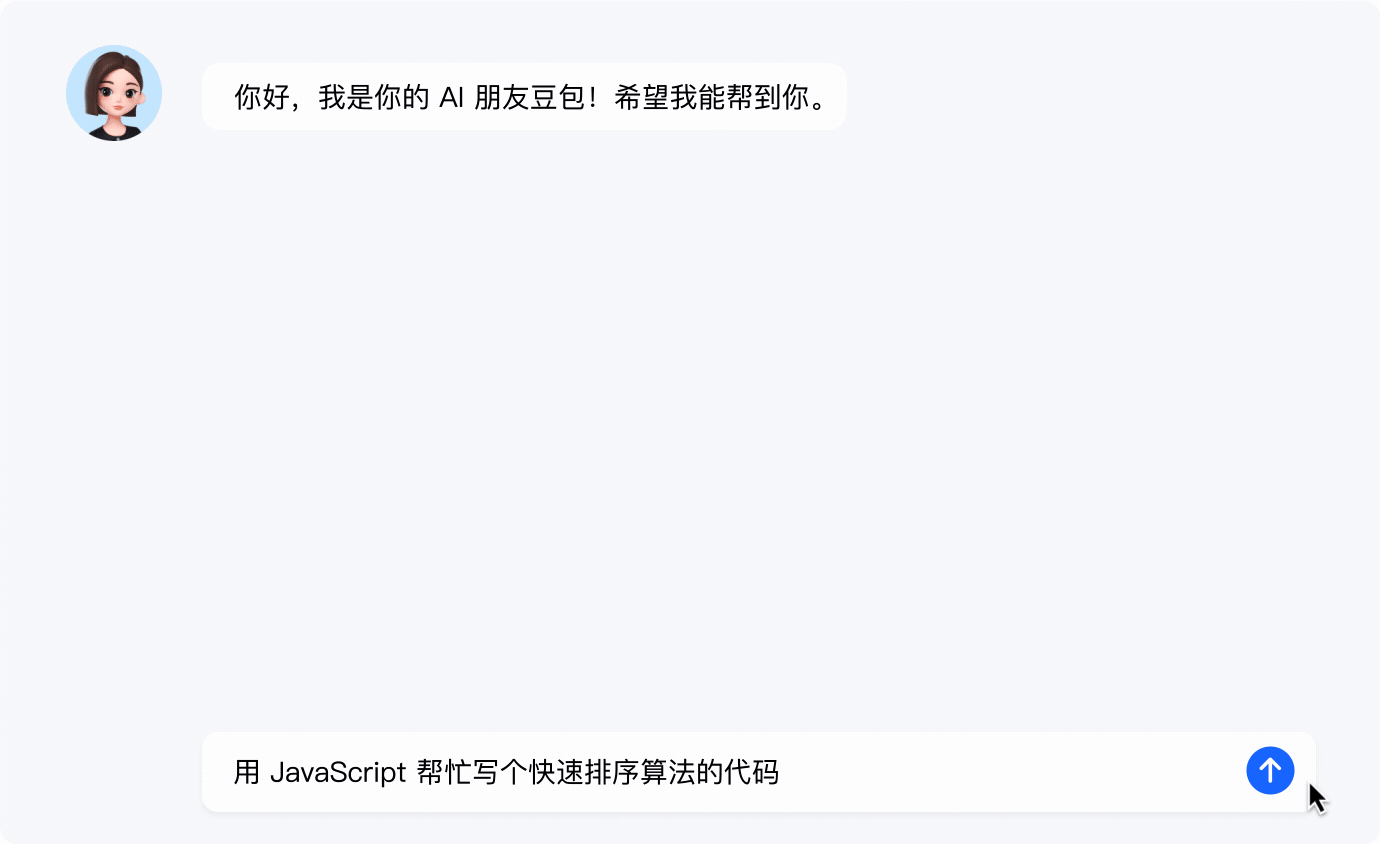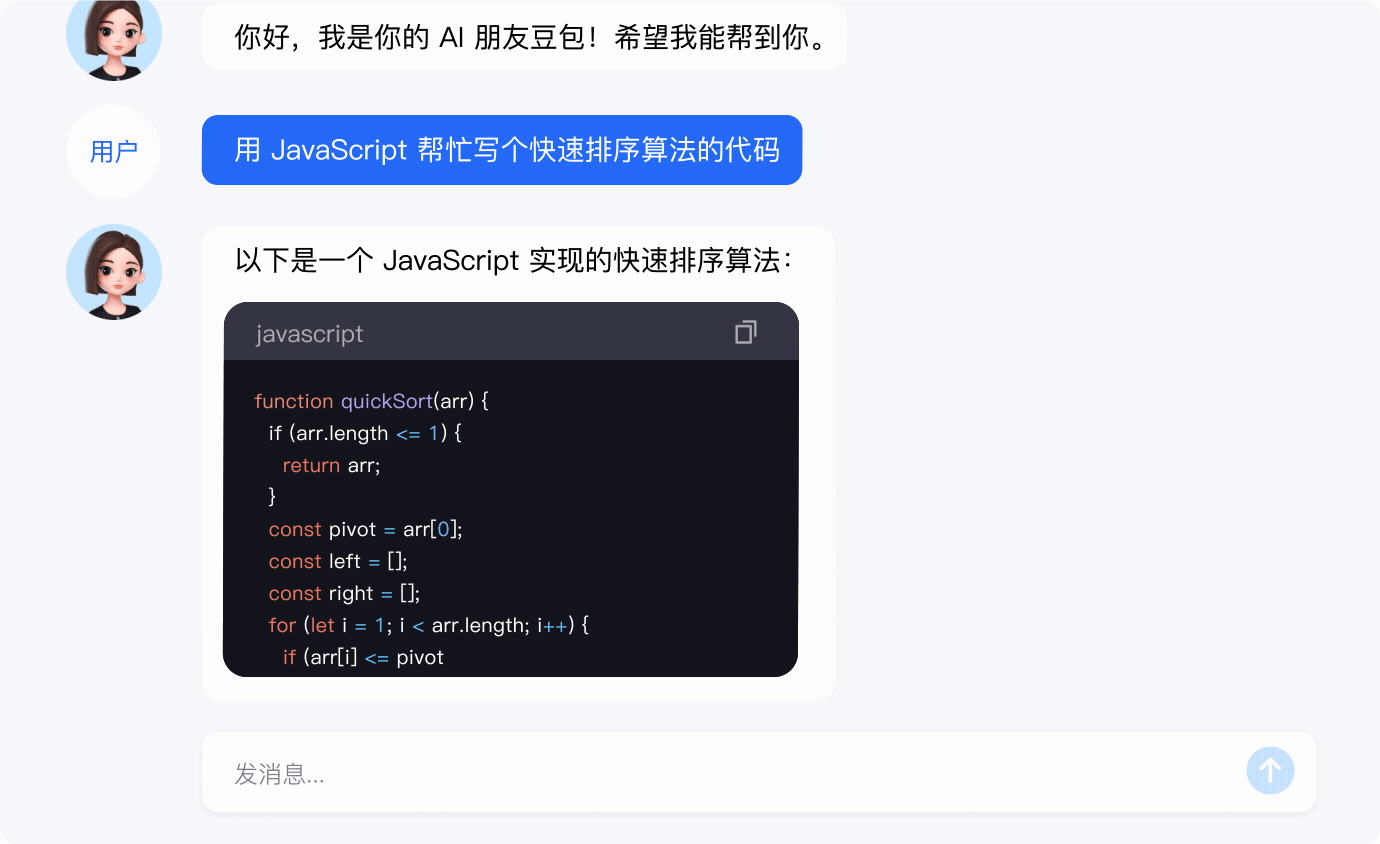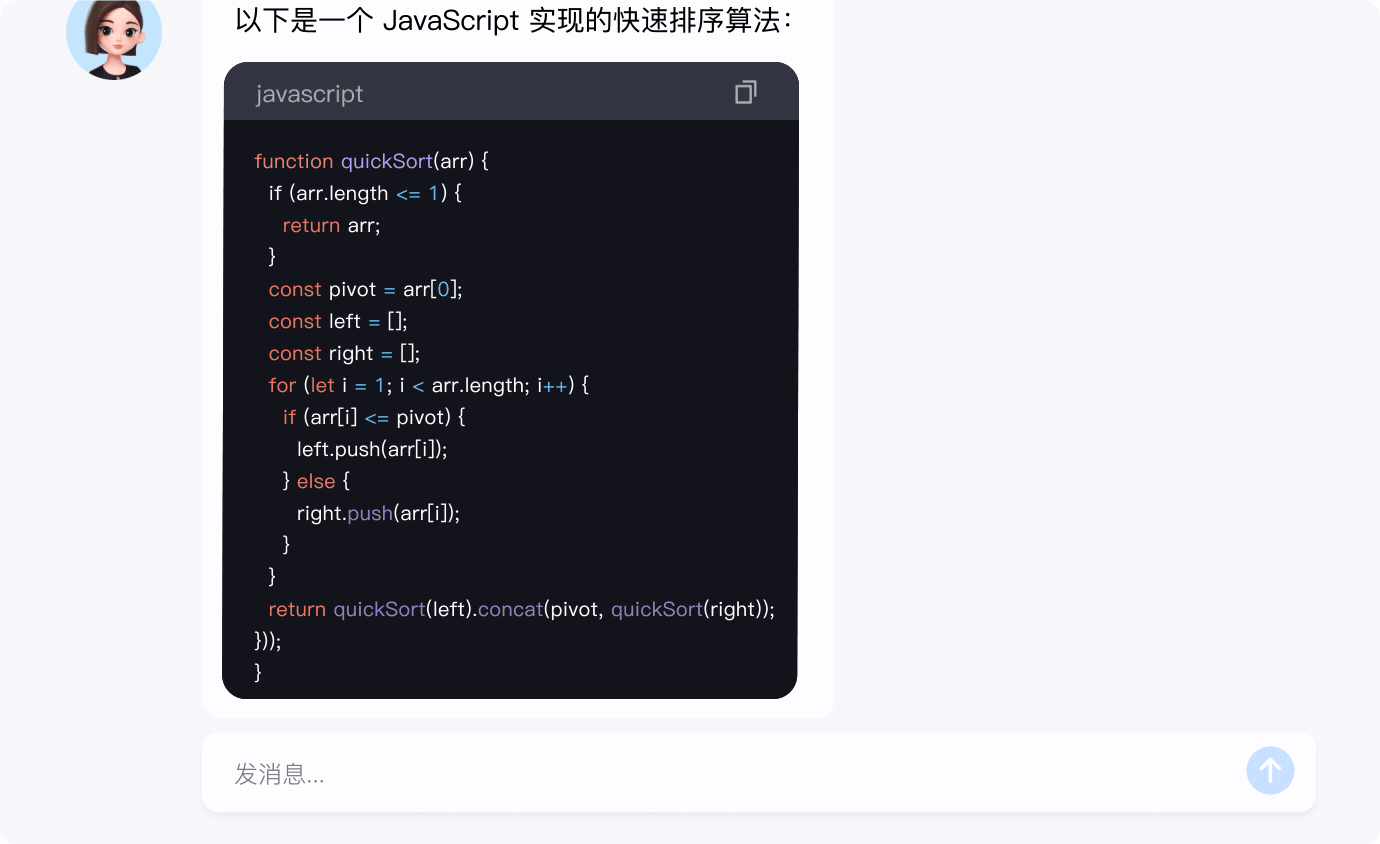
代码生成
- 专业的代码生成能力和知识储备,高效辅助代码生产场景。
-
信息提取
- 深度理解文本信息逻辑关系,从非结构化文本信息中提取准确的结构化信息。

-
逻辑推理
- 通过分析问题前提条件和假设,进行科学推理,提供新的想法和见解。
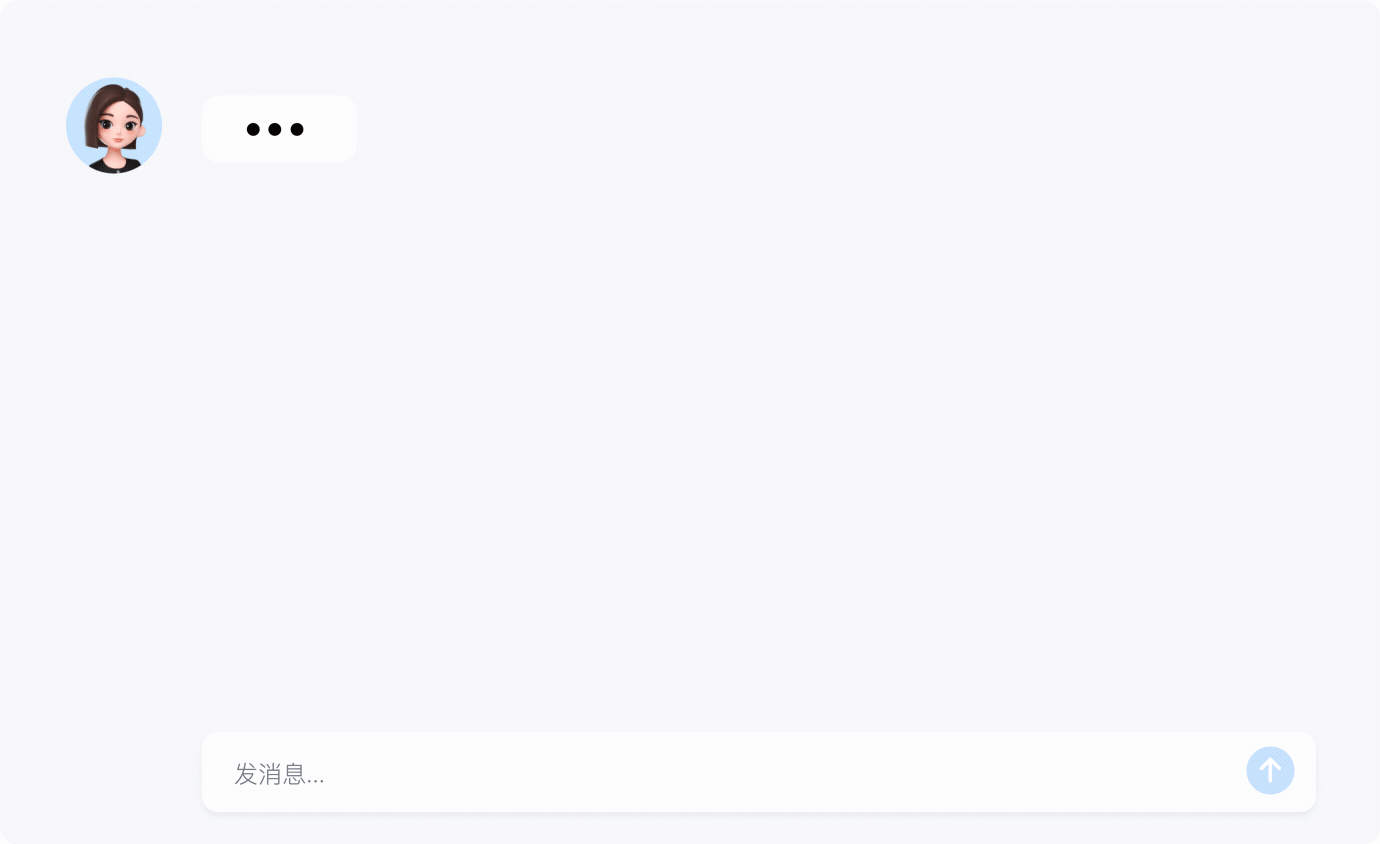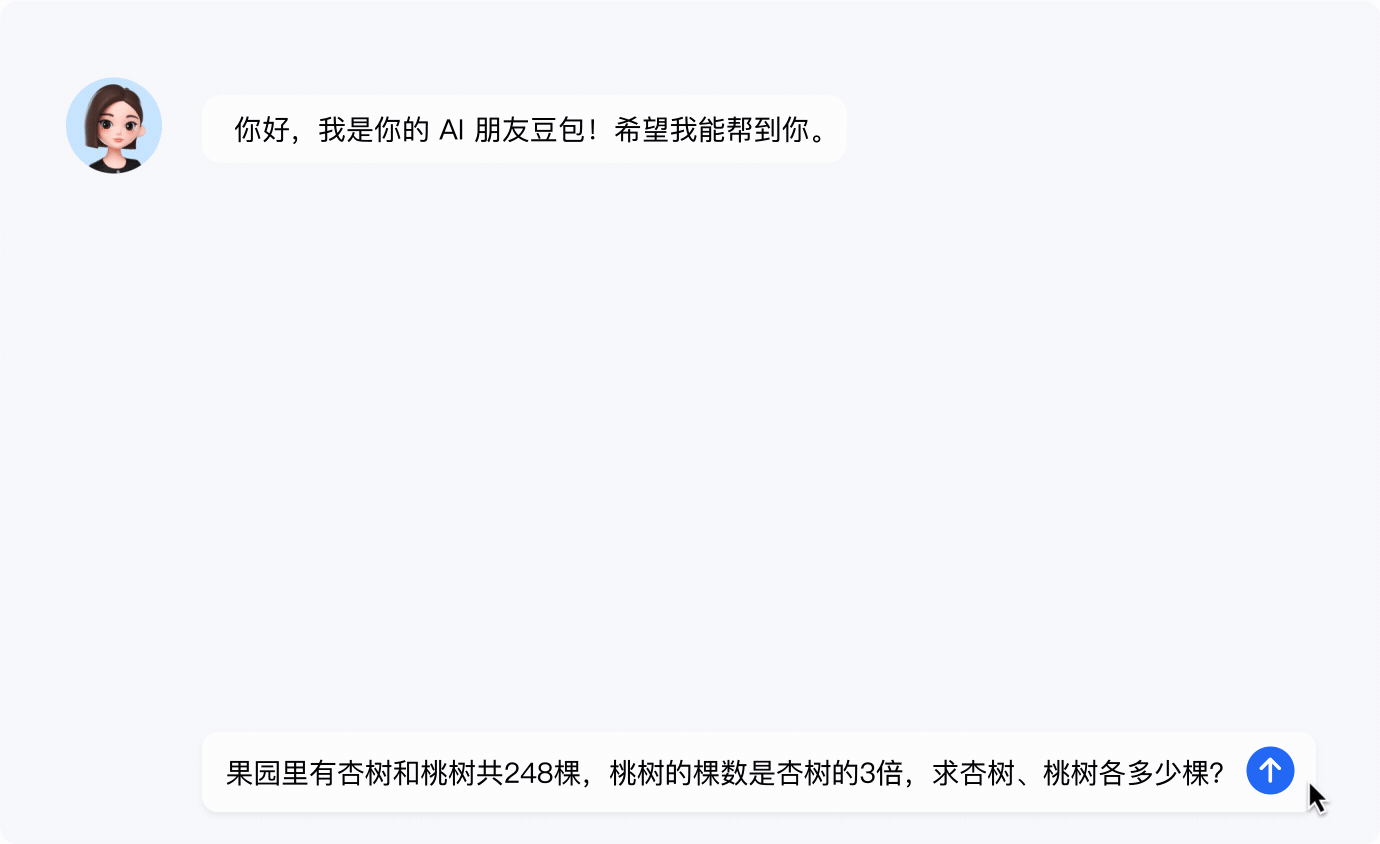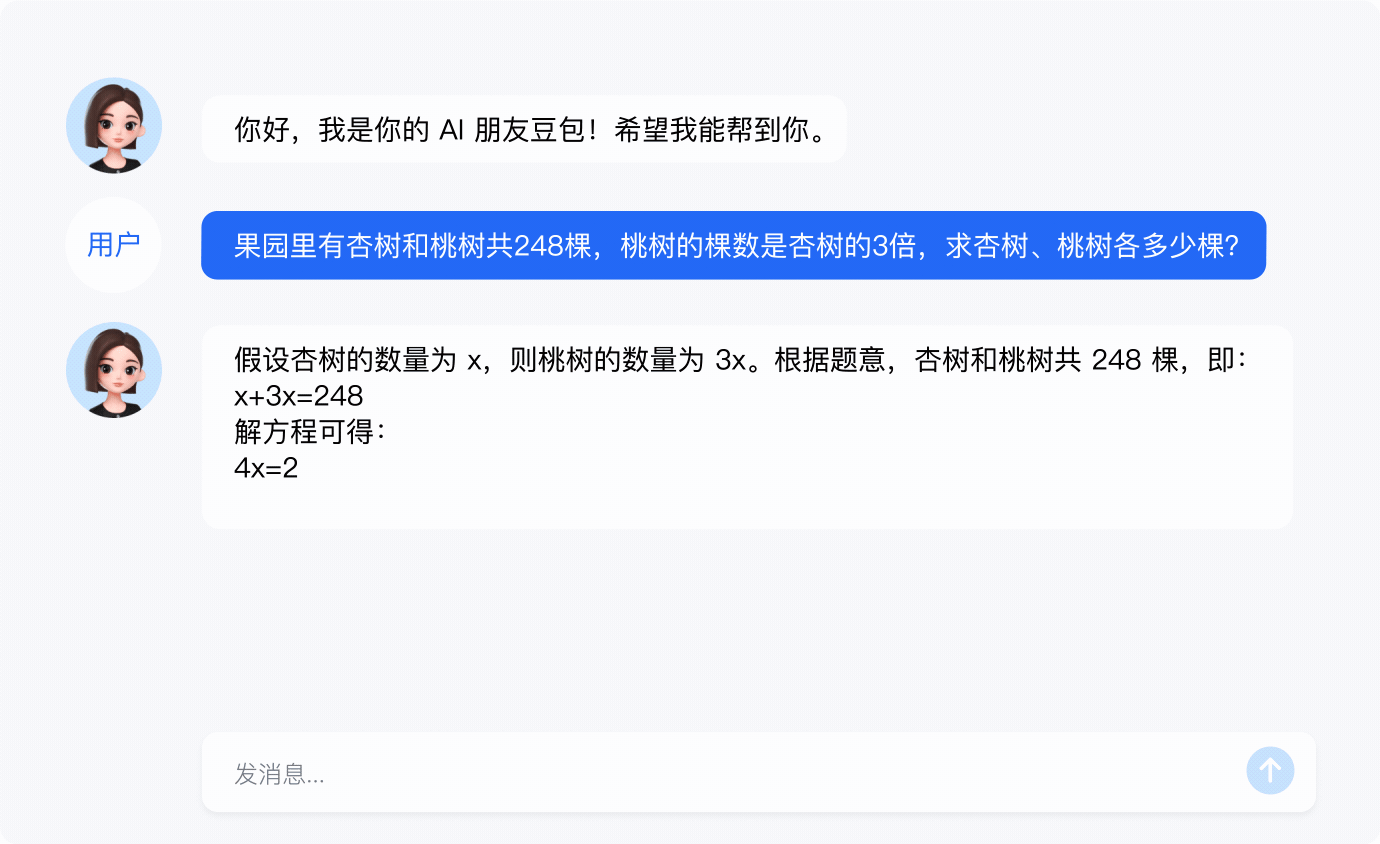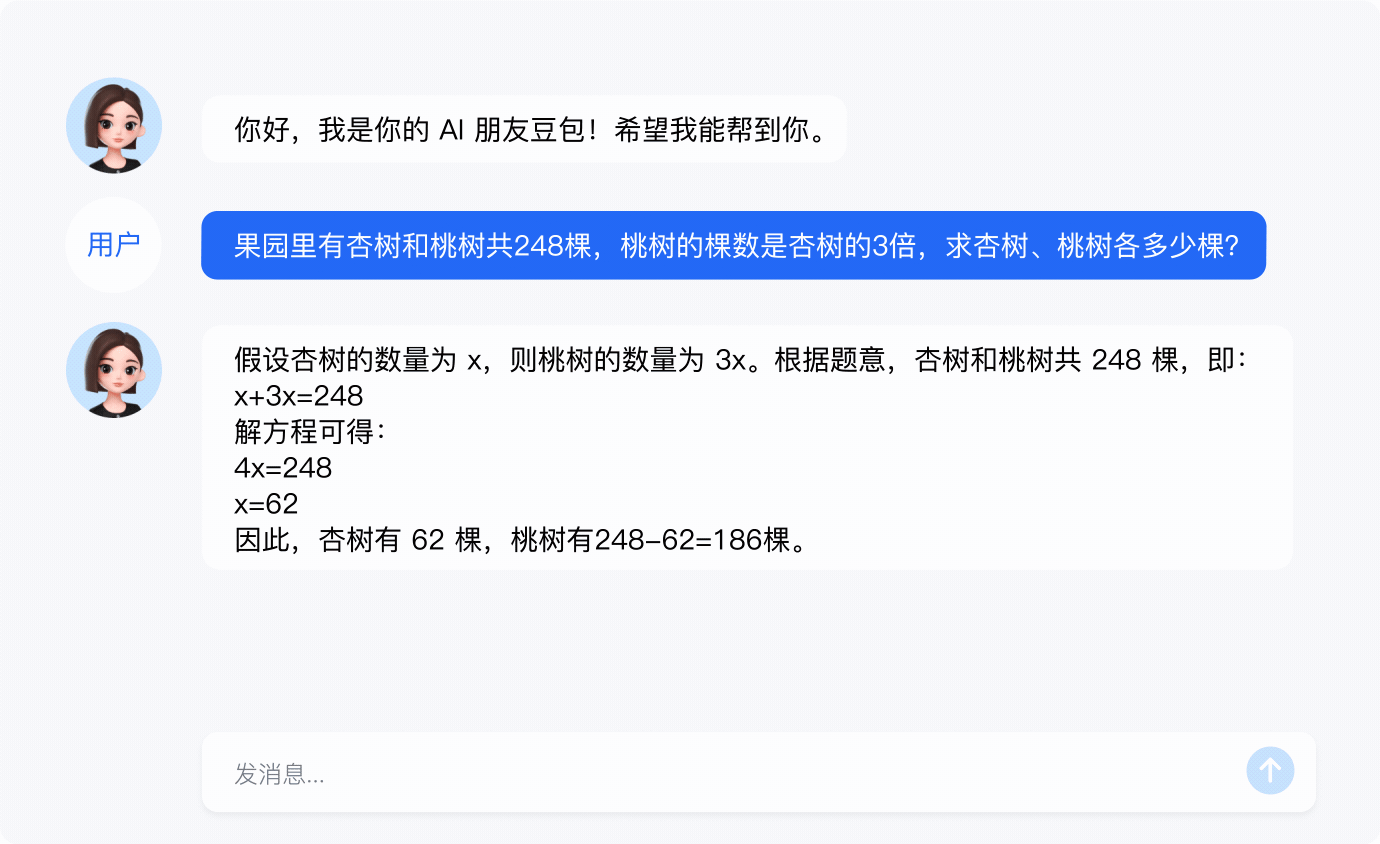
豆包大模型的多样功能既可以应用于企业的生产运营,也能在个人创作及日常生活中提供有效支持,为用户提供高效、灵活的解决方案。










