
# LLaMa/RWKV onnx
:rocket: 请阅读 这个问题 以了解 LLaMa GPU 推理
在此下载 onnx 模型:
| 模型 | 精度 | 大小 | URL | 演示 |
|---|---|---|---|---|
| LLaMa-7B | fp32 | 26GB | huggingface | demo_llama.py |
| LLaMa-7B | fp16 | 13GB | huggingface 或 硬件模型库 | demo_llama.py |
| RWKV-4-palm-430M | fp16 | 920MB | huggingface 或 硬件模型库 | demo_rwkv.py |
新闻
05/18 发布 RWKV-4 onnx 模型,独立脚本和大模型结构比较
05/09 trt 输出错误值,直到问题2928 解决
04/19 移除 GPTQ 零点指导
04/18 从 GPTQ-for-LLaMa 导出混合精度量化表
04/11 添加 13GB onnx-fp16 模型
04/11 添加内存池,支持 2GB 内存笔记本电脑 :star:
04/10 减少 onnx 模型大小至 26GB
04/10 支持 temperature 和 topk 概率分布调整
04/07 添加 onnxruntime 演示
04/05 项目启动
特性
- 发布 LLaMa-7B 和 RWKV-400M onnx 模型及其 onnxruntime 独立演示
- 无需
torch或transformers - 支持内存池,在 2GB 内存的笔记本/PC 上运行(非常慢 :turtle:)
为什么要做这个?
- 可视化。
graphviz在 LLaMa 模型上崩溃。大语言模型的可视化工具必须支持嵌套或操作折叠功能 - 量化。大语言模型经常自我重复,就像 分形。对于 LLaMa 量化,加载解码器主干的一部分就足够了(400MB)。它可以部分量化
- 嵌入式设备。在小板上发生 I/O 错误时使用
dd一个大文件 - 分布式系统。在多个混合设备(FPGA/NPU/GPGPU)上进行推理将变得简单
- onnx 工具。设备制造商对 onnx 的支持已经很好,没有理由忽视它
使用
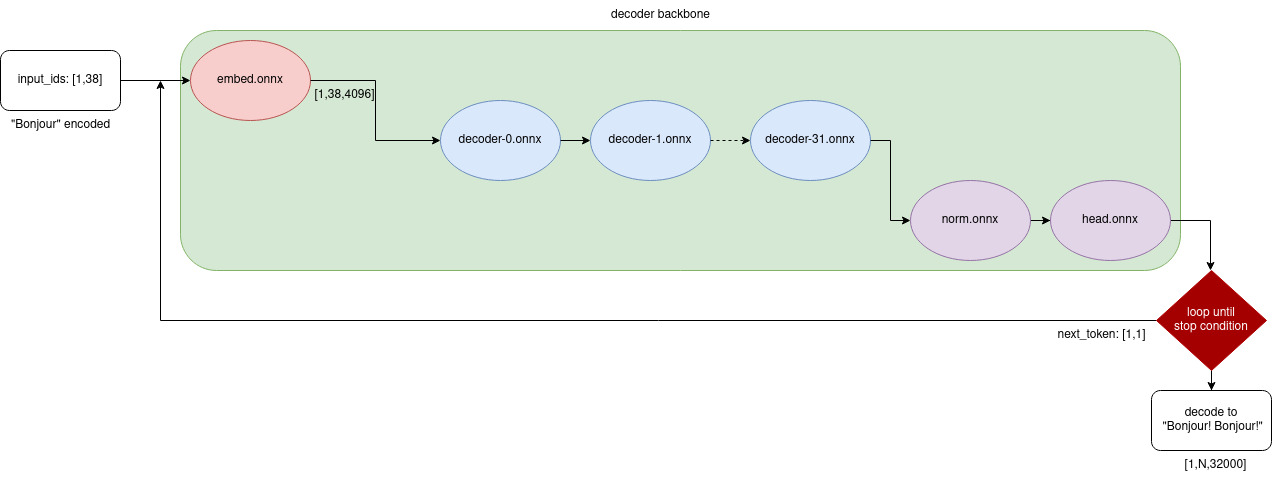
这是调用 LLaMa 的流程图(RWKV 类似):
试试 LLaMa onnxruntime 演示,不需要 torch,并且精度已经检查过。
$ python3 -m pip install -r requirements.txt
$ python3 demo_llama.py ${FP16_ONNX_DIR} "bonjour"
..
# 如果你只有 4GB 内存,使用 `--poolsize`
$ python3 demo_llama.py ${FP16_ONNX_DIR} "bonjour" --poolsize 4
..
Bonjour.
# 尝试更多选项
$ python3 demo_llama.py --help
使用 demo_rwkv.py 运行 RWKV:
$ python3 demo_rwkv.py ${FP16_ONNX_DIR}
导出 RWKV onnx
- git clone RWKV 并下载其模型
- 拷贝 onnx_RWKV_in_150_lines.py 到 ChatRWKV
$ git clone https://github.com/BlinkDL/ChatRWKV --depth=1
$ cp llama.onnx/tools/onnx_RWKV_in_150_lines.py ChatRWKV
$ cd ChatRWKV
$ mkdir models
$ python3 onnx_RWKV_in_150_lines.py
然后你将得到 onnx 文件。
$ ls -lah models
..
导出 LLaMa onnx
步骤1 转换至 HF 格式
这些模型从 alpaca huggingface 转换而来。
-
如果你使用的是 LLaMa 或 llama.cpp,先转换至 HF 格式。步骤如下:
# 安装 transformers master $ git clone https://github.com/huggingface/transformers $ cd transformers && python3 setup.py install .. $ cd src/transformers $ python3 src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir ${LLaMa_PATH} --model_size 7B --output_dir ${HF_PATH} -
如果你使用的是 alpaca-lora,使用 这个脚本 合并 LoRA 权重。
-
如果你使用的是 alpaca,请跳到步骤2。
步骤2 torch.onnx.export
将 transformers 切换到这个分支,运行单次推理。
$ python3 tools/export-onnx.py ${PATH_ALPACA_7B}
步骤3 转换至 fp16/tvm
使用 onnxconverter-common.float16
$ cd tools
$ python3 -m pip install -r requirements.txt
$ python3 convert-fp32-to-fp16.py ${FP32_PATH} ${FP16_PATH}
或使用 relay.vm 转换 tvm
$ cd tools
$ python3 convert-to-tvm.py ${ONNX_PATH} ${OUT_DIR}
注意事项
- 关于模型结构,请阅读 LLaMa 和 RWKV 结构对比
- 我已比较了
onnxruntime-cpu和torch-cuda的输出值,最大误差是 0.002,不错 - 现在的
demo_llama.py状态相当于这些配置
temperature=0.1
total_tokens=2000
top_p=1.0
top_k=40
repetition_penalty=1.0
- 混合精度内核优化正在进行中。这里 是部分指导。












{kind=link}