
 访问官网
访问官网 Github
GithubVectorFusion: 通过抽象像素扩散模型实现文本到SVG转换
在这项工作中,作者展示了一个在图像像素表示上训练的文本条件扩散模型可以用来生成可导出SVG的矢量图形。

VectorFusion渲染过程。(64路径, 72视频, 5千)
更新
- [2024年1月] 🔥 我们发布了SVGDreamer。SVGDreamer是一种新颖的文本引导矢量图形合成方法。该方法同时考虑了矢量图形的编辑和合成质量。
- [2023年12月] 🔥 我们发布了PyTorch-SVGRender。Pytorch-SVGRender是用于图像矢量化的最先进可微渲染方法的首选库。
- [2023年10月] 🔥 我们发布了DiffSketcher代码。一种通过文本提示合成矢量草图的方法。
- [2023年10月] 🔥 我们复现了VectorFusion代码。
安装
逐步安装
创建新的conda环境:
conda create --name vf python=3.10
conda activate vf
安装pytorch和以下库:
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
pip install omegaconf BeautifulSoup4
pip install shapely
pip install opencv-python scikit-image matplotlib visdom wandb
pip install triton numba
pip install numpy scipy timm scikit-fmm einops
pip install accelerate transformers safetensors datasets
安装CLIP:
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
安装diffusers:
pip install diffusers==0.20.2
安装xformers(需要python=3.10):
conda install xformers -c xformers
安装diffvg:
git clone https://github.com/BachiLi/diffvg.git
cd diffvg
git submodule update --init --recursive
conda install -y -c anaconda cmake
conda install -y -c conda-forge ffmpeg
pip install svgwrite svgpathtools cssutils torch-tools
python setup.py install
Docker使用
docker run --name vectorfusion --gpus all -it --ipc=host ximingxing/svgrender:v1 /bin/bash
快速开始
案例:悉尼歌剧院
提示词: 悉尼歌剧院。
风格: 图标
预览:
 |  |  |
|---|---|---|
| (a) 使用Stable Diffusion采样的栅格图像 | (b) 通过LIVE将栅格图像转换为矢量图 | (c) VectorFusion:通过LSDS微调 |
LIVE渲染过程:
| 迭代0 | 迭代500 | 迭代1000 | 迭代1500 | 迭代2500 | 迭代3500 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
VectorFusion渲染过程:
| 迭代0 | 迭代100 | 迭代300 | 迭代400 | 迭代700 | 迭代1000 |
|---|---|---|---|---|---|
 |  |  |  |  | |
脚本:
python run_painterly_render.py \
-c vectorfusion.yaml \
-pt "悉尼歌剧院。极简平面2D矢量图标。线性颜色。白色背景。ArtStation流行" \
-save_step 50 \
-update "K=6" \
-respath ./workdir/SydneyOperaHouse \
-d 15486 \
--download
-c即--config:配置文件。-save_step:用于保存结果的步长(调用过于频繁会导致时间更长)。-update:用于编辑配置文件的超参数的工具,因此无需创建新的yaml文件。-pt即--prompt:文本提示。-respath即--results_path:保存结果的文件夹。-d即--seed:随机种子。--download:首次运行时自动从huggingface下载模型。
可选:
-npt,即--negative_prompt:负面文本提示。-mv,即--make_video:制作渲染过程的视频(这将花费更长时间)。-frame_freq,即--video_frame_freq:保存图像的步数间隔。-framerate,即--video_frame_rate:控制输出视频的播放速度。
案例:明代花瓶
提示词: 皮革桌面上的明代花瓶照片。
风格: 图标
预览:
 |  |  |
|---|---|---|
| (a) 使用Stable Diffusion采样的栅格图像 | (b) 通过LIVE将栅格图像转换为矢量图 | (c) VectorFusion:通过LSDS微调 |
脚本:
python run_painterly_render.py -c vectorfusion.yaml -pt "皮革桌面上的明代花瓶照片。极简平面2D矢量图标。线性颜色。白色背景。ArtStation流行" -save_step 50 -respath ./workdir/vase -d 683692
案例:宇航员
提示词: 宇航员形象。
风格: 图标
预览:
 |  |  |
|---|---|---|
| (a) 使用Stable Diffusion生成的栅格图像样本 | (b) 通过LIVE将栅格图像转换为矢量图 | (c) VectorFusion: 通过LSDS进行微调 |
脚本:
python run_painterly_render.py -c vectorfusion.yaml -pt "宇航员形象。极简平面2D矢量图标。线性配色。白色背景。Artstation热门" -save_step 50 -respath ./workdir/astronaut -d 522178
案例:吉他
提示词: 电吉他
风格: 像素艺术
预览:
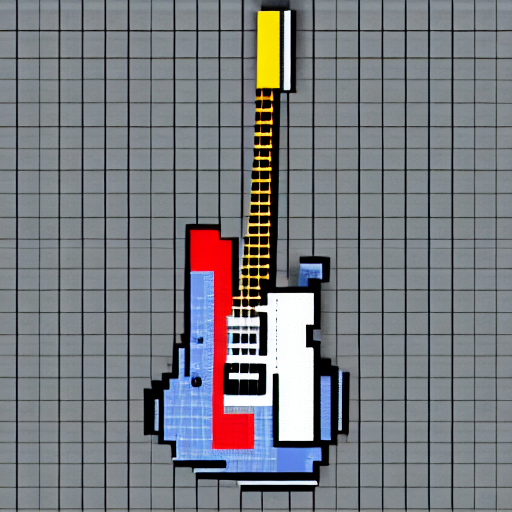 |  |  |
|---|---|---|
| (a) 使用Stable Diffusion生成的栅格图像样本 | (b) 通过LIVE将栅格图像转换为矢量图 | (c) VectorFusion: 通过LSDS进行微调 |
脚本:
python run_painterly_render.py -c vectorfusion.yaml -pt "电吉他。像素艺术。Artstation热门" -save_step 50 -respath ./workdir/guitar -update "style=pixelart" -d 445997
案例:龙
提示词: 一条喷火龙的水彩画。
风格: 素描
预览:
 |  |  |
|---|---|---|
| SVG初始化 | VectorFusion微调500步 | VectorFusion微调1500步 |
脚本:
python run_painterly_render.py -c vectorfusion.yaml -pt "一条喷火龙的水彩画。极简2D线条绘画。Artstation热门" -save_step 50 -respath ./workdir/dragon-sketch -update "style=sketch num_segments=5 radius=0.5 sds.num_iter=1500" -d 106764
其他案例
# 素描风格
CUDA_VISIBLE_DEVICES=0 python run_painterly_render.py -c vectorfusion.yaml -pt "一条喷火龙的水彩画。极简2D线条绘画。Artstation热门" -save_step 50 -respath ./workdir/dragon-sketch -update "style=sketch skip_live=True num_paths=32 num_segments=5 radius=0.5 sds.num_iter=1500" -rdbz
CUDA_VISIBLE_DEVICES=0 python run_painterly_render.py -c vectorfusion.yaml -pt "一只猫。极简2D线条绘画。Artstation热门" -save_step 50 -respath ./workdir/cat-sketch -update "style=sketch skip_live=True num_paths=32 num_segments=5 radius=0.5 sds.num_iter=1500" -rdbz
更多示例:
- 查看 Examples.md 获取更多案例。
更多脚本:
- 查看 Run.md 获取更多脚本。
致谢
本项目基于以下仓库构建:
我们衷心感谢这些作者的杰出工作。
引用
如果您在研究中使用了这份代码,请引用以下论文:
@inproceedings{jain2023vectorfusion,
title={Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models},
author={Jain, Ajay and Xie, Amber and Abbeel, Pieter},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1911--1920},
year={2023}
}
@inproceedings{xing2023diffsketcher,
title={DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion Models},
author={XiMing Xing and Chuang Wang and Haitao Zhou and Jing Zhang and Qian Yu and Dong Xu},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=CY1xatvEQj}
}
许可证
本仓库采用MIT许可证。










