

将数据科学团队无缝连接到云基础设施。

[![PyPi][pypi-shield]][pypi-url] [![PyPi][pypiversion-shield]][pypi-url] [![PyPi][downloads-shield]][downloads-url] [![Contributors][contributors-shield]][contributors-url] [![License][license-shield]][license-url]
⭐️ 显示您的支持
如果您觉得ZenML有帮助或有趣,请考虑在GitHub上给我们一个星标。您的支持有助于推广这个项目,并让其他人知道它值得一看。
谢谢您的支持!🌟

🤸 快速启动

通过PyPI安装ZenML。需要Python 3.8 - 3.11:
pip install "zenml[server]" notebook
通过运行以下命令进行引导式快速启动:
zenml go
🪄 简单、集成、端到端的MLOps
通过最少的代码更改创建机器学习流水线
ZenML是一个MLOps框架,旨在帮助数据科学家或ML工程师标准化机器学习实践。只需在现有的Python函数中添加@step和@pipeline即可开始。以下是一个玩具示例:
from zenml import pipeline, step
@step # 只需添加这个装饰器
def load_data() -> dict:
training_data = [[1, 2], [3, 4], [5, 6]]
labels = [0, 1, 0]
return {'features': training_data, 'labels': labels}
@step
def train_model(data: dict) -> None:
total_features = sum(map(sum, data['features']))
total_labels = sum(data['labels'])
print(f"使用{len(data['features'])}个数据点训练模型。"
f"特征总和是{total_features},标签总和是{total_labels}")
@pipeline # 这个函数将步骤结合在一起
def simple_ml_pipeline():
dataset = load_data()
train_model(dataset)
if __name__ == "__main__":
run = simple_ml_pipeline() # 调用此函数运行流水线
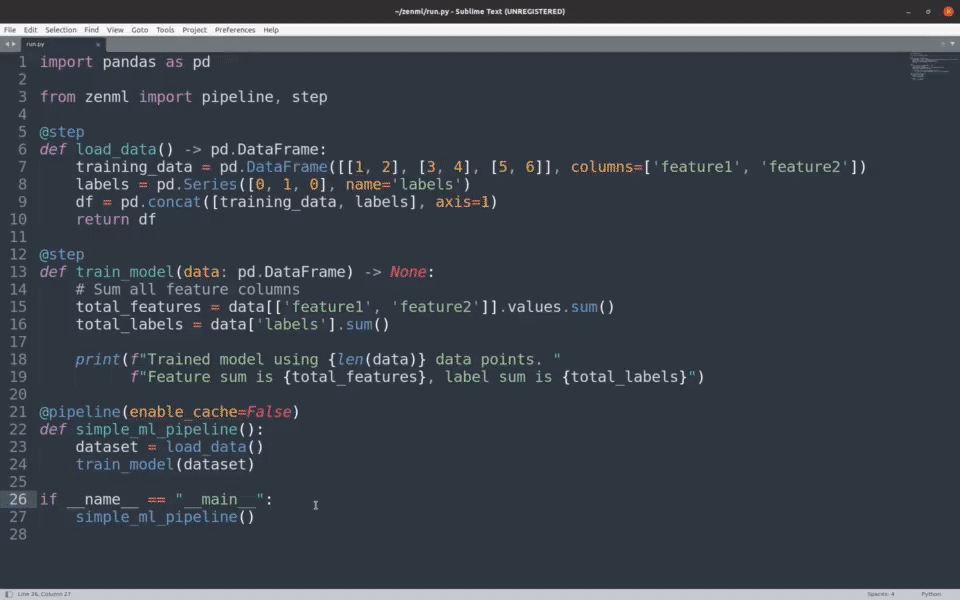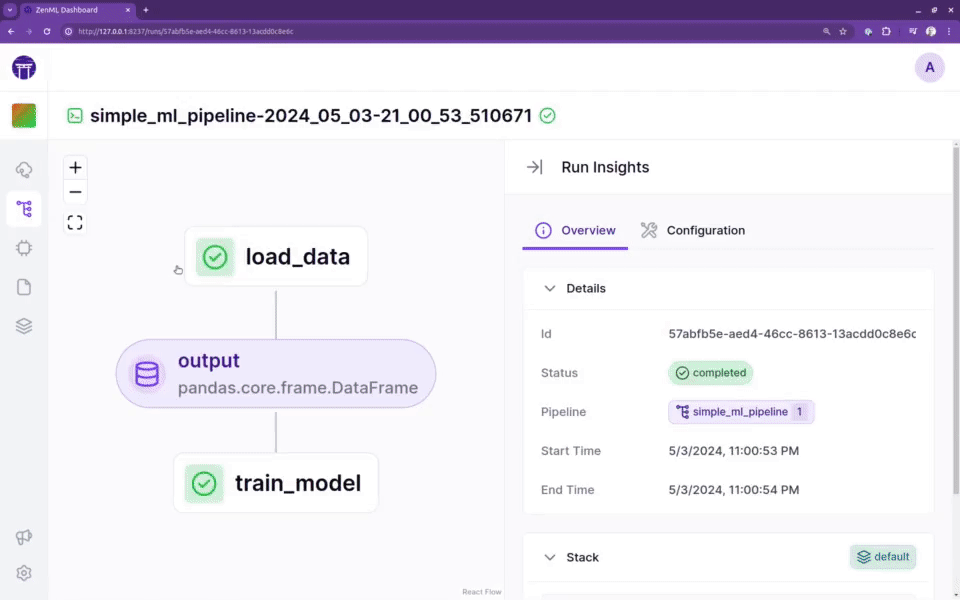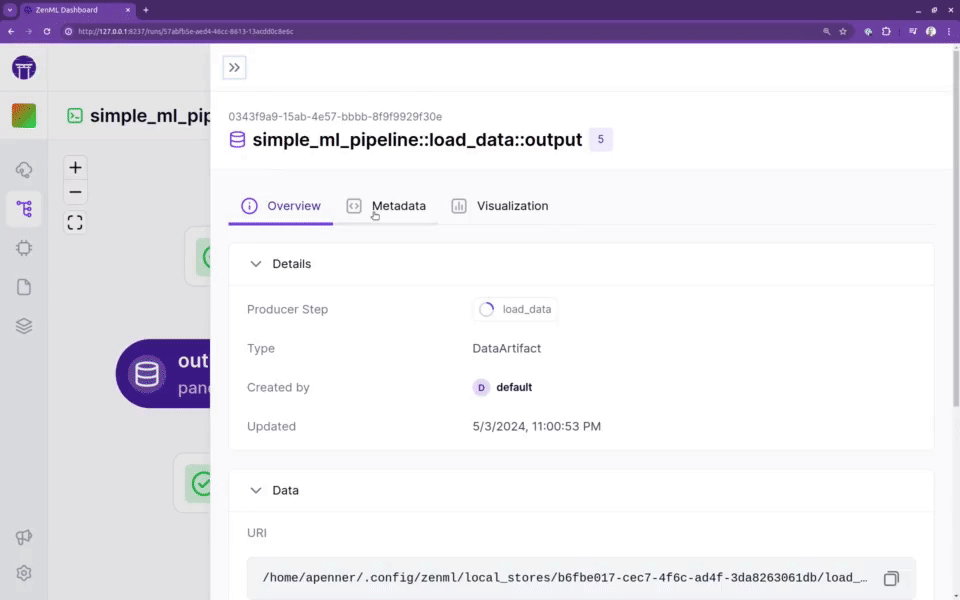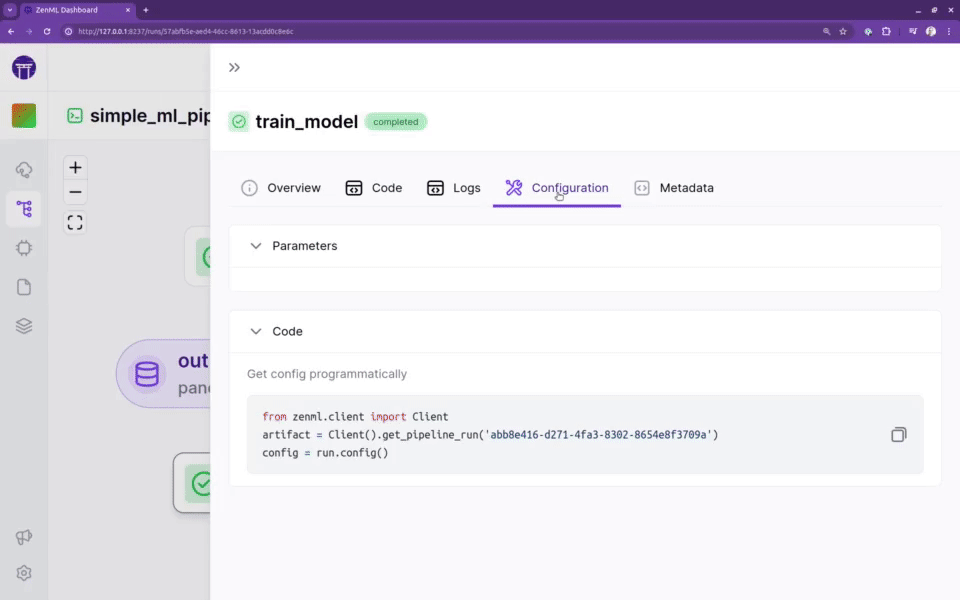
轻松配置MLOps堆栈或重用现有基础设施
该框架是为从业者提供一个柔和的切入点,以在几乎不需要了解底层基础设施复杂性的情况下构建复杂的ML流水线。ZenML流水线可以在AWS、GCP、Azure、Airflow、Kubeflow甚至Kubernetes上运行,而无需修改任何代码或了解底层内部结构。
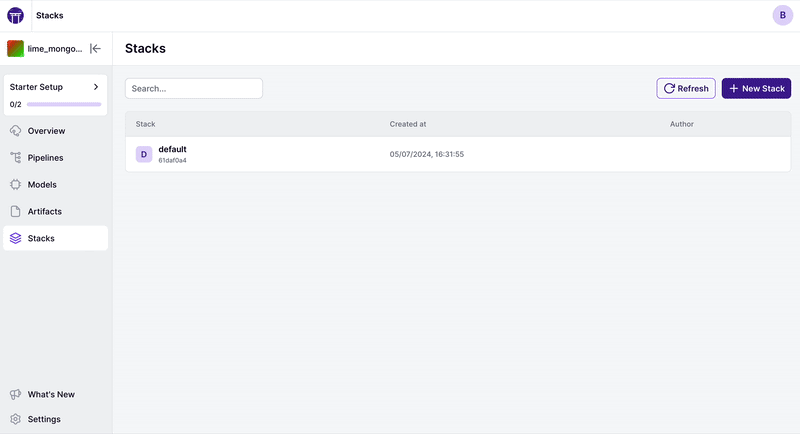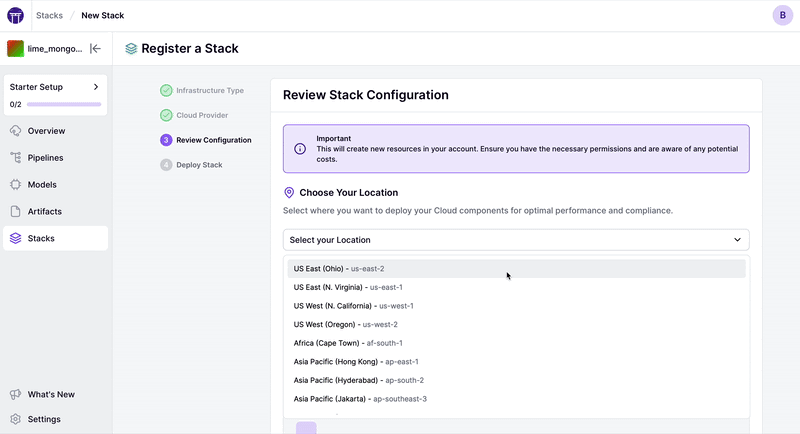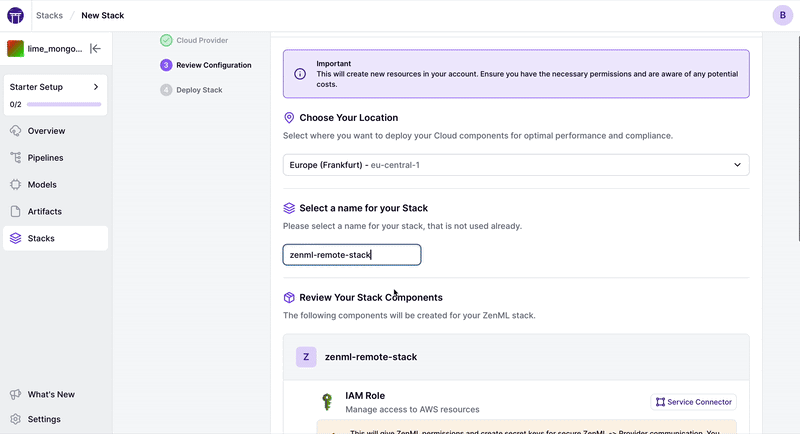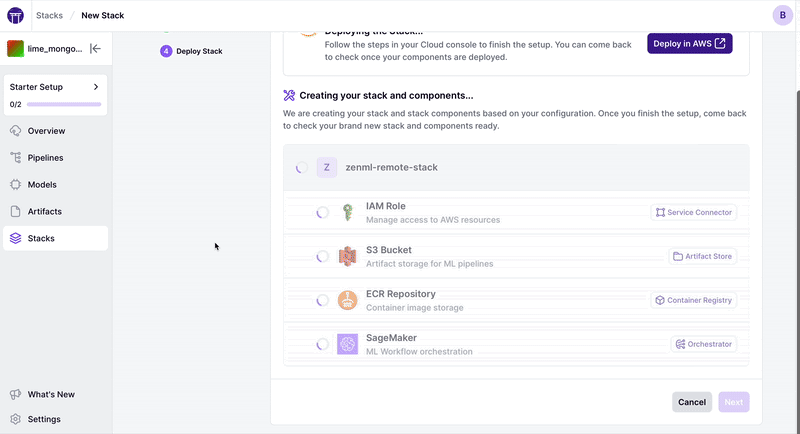
ZenML提供了不同的功能,帮助人们在远程环境中快速入门。如果您想在所选的云提供商上从头开始部署一个远程堆栈,您可以通过仪表板使用一键部署功能:
或者,使用我们的CLI命令:
zenml stack deploy --provider aws
或者,如果所需的基础设施已经部署,可以通过堆栈向导无缝注册一个云堆栈:
zenml stack register <STACK_NAME> --provider aws
阅读更多关于ZenML堆栈的信息。
在生产基础设施上轻松运行工作负载
一旦配置了MLOps堆栈,您可以轻松地在其上运行工作负载:
zenml stack set <STACK_NAME>
python run.py
from zenml.config import ResourceSettings, DockerSettings
@step(
settings={
"resources": ResourceSettings(memory="16GB", gpu_count="1", cpu_count="8"),
"docker": DockerSettings(parent_image="pytorch/pytorch:1.12.1-cuda11.3-cudnn8-runtime")
}
)
def training(...):
...
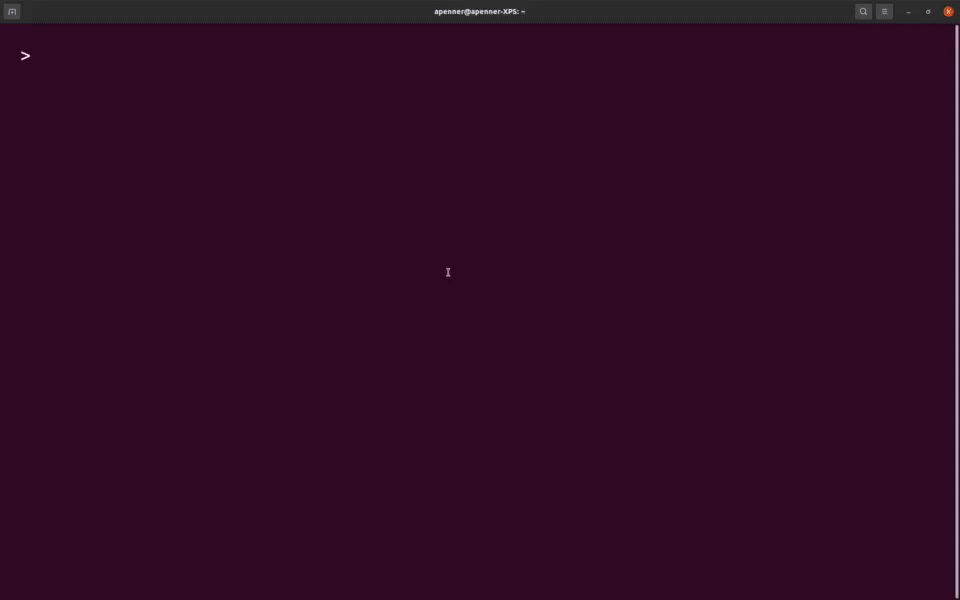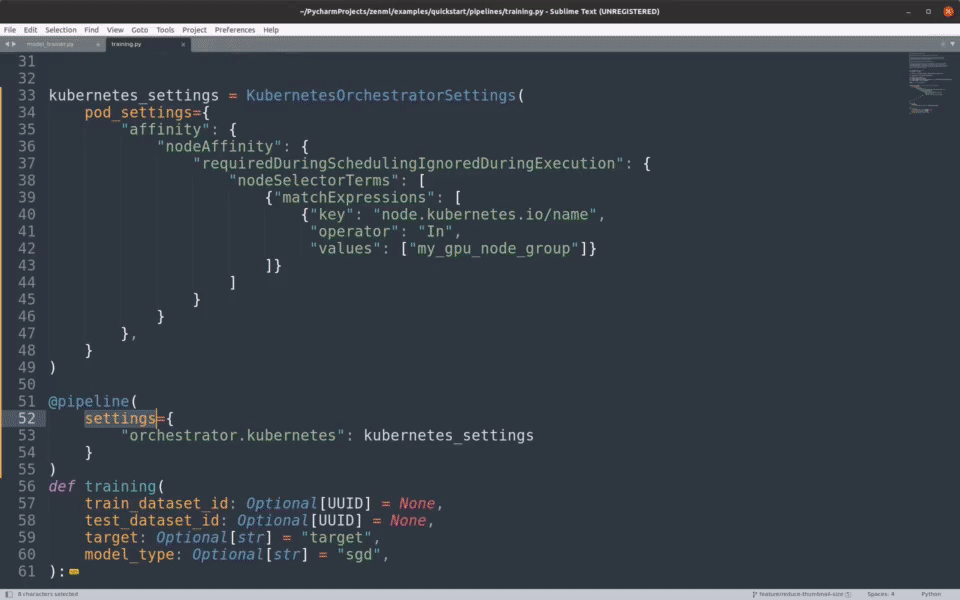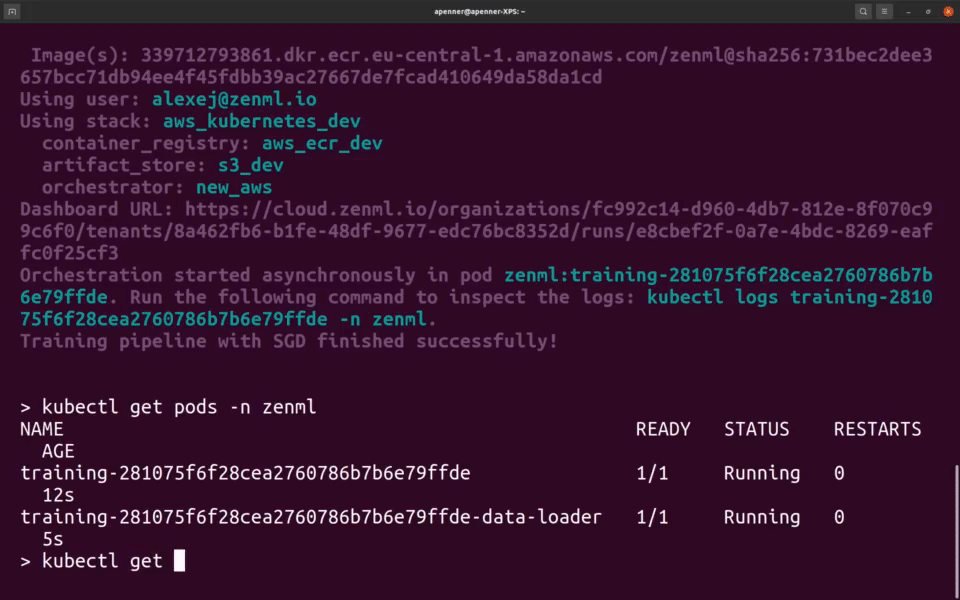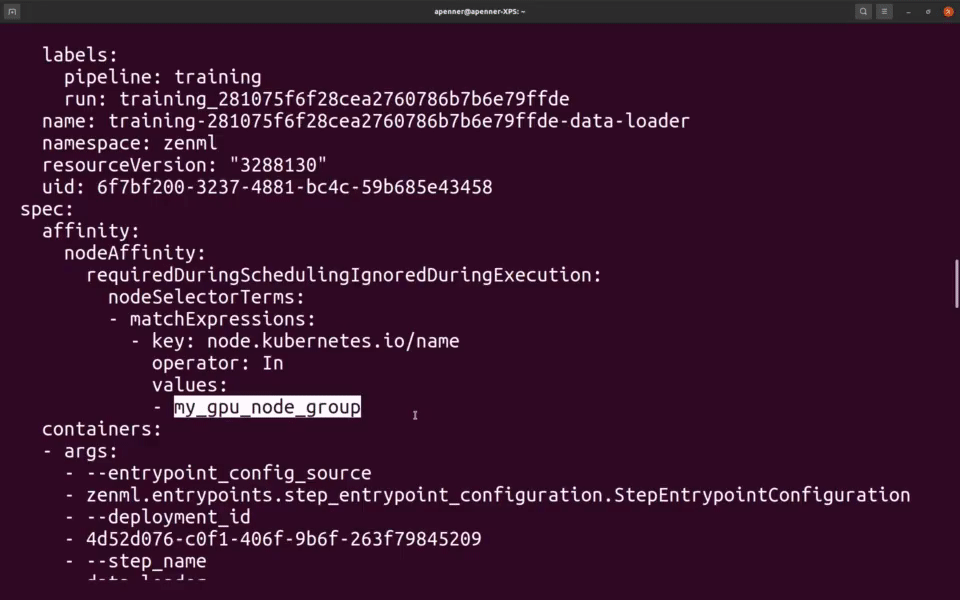
跟踪模型、流水线和工件
创建一个完整的族谱,记录是谁、在何地、使用什么数据和模型生成了哪些工件。
您将能够找到是谁在什么时间、使用什么数据、在哪个代码版本上生成了哪个模型。这保证了完全的可复现性和可审核性。
from zenml import Model
@step(model=Model(name="classification"))
def trainer(training_df: pd.DataFrame) -> Annotated["model", torch.nn.Module]:
...
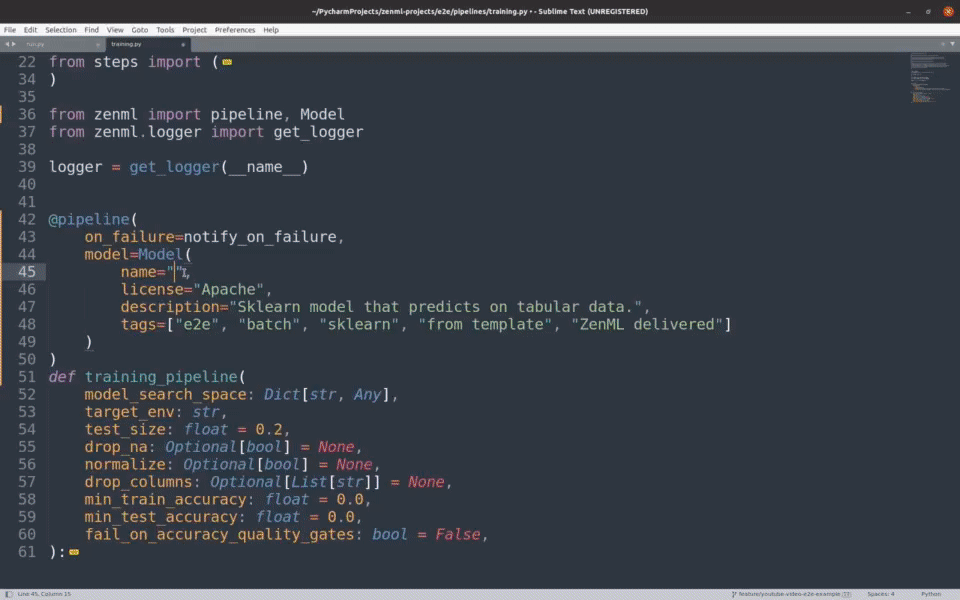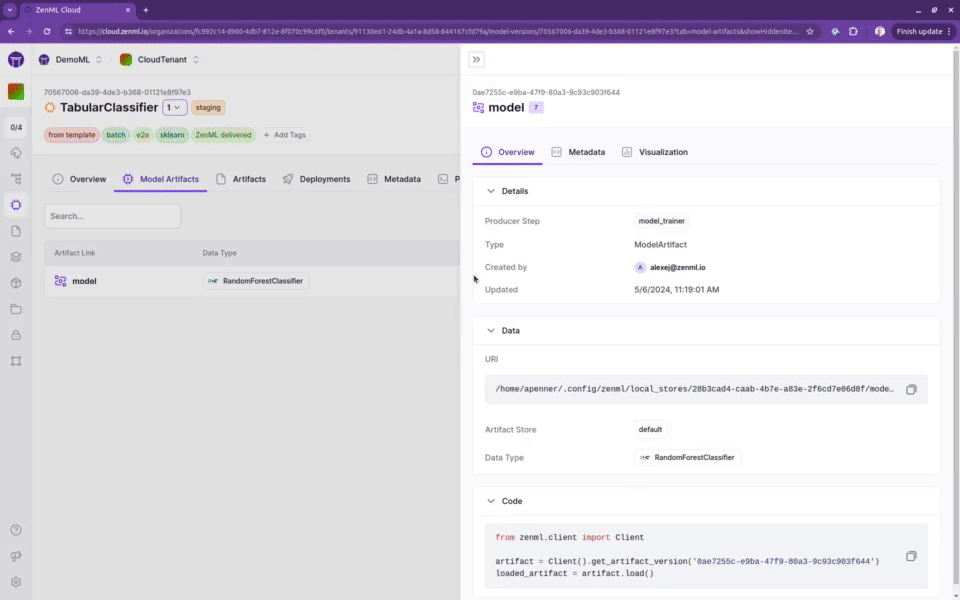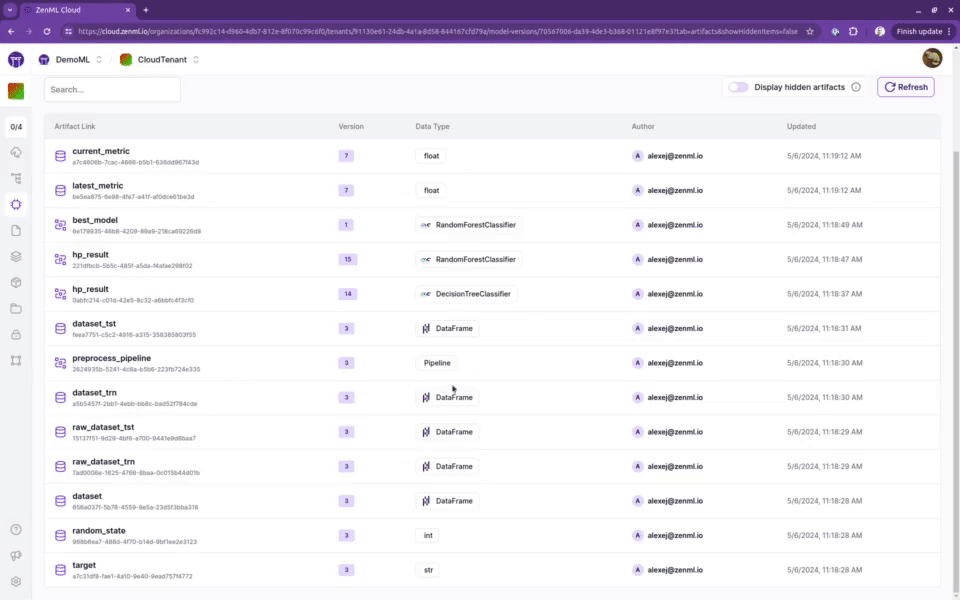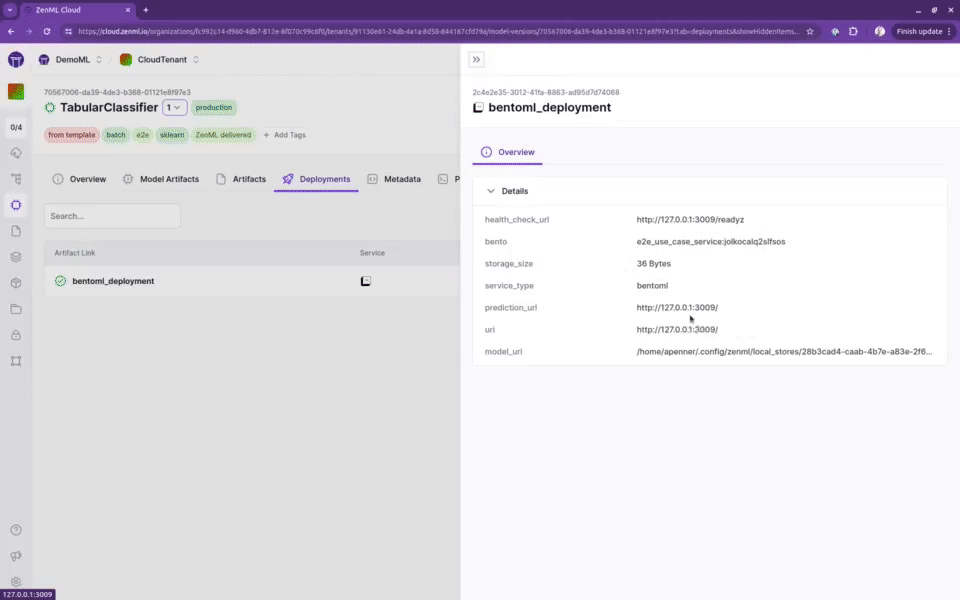
专为机器学习设计,与您最喜爱的工具集成
尽管ZenML本身带来了很多价值,但它也集成了现有的工具和基础设施,无需锁定。
from bentoml._internal.bento import bento
@step(on_failure=alert_slack, experiment_tracker="mlflow")
def train_and_deploy(training_df: pd.DataFrame) -> bento.Bento
mlflow.autolog()
...
return bento
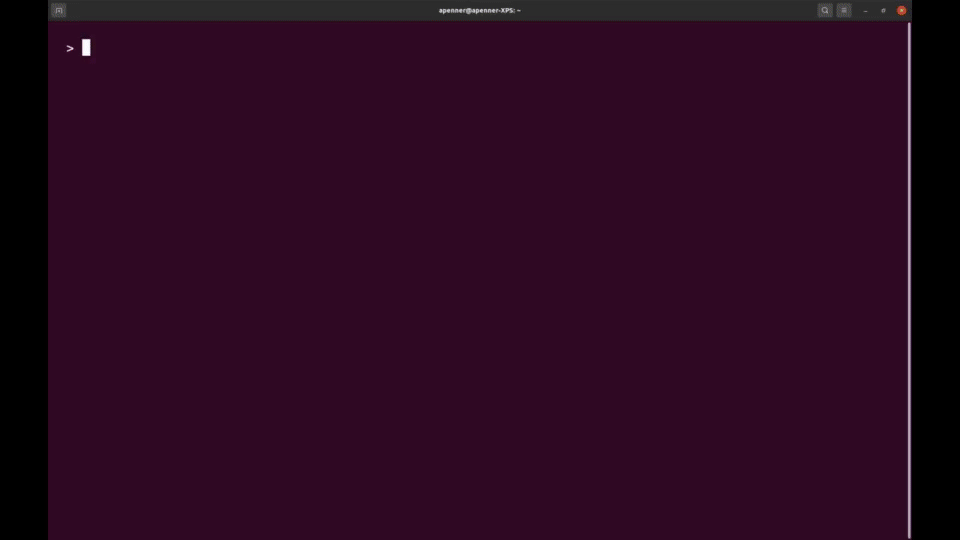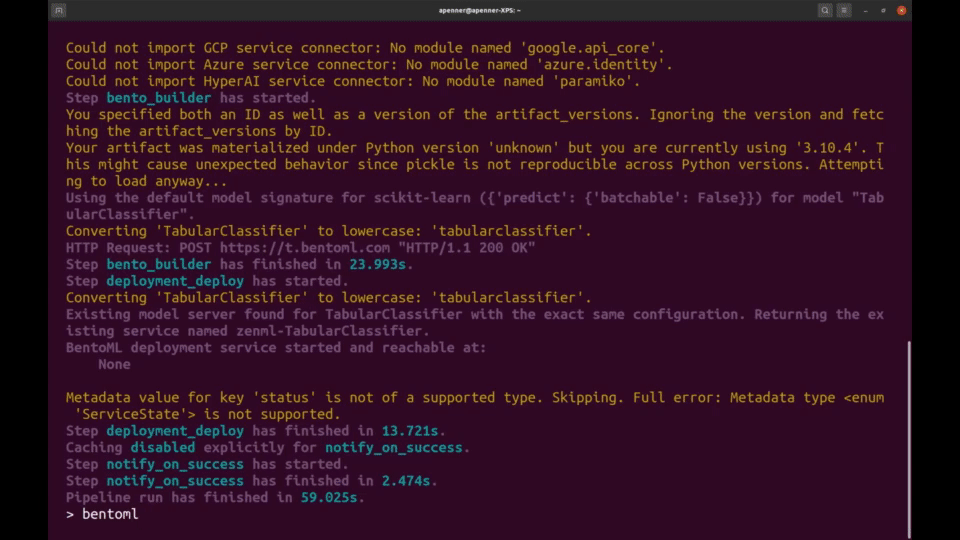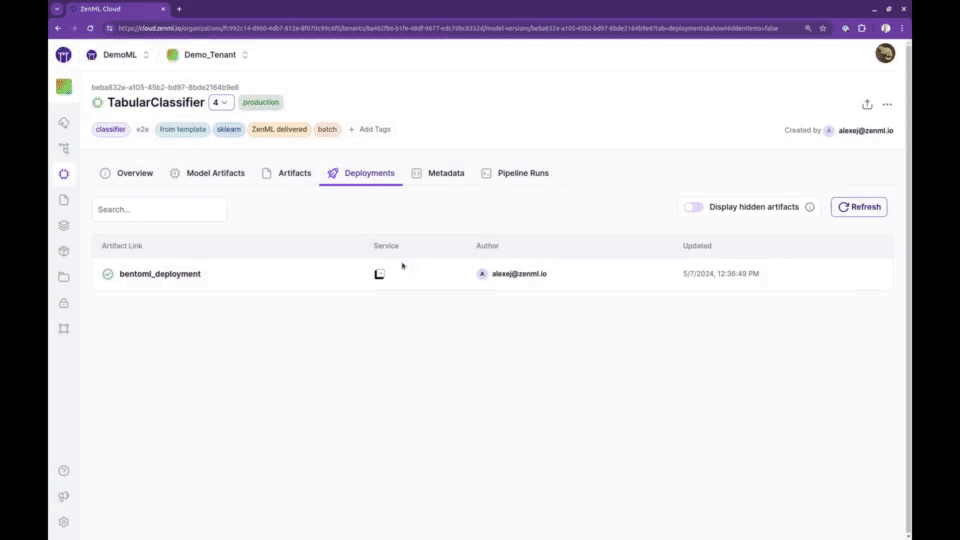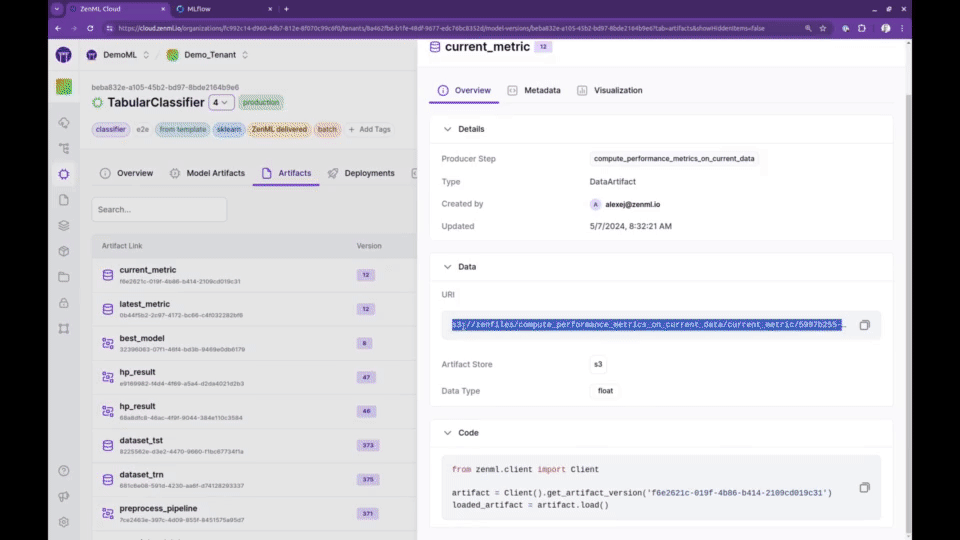
🖼️ 学习
学习ZenML的最佳方式是阅读文档。我们建议从入门指南开始,快速上手。
如果您是视觉学习者,这段11分钟的免费视频教程也是一个不错的开始:

最后,这里有一些其他的示例和用例可供参考:
- E2E 批量推理: 用于表格机器学习的特征工程、训练和推理管道。
- 使用 BERT 的基础 NLP: 以自然语言处理为重点的特征工程、训练和推理。
- 使用 Langchain 和 OpenAI 的 LLM RAG 管道: 使用 Langchain 创建一个简单的 RAG 管道。
- Huggingface 模型到 Sagemaker 端点: 在 Amazon Sagemaker 和 HuggingFace 上实现自动化 MLOps。
- LLMops: 使用 ZenML 进行 LLM 的完整指南。
🔋 部署 ZenML
为了实现完整功能,ZenML 应部署在云端,以启用团队协作功能,成为团队的中央 MLOps 界面。
目前,有两种主要方式来部署 ZenML:
- ZenML Pro: ZenML Pro 提供 SaaS 版本,带有一个控制面板,用于创建和管理多个 ZenML 服务器。ZenML 专业团队管理和维护这些服务器,减轻了您的服务器管理负担。此外还提供诸如 RBAC、模型控制面板等更多功能。
- 自托管部署: 或者,您可以选择在您自己的自托管环境中部署 ZenML。这可以通过各种方法实现,包括使用我们的 CLI、Docker、Helm 或 HuggingFace Spaces。
使用 VS Code 的 ZenML
ZenML 具有一个VS Code 扩展,允许您直接从编辑器中检查您的堆栈和管道运行。该扩展还允许您在不需要输入任何 CLI 命令的情况下切换您的堆栈。
🖥️ VS Code 扩展展示!
🗺 路线图
ZenML 是在公开环境中构建的。路线图 是 ZenML 社区了解产品短期、中期和长期发展方向的定期更新的可信来源。
ZenML 由一支核心团队管理,他们负责做出关键决策并吸收来自社区的反馈。该团队通过各种渠道监督反馈,您可以通过以下方式直接影响路线图:
- 在我们的讨论板上为您最想要的功能投票。
- 在我们的Slack 频道上开启一个讨论。
- 在我们的 GitHub 仓库中创建一个 Issue。
🙌 贡献与社区
我们希望与我们的社区一起开发 ZenML!最好的开始方式是从[good-first-issue标签](https://github.com/issues?q=is%3Aopen+is%3Aissue+archived%3Afalse+user%3Azenml-io+label%3A%22good+first+issue%22)中选择任何 Issue 并提交一个 Pull Request!
如果您想贡献,请查阅我们的贡献指南以了解所有相关细节。
🆘 获取帮助
首要联系点应该是我们的 Slack 群组。询问关于错误或特定用例的问题,核心团队中的某人会回应。或者,如果您更愿意,可以在我们的 GitHub 仓库中打开一个 Issue。
⭐️ 表示支持
如果您觉得 ZenML 有帮助或有趣,请考虑在 GitHub 上给我们一个星标。您的支持有助于推广该项目,并让其他人知道它值得一试。
感谢您的支持!🌟
📜 许可证
ZenML 根据 Apache 许可证 2.0 版本的条款分发。许可证的完整版本可在此仓库中的许可证文件中找到。对该项目所做的任何贡献都将根据 Apache 许可证 2.0 版本获得许可。
 Slack 社区
Slack 社区 








