
什么是anomalize?
anomalize是一个强大的R包,专门用于时间序列数据的异常检测。它由Business Science开发,旨在提供一个简单而高效的异常检测工作流程。无论是单个时间序列还是成百上千的时间序列,anomalize都能轻松应对。
anomalize的主要特点
-
整洁的工作流程: anomalize采用了tidyverse风格的语法,使得异常检测过程更加直观和易于理解。
-
高度可扩展: 通过与dplyr的分组功能无缝集成,anomalize可以轻松处理多个时间序列。
-
灵活的方法选择: 提供了多种时间序列分解和异常检测方法,用户可以根据需求选择最适合的算法。
-
可视化支持: 内置多种可视化函数,帮助用户直观地理解异常检测结果。
-
基于时间的操作: 充分利用了tibbletime包的功能,使得基于时间的操作更加便捷。
anomalize的工作原理
anomalize的异常检测过程主要包含三个步骤:
-
时间序列分解: 使用
time_decompose()函数将时间序列分解为趋势、季节性和残差成分。 -
异常检测: 通过
anomalize()函数对残差成分进行异常检测。 -
重组时间序列: 使用
time_recompose()函数将检测到的异常重新映射到原始时间序列上。
让我们通过一个简单的例子来展示anomalize的使用:
library(tidyverse)
library(anomalize)
# 使用内置的数据集
data("tidyverse_cran_downloads")
# 进行异常检测
tidyverse_cran_downloads %>%
time_decompose(count) %>%
anomalize(remainder) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE, ncol = 3, alpha_dots = 0.5)
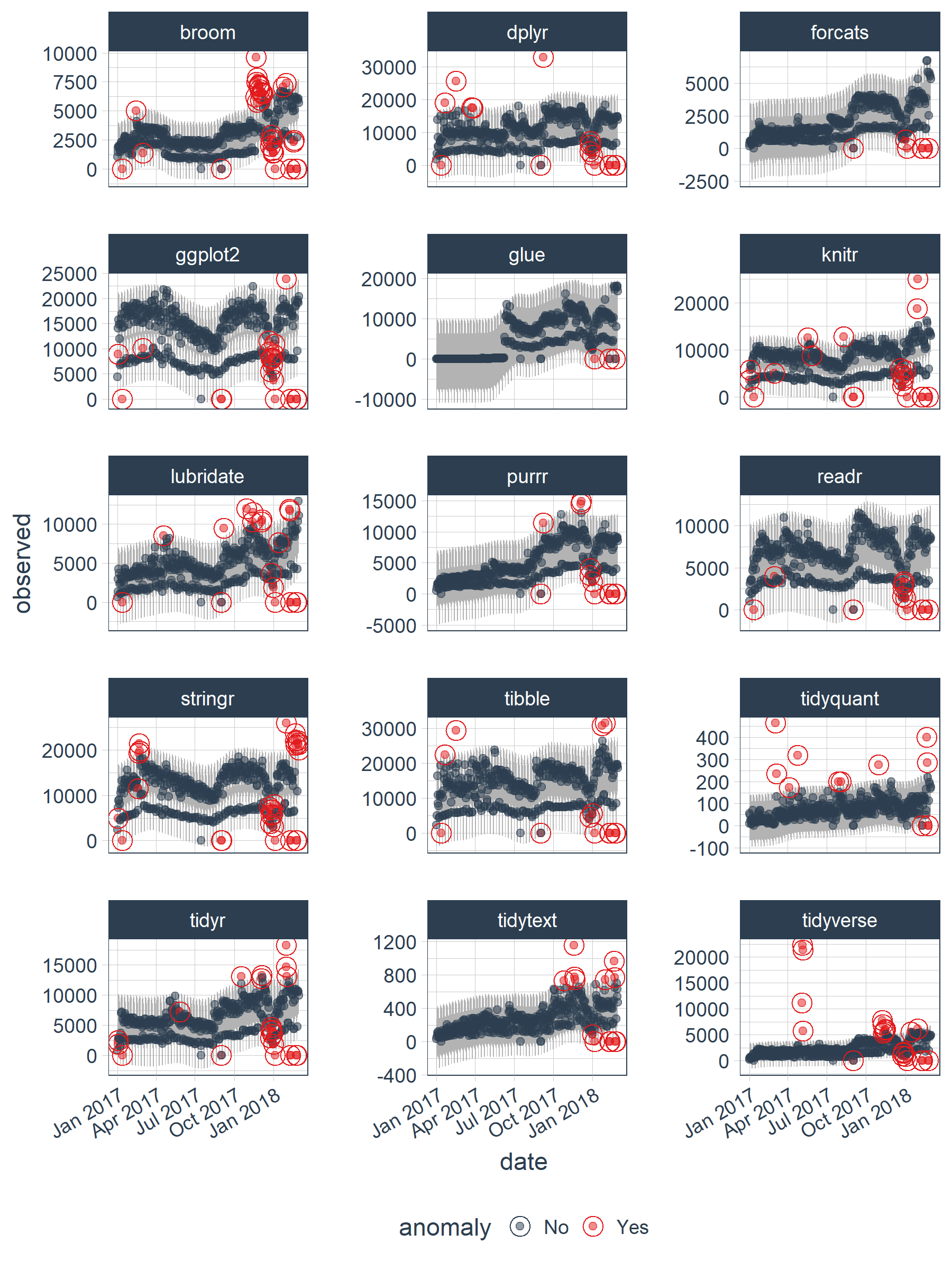
这个例子展示了anomalize如何轻松地对多个tidyverse包的下载量进行异常检测,并生成可视化结果。
anomalize的核心函数
-
time_decompose():
- 用于时间序列分解
- 支持"stl"和"twitter"两种方法
- 自动选择合适的频率和趋势参数
-
anomalize():
- 进行异常检测
- 提供"iqr"(基于四分位距)和"gesd"(广义极端学生化偏差)两种方法
- 可以通过参数调整检测的敏感度
-
time_recompose():
- 将检测到的异常重新映射到原始时间序列
- 生成异常的上下界
-
plot_anomalies():
- 可视化异常检测结果
- 支持单个或多个时间序列的可视化
anomalize的优势
-
易于使用: anomalize的API设计简洁明了,即使是R语言初学者也能快速上手。
-
性能优异: 得益于其高效的实现,anomalize能够快速处理大规模数据集。
-
与tidyverse生态系统集成: 完美融入tidyverse工作流程,使数据处理更加流畅。
-
适应性强: 通过参数调整,可以适应不同类型的时间序列数据。
-
可视化能力: 内置的可视化函数帮助用户更好地理解和解释结果。
实际应用场景
anomalize在多个领域都有广泛的应用,例如:
- 金融: 检测股票价格或交易量的异常波动
- 网络安全: 识别网络流量中的异常模式
- 物联网: 监测传感器数据中的异常值
- 营销: 分析营销活动效果中的异常表现
- 运营: 检测系统性能指标的异常变化
安装和使用
要开始使用anomalize,只需通过CRAN安装即可:
install.packages("anomalize")
然后,您就可以在R中加载并使用anomalize了:
library(anomalize)
结语
anomalize为R用户提供了一个强大而易用的异常检测工具。无论您是数据科学家、分析师还是研究人员,anomalize都能帮助您更轻松地从时间序列数据中发现有价值的异常模式。随着数据驱动决策的重要性不断增加,像anomalize这样的工具将在未来扮演越来越重要的角色。
如果您正在寻找一个可靠、高效且易于集成的异常检测解决方案,不妨给anomalize一个尝试。它可能会成为您数据分析工具箱中不可或缺的一员。
Happy anomaly detecting! 🕵️♂️📊









