
 访问官网
访问官网 Github
Github 文档
文档Anomalize 正被 Timetk 取代:
anomalize 

![]()
![]()
anomalize 包的功能已被 timetk 取代。
我们建议您开始使用 timetk::anomalize() 以获得增强功能和未来的改进。在此了解更多关于使用 timetk 进行异常检测的信息。
原始 anomalize 包的功能将继续维护,以支持使用旧功能的现有代码库。
为防止新的 timetk 功能与旧的 anomalize 代码冲突,请使用以下代码行:
library(anomalize)
anomalize <- anomalize::anomalize
plot_anomalies <- anomalize::plot_anomalies
整洁的异常检测
anomalize 为数据异常检测提供了一个整洁的工作流程。主要函数包括 time_decompose()、anomalize() 和 time_recompose()。结合使用这些函数,可以轻松地分解时间序列、检测异常并创建将"正常"数据与异常数据分开的区间。
2分钟了解 Anomalize (YouTube)
查看我们在 YouTube 上的完整软件介绍系列!
安装
您可以使用 devtools 安装开发版本,或使用 install.packages() 安装最新的 CRAN 版本:
# devtools::install_github("business-science/anomalize")
install.packages("anomalize")
工作原理
anomalize 有三个主要函数:
time_decompose():将时间序列分解为季节性、趋势和余项组件anomalize():对余项组件应用异常检测方法time_recompose():计算将"正常"数据与异常数据分开的限制范围
入门
加载 anomalize 包。通常,您还会同时加载 tidyverse:
library(anomalize)
library(tidyverse)
# 注意:timetk 现在内置了异常检测功能,
# 这将获得未来的新功能。
# 使用此脚本以防止覆盖旧版 anomalize:
anomalize <- anomalize::anomalize
plot_anomalies <- anomalize::plot_anomalies
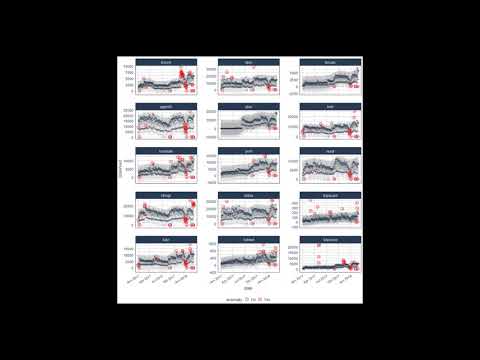
接下来,让我们获取一些数据。anomalize 附带了一个名为 tidyverse_cran_downloads 的数据集,其中包含 15 个"整洁"包从 2017-01-01 到 2018-03-01 的每日 CRAN 下载次数。
假设我们想确定哪些每日下载"次数"是异常的。只需使用三个主要函数(time_decompose()、anomalize() 和 time_recompose())以及可视化函数 plot_anomalies() 即可轻松完成。
tidyverse_cran_downloads %>%
# 数据操作 / 异常检测
time_decompose(count, method = "stl") %>%
anomalize(remainder, method = "iqr") %>%
time_recompose() %>%
# 异常可视化
plot_anomalies(time_recomposed = TRUE, ncol = 3, alpha_dots = 0.25) +
ggplot2::labs(title = "Tidyverse 异常", subtitle = "STL + IQR 方法")
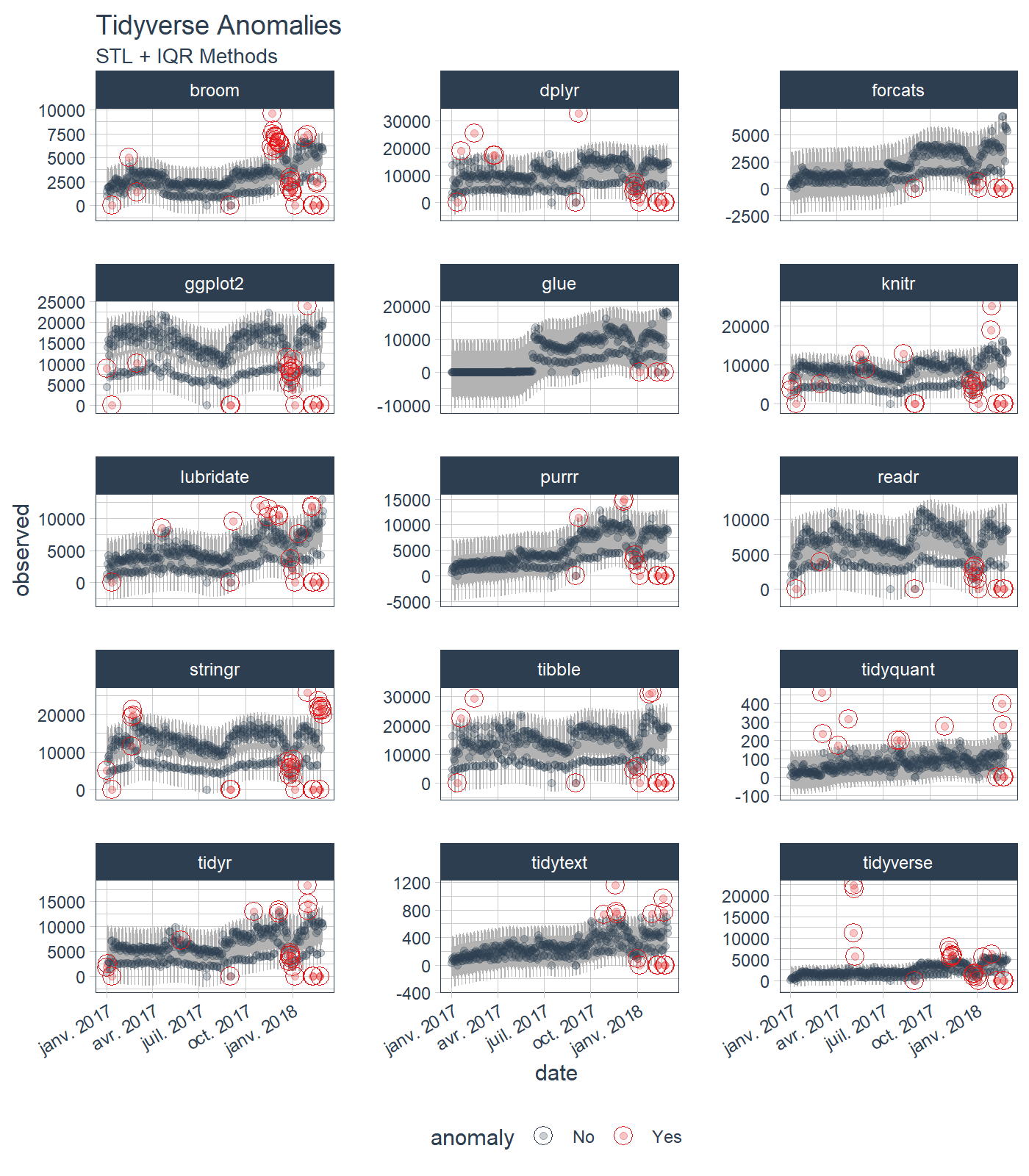
查看 anomalize 快速入门指南。
将预测误差降低 32%
是的!Anomalize 有一个新函数 clean_anomalies(),可用于在预测之前修复时间序列。我们有一个全新的指南 - 使用清理后的异常数据降低预测误差(32%)。
tidyverse_cran_downloads %>%
dplyr::filter(package == "lubridate") %>%
dplyr::ungroup() %>%
time_decompose(count) %>%
anomalize(remainder) %>%
# 新函数,用于清理和修复异常!
clean_anomalies() %>%
dplyr::select(date, anomaly, observed, observed_cleaned) %>%
dplyr::filter(anomaly == "Yes")
#> # 时间 tibble: 19 × 4
#> # 索引: 日期
#> 日期 异常 观测值 清理后的观测值
#> <date> <chr> <dbl> <dbl>
#> 1 2017-01-12 是 -1.14e-13 3522.
#> 2 2017-04-19 是 8.55e+ 3 5202.
#> 3 2017-09-01 是 3.98e-13 4137.
#> 4 2017-09-07 是 9.49e+ 3 4871.
#> 5 2017-10-30 是 1.20e+ 4 6413.
#> 6 2017-11-13 是 1.03e+ 4 6641.
#> 7 2017-11-14 是 1.15e+ 4 7250.
#> 8 2017-12-04 是 1.03e+ 4 6519.
#> 9 2017-12-05 是 1.06e+ 4 7099.
#> 10 2017-12-27 是 3.69e+ 3 7073.
#> 11 2018-01-01 是 1.87e+ 3 6418.
#> 12 2018-01-05 是 -5.68e-14 6293.
#> 13 2018-01-13 是 7.64e+ 3 4141.
#> 14 2018-02-07 是 1.19e+ 4 8539.
#> 15 2018-02-08 是 1.17e+ 4 8237.
#> 16 2018-02-09 是 -5.68e-14 7780.
#> 17 2018-02-10 是 0 5478.
#> 18 2018-02-23 是 -5.68e-14 8519.
#> 19 2018-02-24 是 0 6218.
不仅如此!
还有几个额外的功能:
plot_anomaly_decomposition()用于可视化算法如何在"余项"中检测异常的内部工作原理。
tidyverse_cran_downloads %>%
dplyr::filter(package == "lubridate") %>%
dplyr::ungroup() %>%
time_decompose(count) %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
ggplot2::labs(title = "Lubridate下载量异常分解")
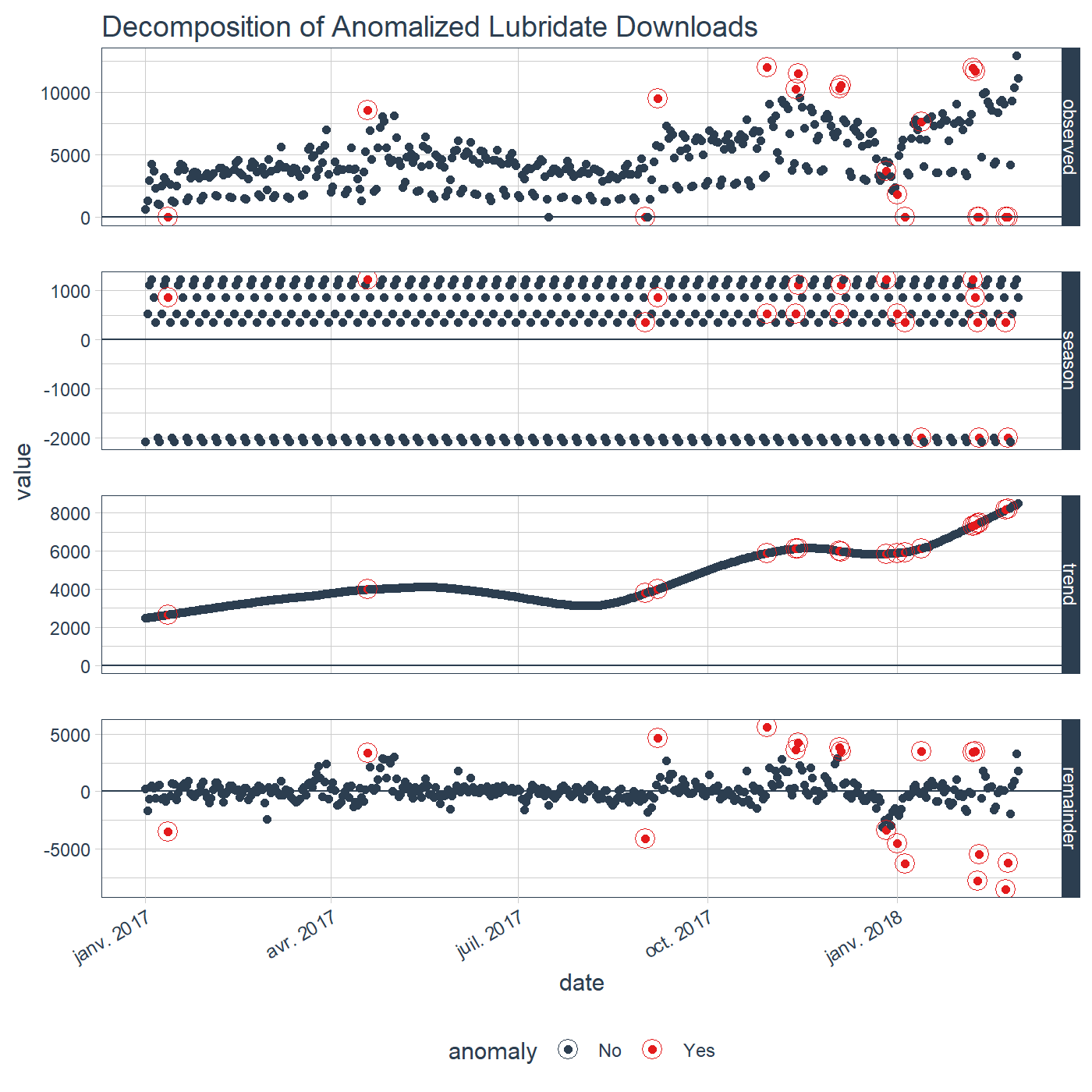
有关anomalize方法和内部工作原理的更多信息,请参阅"Anomalize方法"文档。
参考文献
在开发anomalize使用的异常检测方法时,以下几个包发挥了重要作用:
- Twitter的
AnomalyDetection,它使用中位数跨度实现分解,并使用广义极值学生化偏差(GESD)检验来检测异常。 forecast::tsoutliers()函数,它实现了IQR方法。
对学习异常检测感兴趣吗?
Business Science提供两个1小时的异常检测课程:











