
深度强化学习在CARLA自动驾驶中的应用
人工智能技术正在各个领域蓬勃发展,自动驾驶汽车研究就是其中一个重要方向。本文将介绍一个基于深度强化学习的自动驾驶项目,该项目利用最新的算法在CARLA仿真环境中训练自动驾驶智能体。
项目背景与目标
自动驾驶技术的发展面临着巨大的挑战,其中一个关键问题是如何让车辆在复杂多变的真实环境中做出正确的决策。深度强化学习(DRL)作为一种强大的学习框架,在解决复杂决策问题上展现出了巨大的潜力。本项目旨在探索DRL在自动驾驶领域的应用,主要目标包括:
- 开发一个端到端的自动驾驶解决方案,使车辆能够自主导航并避免碰撞。
- 研究DRL模型如何在连续状态和动作空间中训练智能体。
- 实现一个基于近端策略优化(PPO)算法的智能体,使其能够在CARLA环境中可靠驾驶。
- 引入变分自编码器(VAE)来压缩高维观察数据,加速智能体的学习过程。
技术方案
本项目采用了以下核心技术:
- CARLA仿真环境:提供逼真的城市驾驶场景。
- 变分自编码器(VAE):将高维图像压缩为低维潜在表示。
- 近端策略优化(PPO):用于训练自动驾驶智能体的强化学习算法。
项目的整体架构如下:
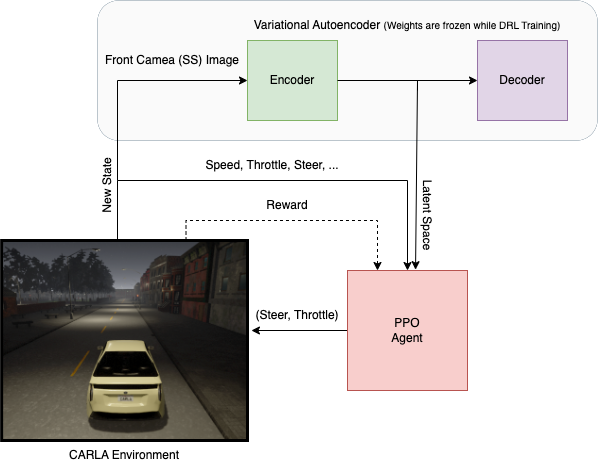
CARLA仿真环境
CARLA是一个开源的自动驾驶仿真器,提供了高度逼真的城市驾驶环境。本项目主要使用了Town 2和Town 7两个场景进行训练和测试。CARLA环境的优势在于:
- 提供丰富多样的驾驶场景
- 支持多种传感器模拟,如摄像头、激光雷达等
- 可定制的天气和光照条件
- 支持多车辆和行人交互
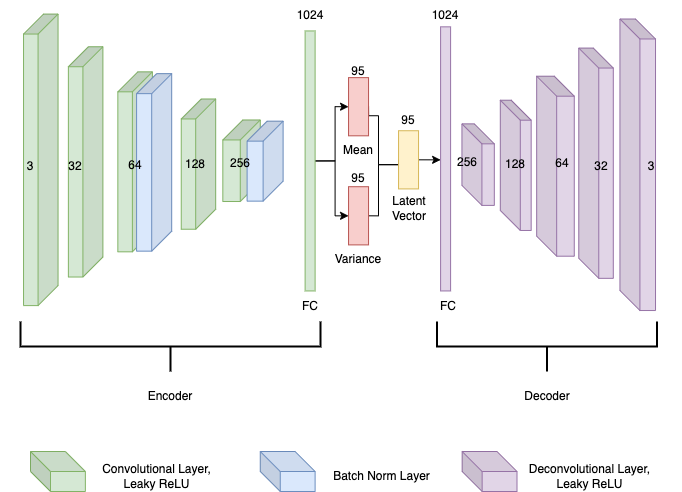
变分自编码器(VAE)
VAE在本项目中起到了降维的作用。具体步骤如下:
- 收集12,000张160x80像素的语义分割图像作为训练数据。
- 将这些图像作为VAE的输入(38400个输入单元)。
- VAE将高维图像压缩为低维潜在表示。
- 在DRL网络训练过程中,VAE的权重保持固定。
VAE的结构如下图所示:
近端策略优化(PPO)
PPO是一种on-policy的强化学习算法,在连续控制任务中表现出色。本项目使用PPO来训练自动驾驶智能体,其优势包括:
- 样本效率高
- 训练稳定性好
- 易于实现和调参
PPO与VAE结合的训练流程如下图所示:
.png)
实验结果
本项目在Town 7和Town 2两个场景中进行了训练和测试。以下是部分训练过程的可视化结果:
Town 7场景:

Town 2场景:
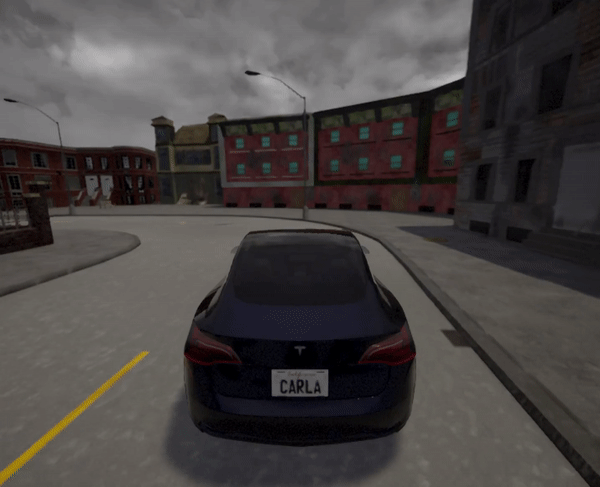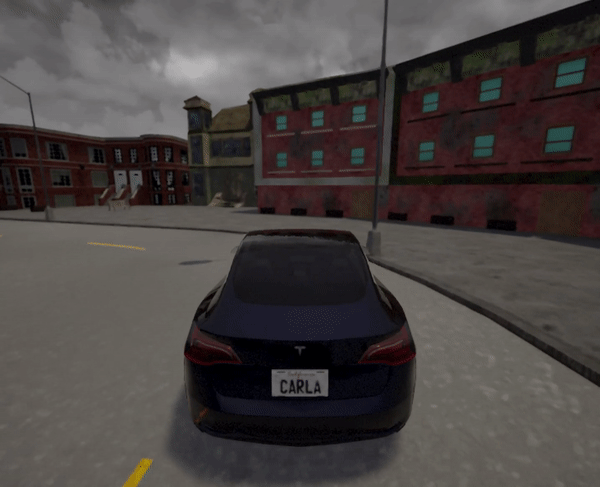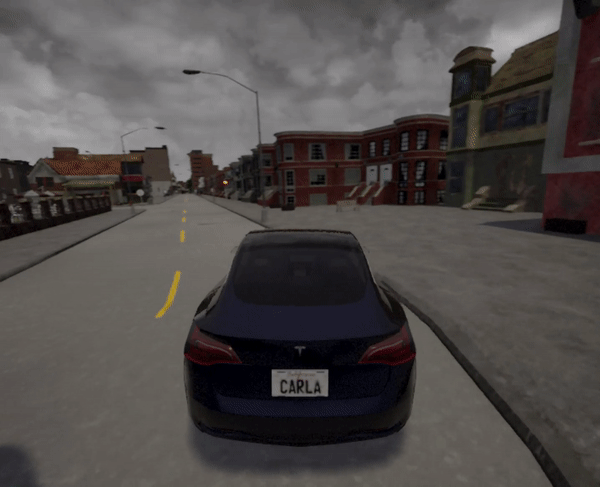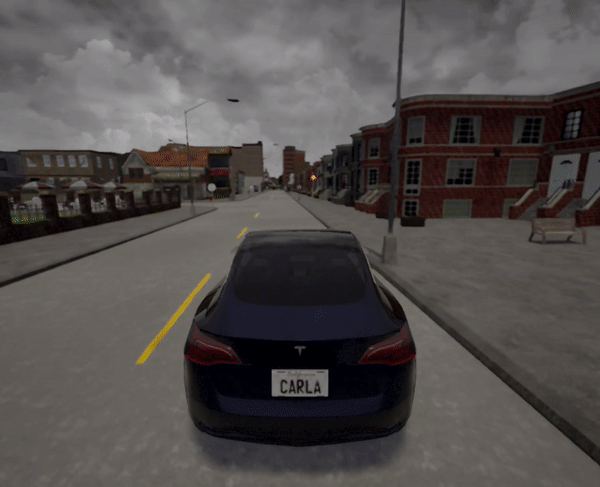
实验结果表明,经过训练的智能体能够在复杂的城市环境中实现自主导航和避障。
项目使用指南
-
环境准备:
- 安装CARLA (0.9.8版本)和额外地图
- 推荐使用Windows或Linux操作系统
- Python 3.7+版本
-
项目设置:
git clone <项目仓库> python -m venv venv source venv/Script/activate pip install -r requirements.txt cd poetry/ && poetry update -
运行预训练模型:
python continuous_driver.py --exp-name ppo --train False -
训练新模型:
python continuous_driver.py --exp-name ppo -
查看训练进度:
tensorboard --logdir runs/
结论与展望
本项目成功实现了基于深度强化学习的自动驾驶系统,在CARLA仿真环境中展现出了良好的性能。通过结合VAE和PPO算法,我们解决了高维状态空间的处理问题,并实现了端到端的自动驾驶控制。
未来的研究方向可以包括:
- 引入更多传感器数据,如激光雷达点云
- 探索其他先进的强化学习算法
- 增加更多复杂的驾驶场景和任务
- 研究如何将仿真中训练的模型迁移到真实世界
本项目为深度强化学习在自动驾驶领域的应用提供了一个有价值的参考,也为未来的研究提供了良好的基础。我们期待这项技术能够推动自动驾驶汽车的发展,最终为人类的交通出行带来更多便利和安全。














