
docs-scraper: 为您的文档网站打造卓越的搜索体验
在当今信息爆炸的时代,拥有一个功能强大、用户友好的文档搜索系统对于任何软件项目或技术文档网站来说都至关重要。Meilisearch 团队深谙此道,因此推出了 docs-scraper 这款专门用于文档抓取和索引的开源工具。本文将详细介绍 docs-scraper 的特性、使用方法以及它如何帮助开发者为用户提供卓越的文档搜索体验。
docs-scraper 简介
docs-scraper 是一款专为文档网站设计的抓取工具,可以将抓取到的内容索引到 Meilisearch 搜索引擎中。Meilisearch 是一个开源的搜索引擎,以其快速、准确和易用性而闻名。通过将 docs-scraper 与 Meilisearch 结合使用,开发者可以为他们的文档网站添加强大的搜索功能,大大提升用户的使用体验。
主要特性
-
专为文档设计: docs-scraper 针对各种文档网站的结构进行了优化,能够准确地抓取和索引文档内容。
-
灵活的配置: 通过简单的配置文件,用户可以自定义抓取规则,包括起始 URL、停止 URL、选择器等。
-
与 Meilisearch 无缝集成: 抓取的内容可以直接索引到 Meilisearch 实例中,无需额外的处理步骤。
-
支持多种文档格式: 无论是静态 HTML 页面还是动态生成的内容,docs-scraper 都能够有效处理。
-
自动化支持: 可以轻松集成到 CI/CD 流程中,实现文档更新后的自动抓取和索引。
使用 docs-scraper 的步骤
要开始使用 docs-scraper,您需要遵循以下几个简单的步骤:
- 运行 Meilisearch 实例
首先,您需要有一个运行中的 Meilisearch 实例。可以使用以下命令快速启动:
curl -L https://install.meilisearch.com | sh
./meilisearch --master-key=your_master_key
- 设置配置文件
创建一个 JSON 格式的配置文件,指定抓取规则和索引设置。例如:
{
"index_uid": "docs",
"start_urls": ["https://www.example.com/doc/"],
"sitemap_urls": ["https://www.example.com/sitemap.xml"],
"stop_urls": [],
"selectors": {
"lvl0": {
"selector": ".docs-lvl0",
"global": true,
"default_value": "Documentation"
},
"lvl1": ".docs-lvl1",
"lvl2": ".docs-content .docs-lvl2",
"lvl3": ".docs-content .docs-lvl3",
"text": ".docs-content p, .docs-content li"
}
}
- 运行 docs-scraper
使用 Docker 或从源代码运行 docs-scraper:
docker run -t --rm \
-e MEILISEARCH_HOST_URL=<your-meilisearch-host-url> \
-e MEILISEARCH_API_KEY=<your-meilisearch-api-key> \
-v <path-to-your-config-file>:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
高级配置选项
docs-scraper 提供了许多高级配置选项,使您能够更精细地控制抓取过程:
-
自定义选择器: 可以为不同级别的标题和内容定义特定的 CSS 选择器。
-
全局选择器: 对于在整个页面中保持一致的元素(如导航栏中的标题),可以使用全局选择器。
-
排除选择器: 可以指定不需要抓取的页面元素。
-
自定义设置: 支持为 Meilisearch 索引添加自定义设置,如同义词、停用词等。
-
JavaScript 渲染: 对于需要 JavaScript 渲染的页面,docs-scraper 提供了相应的支持。
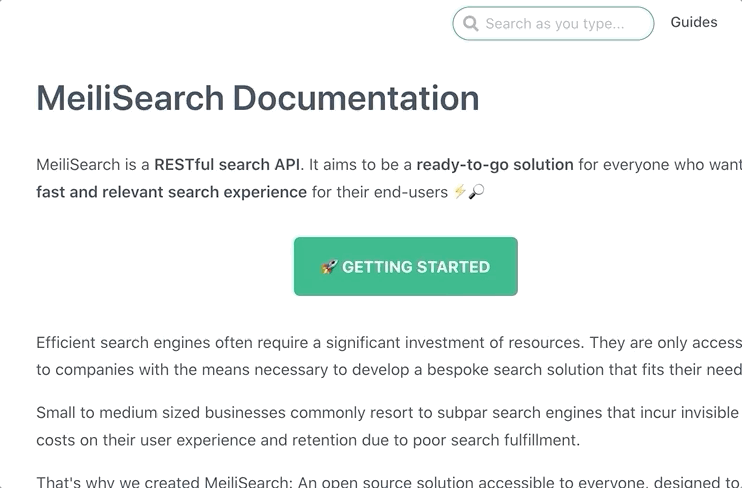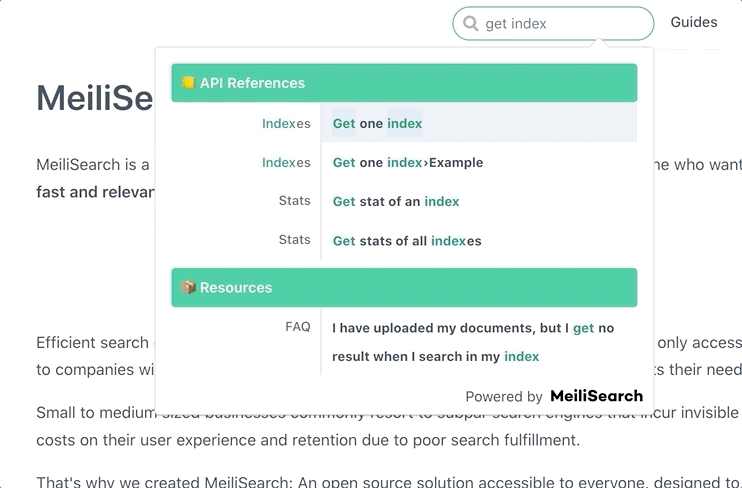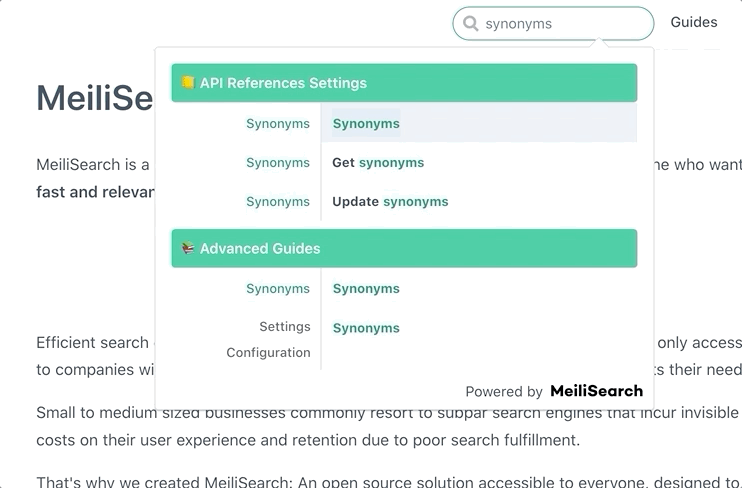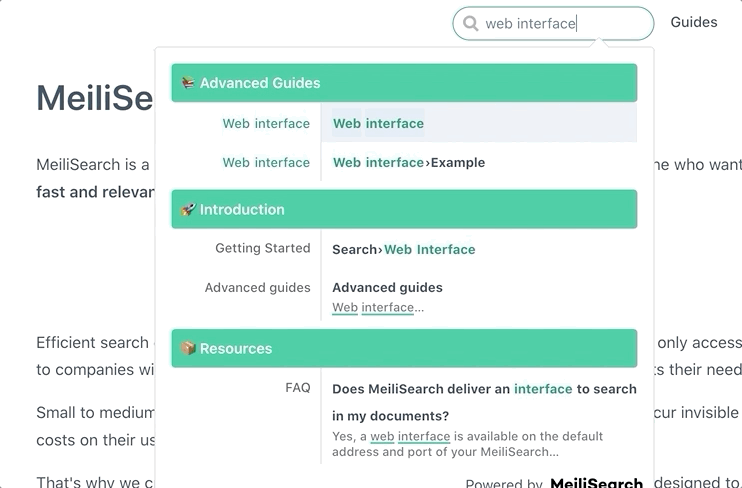
与前端搜索栏集成
抓取并索引文档后,下一步就是在网站上实现搜索功能。Meilisearch 提供了多种前端集成方案:
- 对于 VuePress 网站,可以使用 vuepress-plugin-meilisearch。
- 对于其他类型的文档网站,可以使用 docs-searchbar.js 库。
这些工具可以帮助您快速在文档网站上实现美观、功能强大的搜索栏。
持续集成与部署
docs-scraper 可以轻松集成到 CI/CD 流程中。例如,您可以在 GitHub Actions 中设置一个工作流,在文档更新后自动运行 docs-scraper:
run-scraper:
needs: <your-deployment-job>
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Run scraper
env:
HOST_URL: ${{ secrets.MEILISEARCH_HOST_URL }}
API_KEY: ${{ secrets.MEILISEARCH_API_KEY }}
CONFIG_FILE_PATH: <path-to-your-config-file>
run: |
docker run -t --rm \
-e MEILISEARCH_HOST_URL=$HOST_URL \
-e MEILISEARCH_API_KEY=$API_KEY \
-v $CONFIG_FILE_PATH:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
安全性考虑
在使用 docs-scraper 时,请注意以下安全事项:
- 使用具有适当权限的 API 密钥,避免使用主密钥。
- 在生产环境中,使用特定的版本标签而不是
latest标签。 - 确保 Meilisearch 实例受到适当的保护,特别是在公开访问时。
结语
docs-scraper 为文档网站提供了一个强大而灵活的搜索解决方案。通过简单的配置和部署,它能够显著提升文档的可搜索性和用户体验。无论您是维护一个开源项目的文档,还是管理企业级的技术文档,docs-scraper 都能满足您的需求,帮助用户更快、更准确地找到所需信息。
随着开源社区的不断贡献和 Meilisearch 团队的持续改进,我们可以期待 docs-scraper 在未来会变得更加强大和易用。如果您正在寻找一个可靠的文档搜索解决方案,docs-scraper 无疑是一个值得考虑的选择。
立即尝试 docs-scraper,为您的文档网站带来卓越的搜索体验吧!🚀
相关链接
通过使用 docs-scraper,您可以轻松地为您的文档网站添加专业级的搜索功能,提升用户体验,让您的文档内容更易于访问和理解。无论是开发者、技术作者还是文档管理员,都能从这个强大的工具中受益。开始您的 docs-scraper 之旅,让文档搜索变得简单而高效吧!













