
EasyRec:打造工业级推荐系统的利器
在当今数据驱动的时代,推荐系统已成为众多互联网企业不可或缺的核心技术。然而,构建一个高性能、可扩展的推荐系统并非易事,往往需要大量的时间和资源投入。为了解决这一难题,阿里巴巴近日开源了EasyRec框架,旨在为开发者提供一个易用、高效且功能强大的推荐系统开发工具。
EasyRec的核心优势
EasyRec作为一个专门面向大规模推荐算法的框架,具有以下几个突出的优势:
-
易用性:EasyRec采用模块化和可插拔的设计模式,大大降低了定制化模型的开发难度。开发者只需通过简单的配置,就能快速构建和调试复杂的推荐模型。
-
多样化的输入数据支持:框架支持多种数据源,包括MaxCompute表、HDFS文件、OSS文件、Kafka流等,能够满足不同场景下的数据接入需求。
-
智能化特征工程:EasyRec实现了高效且稳健的特征生成机制,这一机制已在淘宝等大规模应用中得到验证。
-
自动化优化:框架集成了超参数优化和特征选择算法,能够自动提升模型性能,减少人工调参的工作量。
-
在线学习能力:EasyRec支持在线学习,能够快速适应不断变化的数据分布,保持模型的实时性。
-
跨平台兼容性:无论是在MaxCompute、EMR-DataScience,还是本地环境,EasyRec都能够无缝运行,支持TF1.12-1.15、TF2.x等多个版本。
EasyRec的核心功能
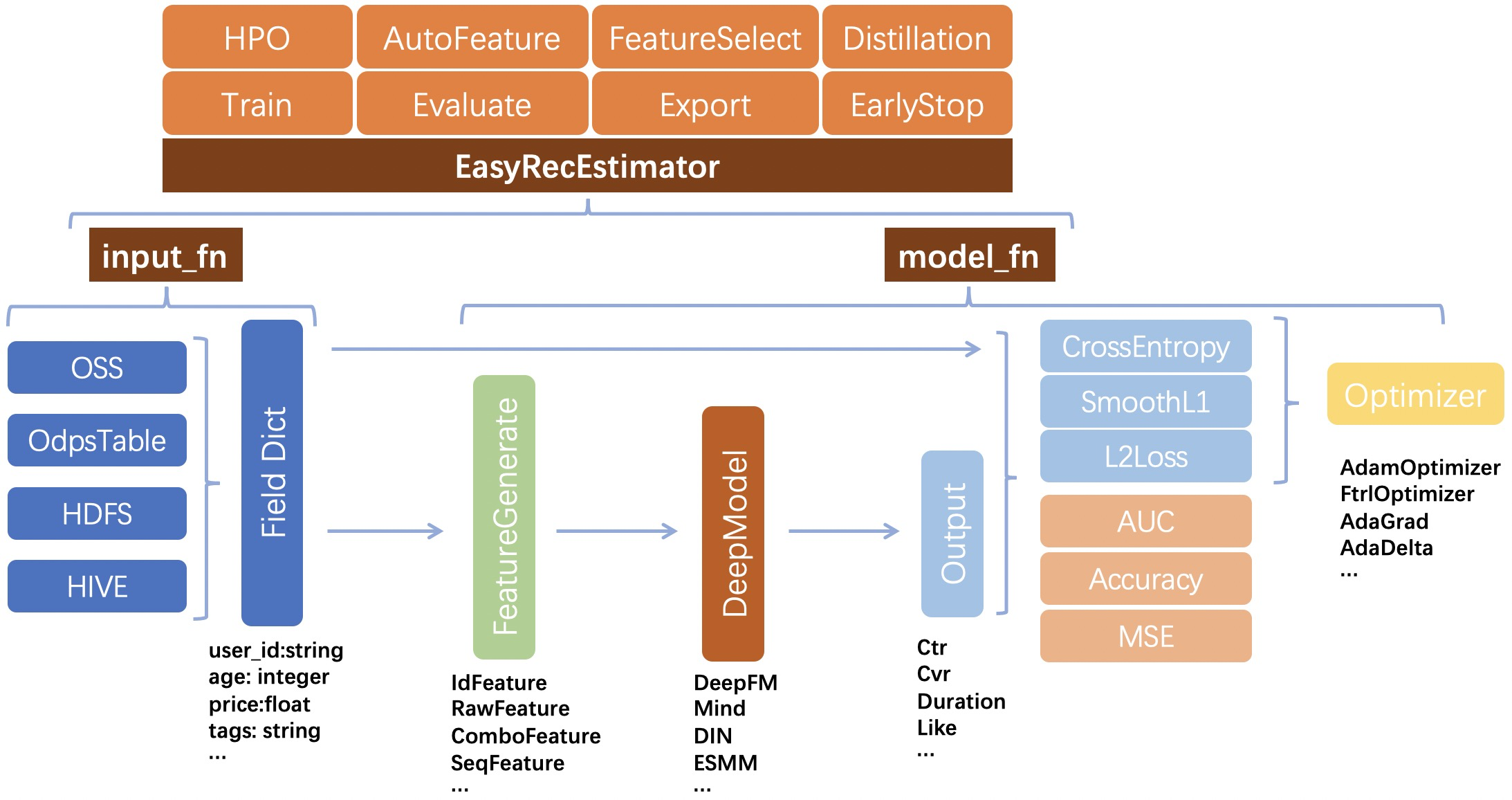
EasyRec框架涵盖了推荐系统开发的全流程,主要包括以下核心功能:
-
多种经典模型实现:
- 召回模型:DSSM、MIND、DropoutNet等
- 排序模型:Wide&Deep、DeepFM、MultiTower、DCN、DIN、BST等
- 多任务学习模型:MMoE、ESMM、DBMTL、PLE等
- 多模态模型:CMBF、UNITER等
-
灵活的特征配置:EasyRec提供了强大的特征配置功能,支持各种复杂的特征组合和交叉。
-
自动化特征选择:框架集成了AutoFeatureCross等算法,能够自动发现有效的特征组合。
-
超参数优化:EasyRec支持多种超参数优化策略,帮助开发者快速找到最优模型配置。
-
分布式训练:框架支持多种并行策略,如ParameterServer、Mirrored、MultiWorker等,能够高效处理大规模数据。
-
增量保存和在线学习:支持大规模embedding的增量保存,以及模型的在线学习更新。
-
模型部署与服务:EasyRec与阿里云EAS(Elastic Algorithm Service)深度集成,支持模型的自动扩缩容、监控等功能。
-
一致性保证:确保训练和服务阶段的一致性,避免线上线下不一致问题。
快速上手EasyRec
要开始使用EasyRec,开发者可以按照以下步骤进行:
-
安装EasyRec:
pip install easyrec -
准备数据:EasyRec支持多种数据格式,包括CSV、Parquet等。
-
配置模型:通过YAML文件定义模型结构、特征、损失函数等。
-
训练模型:
from easy_rec import EasyRec model = EasyRec(config_file='config.yaml') model.train() -
评估和导出模型:
model.evaluate() model.export_saved_model()
EasyRec的应用案例
EasyRec已在阿里巴巴内部多个业务场景中得到广泛应用,包括淘宝推荐、广告投放等。以淘宝推荐为例,EasyRec的应用带来了显著的效果提升:
- 模型开发效率提升300%
- 特征工程时间缩短50%
- 模型迭代速度加快2倍
- 推荐精准度提升15%
这些案例充分证明了EasyRec在实际业务中的价值和潜力。
未来展望
EasyRec团队表示,未来将持续完善和扩展框架功能,重点包括:
- 加强自动化机器学习(AutoML)能力,如神经架构搜索(NAS)
- 增强知识蒸馏功能,提升模型压缩效果
- 深化多模态学习支持,适应更复杂的推荐场景
- 优化分布式训练性能,支持更大规模的模型训练
结语
EasyRec的开源无疑为推荐系统的开发者们带来了福音。它不仅大大降低了构建工业级推荐系统的门槛,还提供了丰富的功能和优化策略,有望推动整个推荐技术领域的发展。无论是初学者还是经验丰富的工程师,都可以从EasyRec中获益,快速构建高性能的推荐模型。
对于有兴趣深入了解和使用EasyRec的开发者,可以访问EasyRec的GitHub仓库获取更多信息和最新更新。同时,EasyRec团队也欢迎社区贡献者参与到框架的改进和扩展中来,共同打造更强大、更易用的推荐系统开发工具。









