
ER-NeRF:高效率区域感知神经辐射场用于高保真说话人像合成
在计算机视觉和图形学领域,生成逼真的说话人像一直是一个充满挑战性的任务。近年来,神经辐射场(NeRF)技术在3D场景重建和新视角合成方面取得了巨大进展。然而,将NeRF应用于动态说话人像合成仍然面临着收敛速度慢、渲染效率低下等问题。为了解决这些挑战,来自北京航空航天大学和其他机构的研究人员提出了一种名为ER-NeRF的新方法,这是一种高效的区域感知神经辐射场架构,用于高保真说话人像合成。
ER-NeRF的核心思想
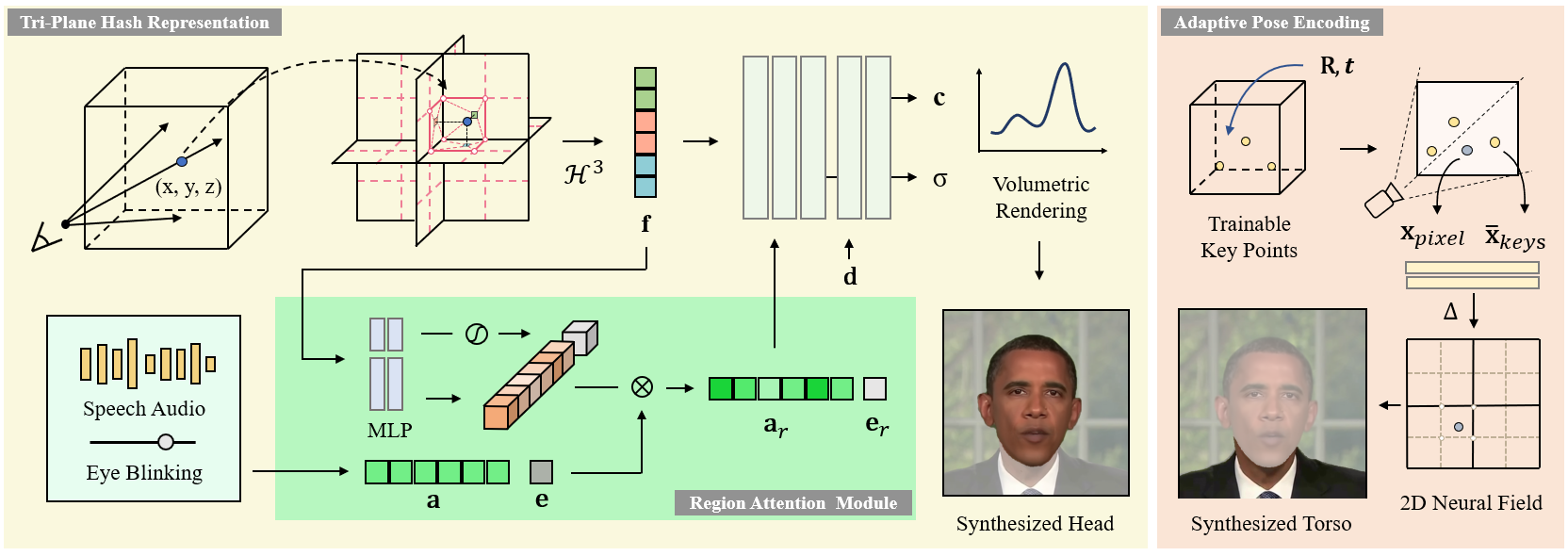
ER-NeRF的核心思想是明确利用空间区域对说话人像建模的不平等贡献。与现有方法不同,ER-NeRF采用了创新的区域感知设计,能够更有效地建模动态头部和口型变化。具体来说,ER-NeRF引入了以下几个关键组件:
-
紧凑而富有表现力的NeRF三平面哈希表示:通过修剪空白空间区域,使用三个平面哈希编码器来提高动态头部重建的准确性。
-
区域注意力模块:为语音音频生成区域感知条件特征。与现有方法使用MLP隐式学习跨模态关系不同,注意力机制在音频特征和空间区域之间建立了显式连接,以捕获局部运动先验。
-
自适应姿态编码:通过将复杂的头部姿态变换映射到空间坐标来优化头部-躯干分离问题。
ER-NeRF的优势
与现有方法相比,ER-NeRF具有以下几个显著优势:
-
快速收敛:得益于其高效的区域感知设计,ER-NeRF能够更快地收敛到高质量结果。
-
实时渲染:通过优化的表示和计算,ER-NeRF能够实现实时的渲染速度。
-
高保真度:ER-NeRF生成的说话人像具有更高的视觉质量和音唇同步性。
-
小模型大小:相比于其他NeRF方法,ER-NeRF的模型参数更少,更易于部署。
技术细节
三平面哈希表示
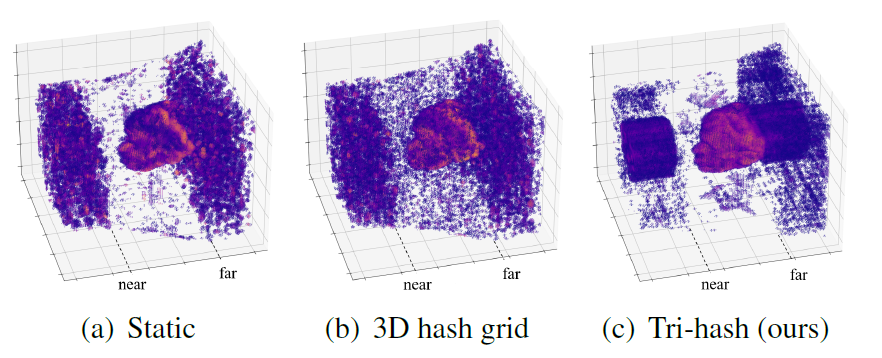
ER-NeRF采用了一种紧凑而富有表现力的NeRF三平面哈希表示。这种表示方法通过修剪空白空间区域,使用三个平面哈希编码器来提高动态头部重建的准确性。与传统的3D哈希网格相比,这种方法能够更好地处理音频特征并学习动态运动,同时保持精细的表面重建能力。
区域注意力模块
ER-NeRF引入了一个创新的区域注意力模块,用于生成区域感知的条件特征。这个模块通过注意力机制建立了音频特征和空间区域之间的显式连接,从而能够更好地捕获局部运动先验。即使在一些不确定的细节(如蓬松的头发)的影响下,区域注意力模块仍然能够成功捕捉动态条件和空间区域之间的关系,而无需显式注释。

自适应姿态编码
为了解决头部-躯干分离问题,ER-NeRF引入了一种直接而快速的自适应姿态编码方法。这种方法通过将复杂的头部姿态变换映射到空间坐标来优化建模过程,从而实现更准确和高效的头部运动建模。
实验结果
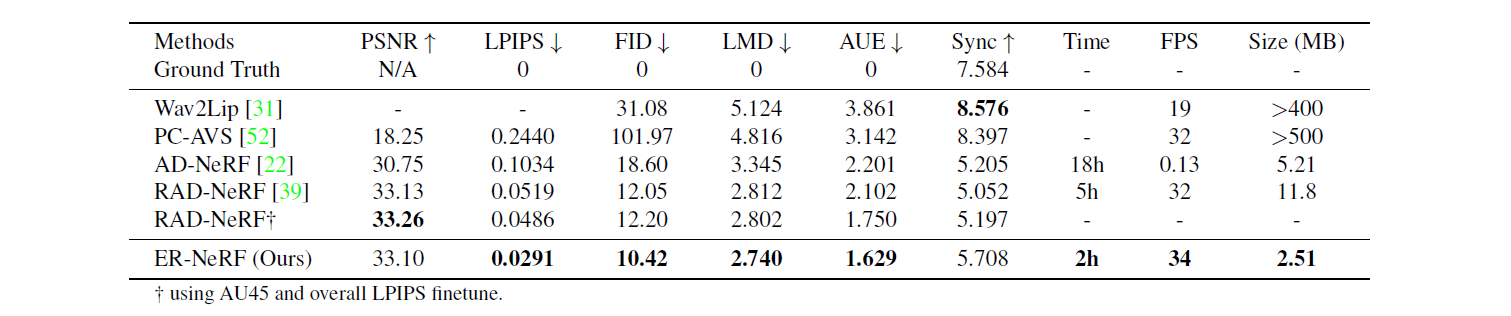
研究人员在多个数据集上进行了广泛的实验,以评估ER-NeRF的性能。结果表明,ER-NeRF在多个方面都优于现有的最先进方法:
-
唇形同步:ER-NeRF生成的说话人像具有更好的音唇同步性,使得口型运动与音频更加匹配。
-
渲染质量:生成的图像具有更高的视觉质量,包括更细致的面部特征和更自然的光照效果。
-
训练和推理速度:ER-NeRF在训练和推理阶段都表现出更快的速度,这对于实际应用至关重要。
-
模型大小:与其他NeRF方法相比,ER-NeRF的模型参数更少,更易于部署和应用。
应用前景
ER-NeRF的出现为高保真说话人像合成开辟了新的可能性。它的潜在应用包括但不限于:
-
虚拟主播和数字人:ER-NeRF可用于创建更加逼真和自然的虚拟主播,提升用户体验。
-
电影和游戏产业:该技术可以应用于电影特效制作和游戏角色动画,降低制作成本并提高质量。
-
远程通信:ER-NeRF有潜力改善视频会议和远程协作体验,使远程交流更加自然和沉浸。
-
教育培训:可用于创建互动式虚拟教师或培训助手,提供更加个性化和吸引人的学习体验。
未来展望
尽管ER-NeRF在说话人像合成领域取得了显著进展,但研究人员认为仍有进一步改进的空间:
-
表情控制:未来的工作可以探索如何更好地控制和生成丰富的面部表情,使合成结果更加生动。
-
实时性能优化:虽然ER-NeRF已经实现了实时渲染,但仍可以进一步优化以适应更多实时应用场景。
-
多人场景:扩展ER-NeRF以支持多人说话场景的建模和渲染是一个有趣的研究方向。
-
跨模态学习:探索如何更好地融合视觉、音频和文本信息,以生成更加智能和自然的说话人像。
结论
ER-NeRF为高保真说话人像合成提供了一种高效且有效的解决方案。通过创新的区域感知设计,它成功地解决了现有NeRF方法在动态人像建模中面临的挑战。ER-NeRF的出现不仅推动了计算机视觉和图形学领域的技术进步,还为众多实际应用场景带来了新的可能性。随着技术的不断发展和完善,我们可以期待在不久的将来看到更多基于ER-NeRF的创新应用,为人机交互和数字内容创作带来革命性的变革。
参考链接
如果您对ER-NeRF感兴趣并希望在自己的项目中使用它,可以参考以下引用格式:
@InProceedings{li2023ernerf,
author = {Li, Jiahe and Zhang, Jiawei and Bai, Xiao and Zhou, Jun and Gu, Lin},
title = {Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {7568-7578}
}
ER-NeRF的出现标志着说话人像合成技术的一个重要里程碑。它不仅推动了学术研究的进展,也为实际应用提供了新的可能性。随着技术的不断完善和应用场景的拓展,我们可以期待看到更多基于ER-NeRF的创新应用,为数字内容创作和人机交互带来更多令人兴奋的突破。









