
 访问官网
访问官网 Github
Github 论文
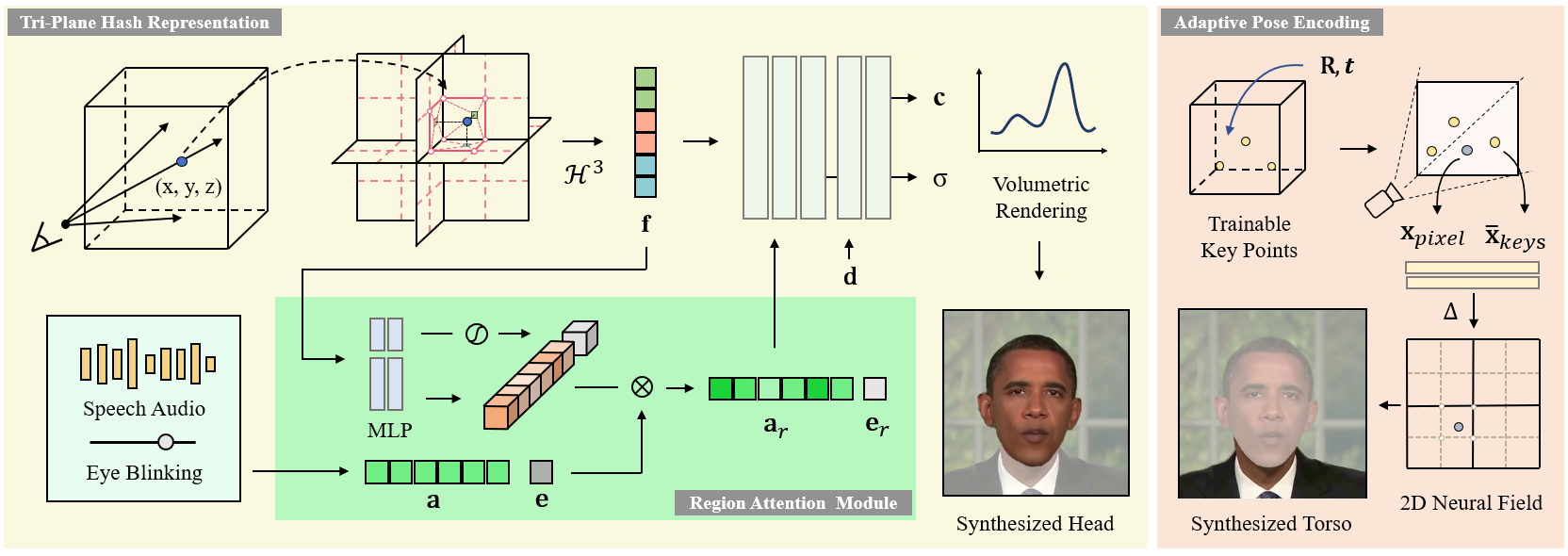
论文高保真说话人像合成的高效区域感知神经辐射场
这是我们ICCV 2023论文《高保真说话人像合成的高效区域感知神经辐射场》的官方代码库。
论文 | 项目主页 | ArXiv | 视频演示
更新
- [2024/07/02] 我们的新作品 TalkingGaussian 已发布!
- 待办:使用AU实现SyncTalk的完整表情控制,就像我们在TalkingGaussian中所做的那样。
安装
在Ubuntu 18.04、Pytorch 1.12和CUDA 11.3上测试通过。
安装依赖
conda create -n ernerf python=3.10
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
准备工作
-
准备人脸解析模型。
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth -
准备用于头部姿态估计的3DMM模型。
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy -
从Basel Face Model 2009下载3DMM模型:
# 1. 将01_MorphableModel.mat复制到data_util/face_tracking/3DMM/ # 2. cd data_utils/face_tracking python convert_BFM.py
数据集和预训练模型
我们主要从AD-NeRF、DFRF、GeneFace和YouTube获取实验视频。由于版权限制,我们无法分发所有这些视频。您可能需要自行下载和裁剪这些视频。以下是一个来自AD-NeRF的示例训练视频(奥巴马),分辨率为450x450。
mkdir -p data/obama
wget https://github.com/YudongGuo/AD-NeRF/blob/master/dataset/vids/Obama.mp4?raw=true -O data/obama/obama.mp4
我们还提供了在Obama视频片段上的预训练检查点。完成数据预处理步骤后,您可以下载并通过以下方式测试它们:
python main.py data/obama/ --workspace trial_obama/ -O --test --ckpt trial_obama/checkpoints/ngp.pth # 头部
python main.py data/obama/ --workspace trial_obama_torso/ -O --test --torso --ckpt trial_obama_torso/checkpoints/ngp.pth # 头部+躯干
测试结果应该大约为:
| 设置 | PSNR | LPIPS | LMD |
|---|---|---|---|
| 头部 | 35.607 | 0.0178 | 2.525 |
| 头部+躯干 | 26.594 | 0.0446 | 2.550 |
使用方法
预处理自定义训练视频
-
将训练视频放在
data/<ID>/<ID>.mp4下。视频必须是25FPS,所有帧都包含说话的人。 分辨率应该约为512x512,时长约1-5分钟。
-
运行脚本处理视频。(可能需要几个小时)
python data_utils/process.py data/<ID>/<ID>.mp4 -
获取眨眼的AU45
在OpenFace中运行
FeatureExtraction,重命名并将输出的CSV文件移动到data/<ID>/au.csv。
音频预处理
在我们的论文中,我们使用DeepSpeech特征进行评估。
在训练和测试时,您应该通过--asr_model <deepspeech, esperanto, hubert>指定音频特征的类型。
-
DeepSpeech
python data_utils/deepspeech_features/extract_ds_features.py --input data/<name>.wav # 保存到 data/<name>.npy -
Wav2Vec
您也可以尝试像RAD-NeRF那样通过Wav2Vec提取音频特征:
python data_utils/wav2vec.py --wav data/<name>.wav --save_feats # 保存到 data/<name>_eo.npy -
HuBERT
在我们的测试中,HuBERT提取器对更多语言表现更好,这已经在GeneFace中使用。
# 借鉴自GeneFace。英语预训练。 python data_utils/hubert.py --wav data/<name>.wav # 保存到 data/<name>_hu.npy
训练
首次运行时编译CUDA扩展会花费一些时间。
# 训练(头部和lpips微调,按顺序运行)
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
# 训练(躯干)
# <head>.pth 应该是 trial_obama 中最新的检查点
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
测试
# 在测试集上测试
python main.py data/obama/ --workspace trial_obama/ -O --test # 只渲染头部,使用GT图像作为躯干
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test # 同时渲染头部和躯干
使用目标音频进行推理
# 添加 "--smooth_path" 可能有助于减少头部的抖动,但会降低对原始姿势的准确性。
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud <音频>.npy
## 引用
如果您发现本仓库对您的项目有帮助,请考虑按以下方式引用:
@InProceedings{li2023ernerf, author = {Li, Jiahe and Zhang, Jiawei and Bai, Xiao and Zhou, Jun and Gu, Lin}, title = {Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, month = {十月}, year = {2023}, pages = {7568-7578} }
## 致谢
本代码的开发主要依赖于[RAD-NeRF](https://github.com/ashawkey/RAD-NeRF),同时也参考了[DFRF](https://github.com/sstzal/DFRF)、[GeneFace](https://github.com/yerfor/GeneFace)和[AD-NeRF](https://github.com/YudongGuo/AD-NeRF)。感谢这些优秀项目的贡献。











