
EVE: 无编码器视觉语言模型的突破性进展
在人工智能领域,视觉语言模型(Vision-Language Models, VLMs)一直是研究的热点。这些模型能够同时处理图像和文本信息,实现跨模态的理解和生成任务。然而,传统的VLMs通常依赖于复杂的视觉编码器来提取图像特征,这不仅增加了模型的复杂度,也限制了其灵活性和效率。近日,来自大连理工大学、北京智源人工智能研究院和北京大学的研究团队提出了一种全新的视觉语言模型——EVE(Encoder-free Vision-language modEls),这一创新性的模型设计为VLMs的发展开辟了新的方向。

突破性的无编码器架构
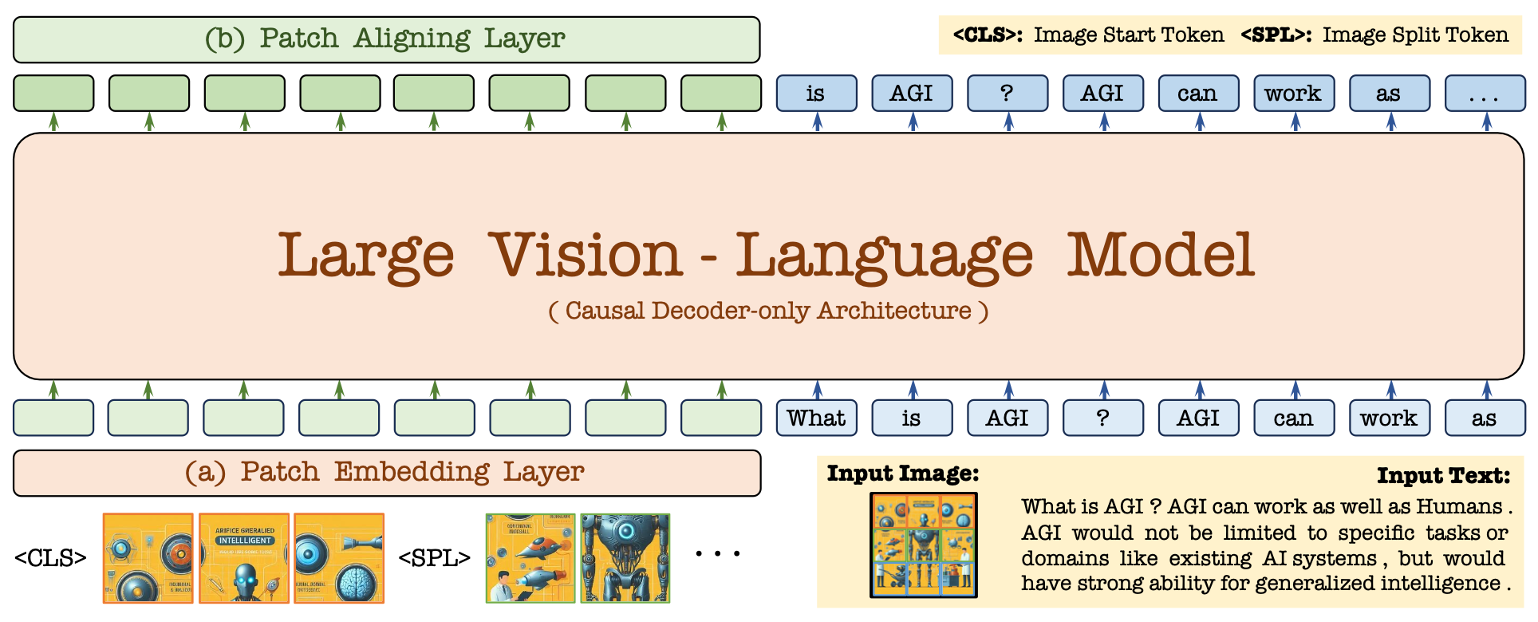
EVE的核心创新在于其完全摒弃了传统VLMs中常见的视觉编码器。这一大胆的设计决策源于研究团队对以下几个关键问题的深入思考:
- 是否可以从VLMs中移除视觉编码器?
- 如何高效且稳定地将大语言模型(LLM)转换为无编码器的VLM?
- 如何缩小无编码器VLMs与基于编码器的VLMs之间的性能差距?
通过对这些问题的探索,研究团队成功开发出了EVE这一突破性的模型架构。EVE不仅能够处理任意宽高比的图像,而且在性能上超越了同类的无编码器模型(如Fuyu-8B),甚至接近了现有的模块化编码器based VLMs的表现水平。
高效的训练策略
EVE的成功不仅仅依赖于其创新的架构设计,还得益于研究团队采用的高效训练策略。具体来说,EVE的训练过程分为三个关键阶段:
-
LLM引导的预对齐阶段: 使用1600万张图文对数据(EVE-cap16/33M)来训练patch嵌入和对齐层。这一阶段对于提高训练效率至关重要,有效防止了模型崩溃并加速了整个训练过程的收敛。
-
生成式预训练阶段: 利用全部3300万张图文对(EVE-cap33M)来训练patch嵌入、对齐层以及完整的LLM模块。
-
监督微调阶段: 对于EVE-7B版本,研究团队使用LLaVA-mix-665K数据集进行微调;而对于EVE-7B (HD)版本,则额外使用了120万条SFT对话数据。
这种分阶段的训练策略不仅提高了模型的性能,还大大提升了训练效率。整个训练过程仅需要2个8-A100 (40G)节点约9天,或4个8-A100节点约5天即可完成,展现出极高的训练效率。
卓越的性能表现
EVE在多个标准视觉语言任务上展现出了卓越的性能:
- 在VQAv2数据集上,EVE-7B-HD达到了78.6%的准确率
- 在GQA数据集上,准确率达到62.6%
- 在VizWiz数据集上,准确率达到51.1%
- 在TextVQA数据集上,准确率达到56.8%
这些结果不仅超越了同类的无编码器模型,甚至接近或超过了一些基于编码器的VLMs,充分证明了EVE架构的有效性和潜力。
广泛的应用前景
EVE的出现为视觉语言模型的应用开辟了新的可能性。由于摒弃了复杂的视觉编码器,EVE具有更高的灵活性和效率,这使得它在多种场景下都有潜在的应用价值:
-
实时视觉问答系统: EVE能够快速处理输入图像并生成回答,适合构建低延迟的视觉问答应用。
-
多模态内容生成: EVE可以基于图像和文本输入生成连贯的多模态内容,为创意写作、广告文案等领域提供支持。
-
智能图像分析: 在医疗影像分析、安防监控等领域,EVE可以提供更快速、准确的图像解读和描述。
-
辅助视觉障碍人士: EVE可以开发成为视觉障碍人士的"眼睛",实时描述周围环境和物体。
-
智能教育系统: 在教育领域,EVE可以用于开发交互式学习材料,帮助学生更好地理解视觉概念。
未来发展方向
尽管EVE已经取得了令人瞩目的成果,研究团队仍在积极探索进一步的改进和扩展:
-
多模态融合: 计划将更多模态(如音频、视频)整合到EVE的统一网络中,进一步增强其多模态处理能力。
-
模型系列扩展: 开发更多数据量、不同规模和更优基础模型的EVE系列,以满足不同应用场景的需求。
-
效率优化: 继续探索提高训练和推理效率的方法,使EVE能够在更广泛的硬件平台上部署。
-
领域适应: 研究如何更好地将EVE应用于特定领域(如医疗、金融等),提高其在垂直领域的表现。
-
伦理和安全: 关注EVE在实际应用中可能涉及的伦理和安全问题,确保其使用符合道德标准和法律规范。
结语
EVE的出现无疑为视觉语言模型的发展注入了新的活力。它不仅证明了无编码器架构在VLMs中的可行性,还为提高模型效率和灵活性提供了新的思路。随着研究的深入和技术的不断优化,我们有理由相信,EVE及其衍生模型将在未来的人工智能应用中发挥越来越重要的作用,推动多模态AI技术向更高水平发展。
研究团队的这一开创性工作为整个AI社区提供了宝贵的经验和资源。他们不仅公开了模型的代码和预训练权重,还详细描述了训练过程和评估方法,这种开放和透明的态度无疑将促进整个领域的协作与进步。我们期待看到更多研究者和开发者基于EVE的工作,开发出更多创新的应用和解决方案,共同推动视觉语言模型技术的蓬勃发展。









