
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文 EVE:揭示无编码器的视觉语言模型
EVE:揭示无编码器的视觉语言模型
揭示无编码器的视觉语言模型 的官方 PyTorch 实现。
📜 新闻
[2024/07/01] 我们发布了训练代码和 EVE-7B 权重!🚀
[2024/06/23] 我们发布了评估代码、EVE-7B-Pretrain 和 EVE-7B-HD 权重!🚀
[2024/06/18] 论文已发布!💥
💡 动机
-
我们能否从视觉语言模型中移除视觉编码器?
-
如何高效稳定地将大语言模型转换为无编码器的视觉语言模型?
-
如何弥合无编码器和基于编码器的视觉语言模型之间的性能差距?

🛸 架构
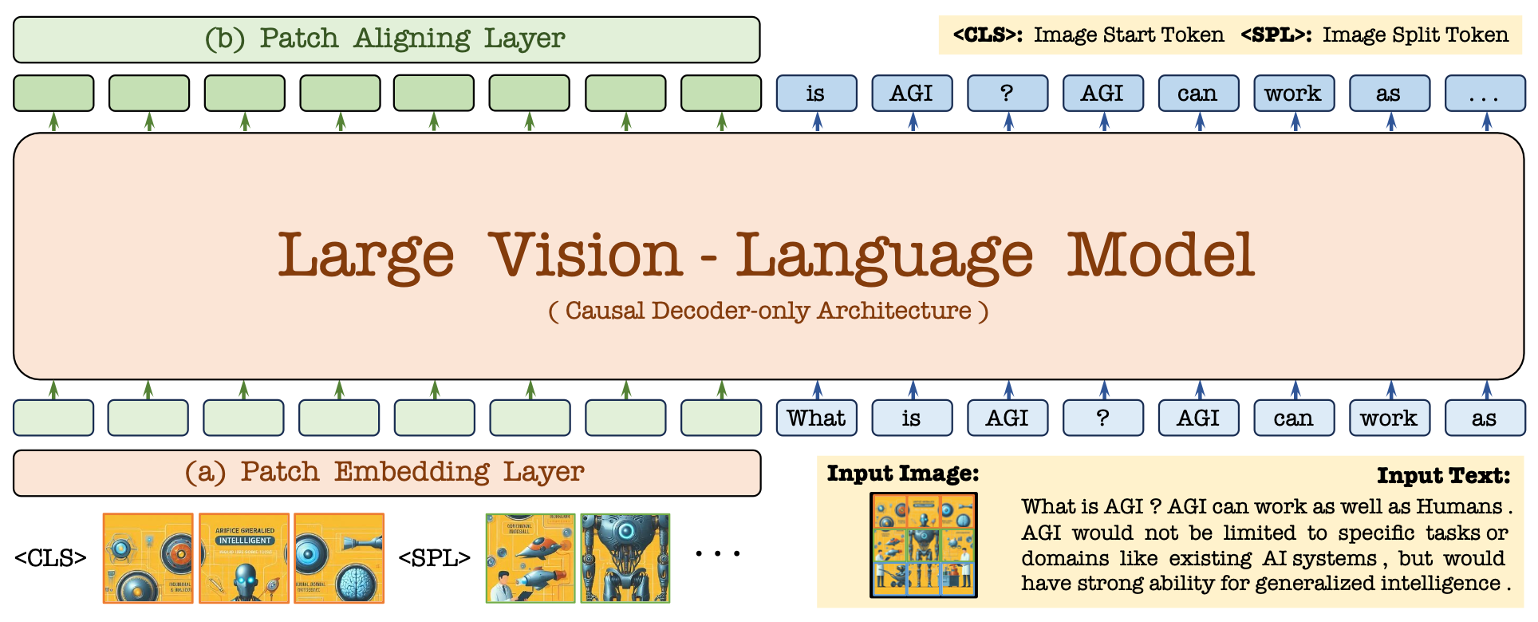
-
机构: 大连理工大学;北京人工智能研究院;北京大学
-
模型库: [🤗EVE-7B-Pretrain] [🤗EVE-7B] [🤗EVE-7B-HD]
💡 亮点
-
🔥 卓越能力: 原创的无编码器大规模视觉语言模型,支持任意图像宽高比,性能超越对应的 Fuyu-8B,接近现有的模块化基于编码器的大规模视觉语言模型。
-
🔥 数据效率: 仅从 OpenImages、SAM、LAION 中筛选 3300万 公开可用数据进行预训练;利用 66.5万 LLaVA SFT 数据训练 EVE-7B,额外使用 120万 SFT 数据训练 EVE-7B (HD)。
-
🔥 训练效率: 使用两个 8-A100 (40G) 节点训练约 9 天或四个 8-A100 节点训练约 5 天
-
🔥 开创性路线: 我们尝试提供一种高效、透明和实用的训练策略和流程,用于开发跨模态的纯解码器架构。
🤖 模型库
EVE 检查点的使用应遵守基础大语言模型的许可证:Llama 2。
| 模型 | LLM | 权重 | VQAv2 | GQA | VizWiz | SQA_I | TextVQA | POPE | MME_P | MMBench | SEED/SEED_I | MM_Vet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EVE_7B_Pretrain | Vicuna_7B | HF_link | -- | -- | -- | -- | -- | -- | -- | -- | -- / -- | -- |
| EVE_7B | Vicuna_7B | HF_link | 75.4 | 60.8 | 41.8 | 63.0 | 51.9 | 83.6 | 1217.3 | 49.5 | 54.3 / 61.3 | 25.6 |
| EVE_7B_HD | Vicuna-7B | HF_link | 78.6 | 62.6 | 51.1 | 64.9 | 56.8 | 85.0 | 1305.7 | 52.3 | 56.8 / 64.6 | 25.7 |
👨💻 待办事项
- 将更多模态融入统一的 EVE 网络。
- 使用更多数据、不同规模和更好的基础模型训练完整的 EVE 系列。
目录
安装
环境
git clone https://github.com/baaivision/EVE.git
cd EVE
conda create -n eve_envs python=3.10 -y
conda activate eve_envs
pip install --upgrade pip
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
准备工作
下载 vicuna_model 并解压到 lmsys/ 路径:
下载 preprocessor 并解压到 openai/ 路径:
lmsys
├── vicuna-7b-v1.5
│ │── config.json
│ │── ...
openai
├── clip-vit-large-patch14-336
│ │── config.json
│ │── ...
├── eve-patch14-anypixel-672
│ │── preprocessor_config.json
│ │── ...
├── eve-patch14-anypixel-1344
│ │── preprocessor_config.json
│ │── ...
快速使用
from eve.model.builder import load_pretrained_model
from eve.mm_utils import get_model_name_from_path
from eve.eval.run_eve import eval_model
model_path = "BAAI/EVE-7B-HD-v1.0 的绝对路径"
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path=model_path,
model_base=None,
model_name=get_model_name_from_path(model_path)
)
查看 eve/model/builder.py 中的 load_pretrained_model 函数了解详细信息。
您也可以使用 eve/eval/eval_one_sample.py 轻松获取输出。这样,您可以在下载此仓库后直接在 Colab 上使用此代码。
# 运行脚本
CUDA_VISIBLE_DEVICES=0 python eve/eval/eval_one_sample.py
演示
你也可以使用以下脚本在本地搭建演示:
# 运行脚本
python tools/app.py
数据
你应该按照Data.md中的说明来管理数据集。目前,我们提供网络数据的直接下载访问。但是,为了避免潜在的争议,我们计划在不久的将来发布这些数据集的URL,而不是原始数据。
训练
(1) LLM引导的预对齐阶段: 我们只使用33M图像-文本数据中的16M(EVE-cap16/33M)来训练图像块嵌入和对齐层。这确实对高效训练很重要,因为它可以防止崩溃并加速整个过程的收敛。
| 模型 | 轮次 | 批量大小 | 学习率 | 学习率调度 | 预热比例 | 最大长度 | 权重衰减 | 优化器 | DeepSpeed |
|---|---|---|---|---|---|---|---|---|---|
| EVE_Prealign | 1 | 512 | 4e-4 | 余弦衰减 | 0.03 | 2048 | 0 | AdamW | zero3 |
EVE_Prealign的训练脚本如下:
bash scripts/eve/eve7b_prealign.sh ${node_rank} ${master_addr}
(2) 生成式预训练阶段: 我们使用全部33M图像-文本对(EVE-cap33M)来训练图像块嵌入和对齐层,以及完整的LLM模块。
| 模型 | 轮次 | 批量大小 | 学习率 | 学习率调度 | 预热比例 | 最大长度 | 权重衰减 | 优化器 | DeepSpeed |
|---|---|---|---|---|---|---|---|---|---|
| EVE_Pretrain | 1 | 512 | 4e-5 | 余弦衰减 | 0.01 | 2048 | 0 | AdamW | zero3 |
EVE_Pretrain的训练脚本如下:
bash scripts/eve/eve7b_pretrain.sh ${node_rank} ${master_addr}
(3) 监督微调阶段: 我们使用LLaVA-mix-665K对EVE-7B的整个架构进行微调,对于EVE-7B (HD)则额外使用120万SFT对话数据。
| 模型 | 轮次 | 批量大小 | 学习率 | 学习率调度 | 预热比例 | 最大长度 | 权重衰减 | 优化器 | DeepSpeed |
|---|---|---|---|---|---|---|---|---|---|
| EVE_Finetune | 1 | 128 | 2e-5 | 余弦衰减 | 0.01 | 2048/4096 | 0 | AdamW | zero3 |
EVE_7B和EVE_7B_HD的训练脚本如下:
bash scripts/eve/eve7b_finetune.sh ${node_rank} ${master_addr}
bash scripts/eve/eve7b_finetune_hd.sh ${node_rank} ${master_addr}
[注意]:
如果使用较少的GPU进行训练,你可以减小per_device_train_batch_size并相应增加gradient_accumulation_steps。始终保持全局批量大小不变:per_device_train_batch_size x gradient_accumulation_steps x num_gpus。
评估
为了确保可重复性,我们使用贪婪解码评估模型。我们不使用束搜索进行评估,以使推理过程与实时输出的聊天演示保持一致。
❤️ 致谢
✒️ 引用
如果EVE对您的研究有帮助,请考虑点赞 ⭐ 和引用 📝 :
@article{diao2024EVE,
title={Unveiling Encoder-Free Vision-Language Models},
author={Diao, Haiwen and Cui, Yufeng and Li, Xiaotong and Wang, Yueze and Lu, Huchuan and Wang, Xinlong},
journal={arXiv preprint arXiv:2406.11832},
year={2024}
}
📄 许可证
本项目内容本身根据LICENSE许可。











