
 Github
Github Huggingface
Huggingface 论文
论文VisualRWKV:基于RWKV的视觉语言模型

VisualRWKV是一个基于RWKV语言模型的视觉语言模型,使RWKV能够处理各种视觉任务。
VisualRWKV:探索视觉语言模型的循环神经网络 [论文]
Eagle和Finch:具有矩阵值状态和动态循环的RWKV [论文]
新闻和更新
- 2024.06.25 🔥 VisualRWKV-6.0检查点已发布! [权重]
- 2024.05.11 🔥 VisualRWKV-6.0代码已发布! [代码]
- 2024.03.25 🔥 VisualRWKV-5.0已发布!
架构
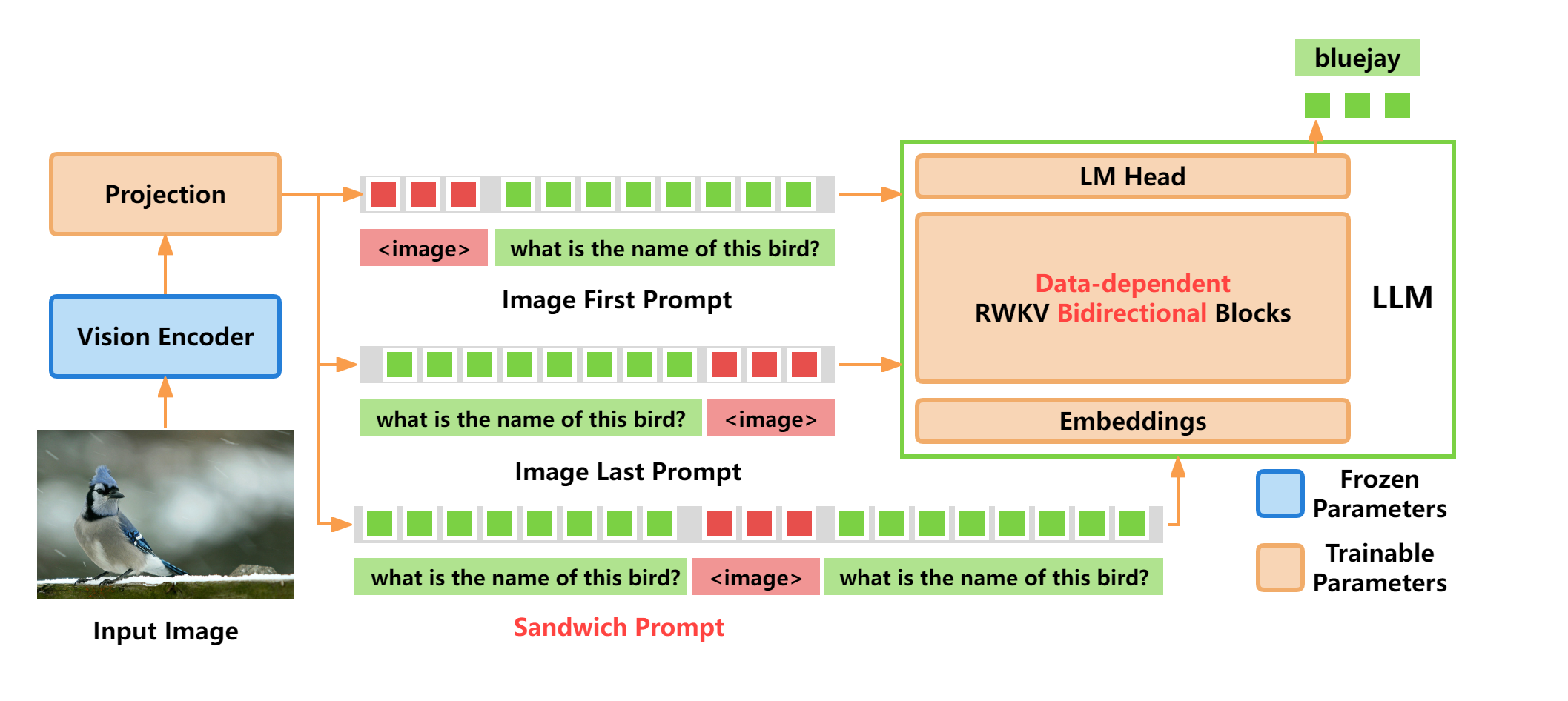
模型库
VisualRWKV权重、检查点和相关结果展示在以下markdown文件中[模型库]。
安装
- 克隆此仓库并进入VisualRWKV文件夹,VisualRWKV-v6.0是稳定版本。
git clone https://github.com/howard-hou/VisualRWKV.git
cd VisualRWKV-v6/v6.0
- 安装包
conda create -n llava python=3.10 -y
conda activate visualrwkv
pip install --upgrade pip # 启用PEP 660支持
#参考:
pip install torch==1.13.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
pip install pytorch-lightning==1.9.5 deepspeed==0.7.0 wandb ninja
最佳性能:
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
预训练和微调
最新稳定版本是VisualRWKV-v6/v6.0,请进入VisualRWKV-v6/v6.0目录运行代码。
VisualRWKV训练包括两个阶段:
- (1) 预训练阶段:使用预训练数据集来训练从冻结的预训练视觉编码器到冻结的RWKV的投影层;
- (2) 微调阶段:使用视觉指令数据,教导模型遵循视觉指令。
预训练
下载 LLaVA-Pretrain 数据集
你可以下载 LLaVA-Pretrain 数据集。
下载用于预训练的 RWKV 检查点
如果你想自己进行预训练,可以从下表中的链接下载 RWKV 检查点。
| VisualRWKV 版本 | RWKV 1B6 | RWKV 3B | RWKV 7B |
|---|---|---|---|
| VisualRWKV-v6 | RWKV-x060-World-1B6 | RWKV-x060-World-3B | RWKV-x060-World-7B |
预训练命令
你可以参考以下命令来预训练 VisualRWKV-v6.0 模型。也可以查看 scripts/train 目录中的脚本。
# 这是一个使用 4 个 GPU 预训练 1B5 RWKV 模型的示例
export CUDA_VISIBLE_DEVICES=0,1,2,3
python train.py --load_model /path/to/rwkv/checkpoint \
--wandb "" --proj_dir path/to/output/ \
--data_file /path/to/LLaVA-Pretrain/blip_laion_cc_sbu_558k.json \
--data_type "json" --vocab_size 65536 \
--ctx_len 1024 --epoch_steps 1000 --epoch_count 9 --epoch_begin 0 --epoch_save 0 \
--micro_bsz 16 --accumulate_grad_batches 2 --n_layer 24 --n_embd 2048 --pre_ffn 0 \
--lr_init 1e-3 --lr_final 1e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
--accelerator gpu --devices 4 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 0 \
--image_folder /path/to/LLaVA-Pretrain/images/ \
--vision_tower_name /path/to/openai/clip-vit-large-patch14-336 \
--freeze_rwkv 24 --detail low --grid_size -1 --image_position first \
--enable_progress_bar True
视觉指令微调
准备数据
请参考 LLaVA 项目获取视觉指令数据。
微调命令
你可以参考以下命令来微调 VisualRWKV-v6.0 模型。也可以查看 scripts/train 目录中的脚本。
# 这是一个使用 8 个 GPU 微调 1B5 RWKV 模型的示例
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python train.py --model_path path/to/pretrained-visualrwkv \
--wandb "" --proj_dir out/rwkv1b5-v060_mix665k \
--data_file /path/to/LLaVA-Instruct-150K/shuffled_llava_v1_5_mix665k.json \
--data_type "json" --vocab_size 65536 \
--ctx_len 2048 --epoch_steps 1000 --epoch_count 20 --epoch_begin 0 --epoch_save 5 \
--micro_bsz 8 --accumulate_grad_batches 2 --n_layer 24 --n_embd 2048 --pre_ffn 0 \
--lr_init 2e-5 --lr_final 2e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
--accelerator gpu --devices 8 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 0 \
--image_folder /path/to/LLaVA-Instruct-150K/images/ \
--vision_tower_name /path/to/openai/clip-vit-large-patch14-336 \
--freeze_rwkv 0 --freeze_proj 0 --detail low --grid_size -1 --image_position middle \
--enable_progress_bar True











