
Diffusion Policy:视觉运动策略学习的新范式
在机器人学习与控制领域,如何让机器人通过视觉信息学习复杂的运动策略一直是一个具有挑战性的问题。近期,由哥伦比亚大学和丰田研究院联合开发的Diffusion Policy为这一问题提供了一个创新的解决方案。本文将深入探讨Diffusion Policy的核心理念、技术特点以及其在实际应用中的表现。
Diffusion Policy的核心理念
Diffusion Policy的核心思想是将扩散模型(Diffusion Models)应用于机器人策略学习。扩散模型最初在图像生成领域取得了巨大成功,而Diffusion Policy创新性地将这一概念扩展到了机器人控制领域。
在Diffusion Policy中,机器人的动作被视为一个需要生成的"图像",而环境观察则作为条件信息。通过逐步去噪的过程,模型能够从随机噪声中生成精确的机器人动作序列,以响应给定的环境观察。
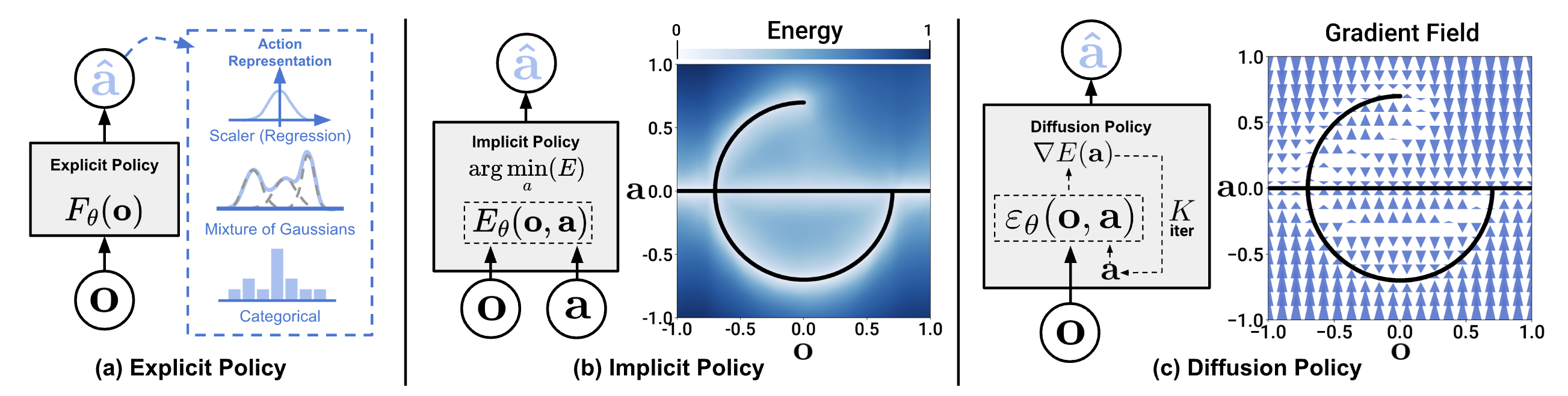
这种方法具有几个显著的优势:
-
多模态动作分布处理:Diffusion Policy能够优雅地处理多模态动作分布,这在复杂的机器人任务中至关重要。
-
适用于高维动作空间:该方法特别适合处理高维动作空间,这是许多传统方法的瓶颈。
-
训练稳定性:Diffusion Policy展现出了令人印象深刻的训练稳定性,这对于实际应用至关重要。
技术实现与创新
Diffusion Policy的技术实现涉及多个创新点:
-
条件去噪扩散过程:模型使用条件去噪扩散过程来生成动作,这允许在给定环境观察的情况下精确控制动作生成。
-
时序建模:为了处理时序数据,Diffusion Policy采用了特殊的时序建模技术,能够有效捕捉动作序列中的时间依赖关系。
-
视觉特征提取:对于基于图像的任务,模型使用先进的视觉特征提取网络,以从原始图像中提取关键信息。
实验验证与性能
Diffusion Policy在多个具有挑战性的机器人任务中进行了测试,包括物体操纵、精确定位等。实验结果显示,Diffusion Policy在这些任务中的性能普遍优于现有的最先进方法。
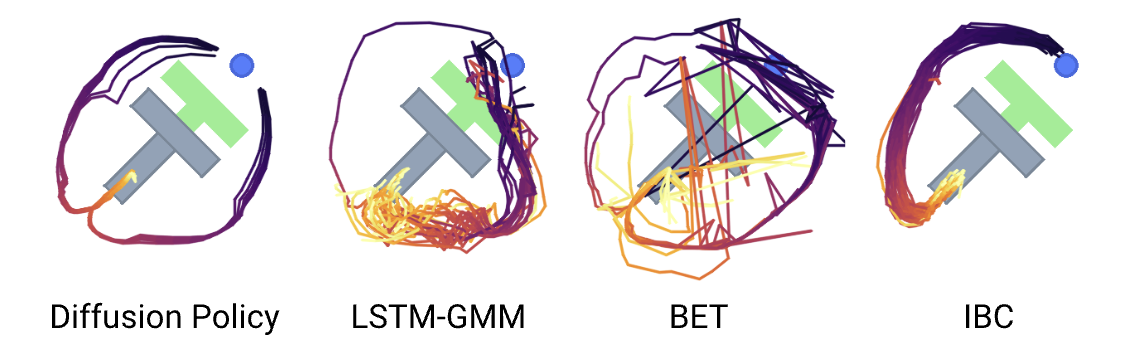
特别值得注意的是,Diffusion Policy在以下方面表现出色:
-
样本效率:相比其他方法,Diffusion Policy能够从较少的训练数据中学习有效的策略。
-
泛化能力:在面对新的、未见过的场景时,Diffusion Policy展现出了良好的泛化能力。
-
实时性能:尽管涉及复杂的生成过程,Diffusion Policy仍能满足实时控制的需求。
Diffusion Policy的实际应用
Diffusion Policy不仅在仿真环境中表现出色,还成功地应用于实际的机器人系统。研究团队使用UR5机器人臂进行了一系列实验,验证了该方法在现实世界中的有效性。
实验设置
实验使用了以下硬件配置:
- 1台UR5-CB3或UR5e机器人臂
- 2个RealSense D415深度相机
- 1个3Dconnexion SpaceMouse(用于遥操作)
- 定制的末端执行器和任务相关物体
软件方面,研究团队开发了一套完整的系统,包括:
- 基于Ubuntu 20.04的操作系统
- ROS(Robot Operating System)用于机器人控制和传感器集成
- 自定义的数据收集和处理管道
- 基于PyTorch的Diffusion Policy实现
实验任务与结果
研究团队设计了多个具有挑战性的任务来测试Diffusion Policy的性能,包括:
- Push-T任务:机器人需要将一个T形物体精确推到指定位置。
- 物体抓取与放置:在复杂环境中抓取并放置多个物体。
- 精细操作:如拧螺丝、插接等需要高精度的任务。
实验结果令人鼓舞:
- 在Push-T任务中,Diffusion Policy实现了超过90%的成功率,远高于基线方法。
- 在物体抓取与放置任务中,该方法展现出了优秀的泛化能力,能够处理各种形状和大小的物体。
- 在精细操作任务中,Diffusion Policy的精度和稳定性得到了充分验证。
这些结果证明,Diffusion Policy不仅在理论上有优势,在实际应用中也能够有效解决复杂的机器人控制问题。
Diffusion Policy的未来发展
尽管Diffusion Policy已经展现出了巨大的潜力,但这项技术仍有很大的发展空间。以下是一些潜在的研究方向:
-
提高计算效率:虽然Diffusion Policy能够实时运行,但进一步提高其计算效率将使其适用于更广泛的应用场景。
-
多任务学习:探索如何让Diffusion Policy同时学习多个任务,并在任务间实现知识迁移。
-
与其他学习范式结合:例如,将Diffusion Policy与强化学习或模仿学习结合,可能会产生更强大的学习算法。
-
处理动态环境:提高Diffusion Policy在快速变化的环境中的适应能力。
-
安全性和鲁棒性:进一步研究如何确保Diffusion Policy在各种条件下的安全性和鲁棒性。
结论
Diffusion Policy代表了机器人学习与控制领域的一个重要突破。通过将扩散模型的强大生成能力应用于机器人策略学习,这种方法开辟了一条全新的研究路径。它不仅在理论上具有吸引力,在实际应用中也展现出了卓越的性能。
随着研究的深入和技术的不断完善,我们有理由相信Diffusion Policy将在未来的机器人技术中扮演越来越重要的角色。它有潜力彻底改变机器人如何学习和执行复杂任务,为更智能、更灵活的机器人系统铺平道路。
对于研究人员和工程师来说,Diffusion Policy提供了一个富有前景的研究方向。通过进一步探索和改进这一技术,我们可能会看到更多令人兴奋的应用,从工业自动化到家庭服务机器人,再到高精度医疗设备。
Diffusion Policy的出现标志着机器人学习进入了一个新时代。它不仅推动了技术的进步,也为我们重新思考机器学习和人工智能在机器人领域的应用打开了新的视角。未来,随着这一技术的不断发展和完善,我们期待看到更多令人惊叹的突破和应用。









