
GLake简介
GLake是一个用于优化GPU内存管理和IO传输的加速库。它主要解决了AI大模型训练和推理中面临的内存墙和IO传输墙挑战,能够显著提升GPU内存利用率和IO传输效率。
GLake的主要特点包括:
- 高效:通过双层GPU内存管理和全局优化,实现GPU内存池化、共享和分层,大幅提升内存利用率。
- 易用:核心功能对模型透明,无需修改代码即可用于训练和推理。
- 开放可扩展:提供可配置策略,如压缩、数据验证等。
- 安全:内置GPU内存越界检测机制,便于问题诊断。
架构设计
GLake采用分层架构设计:
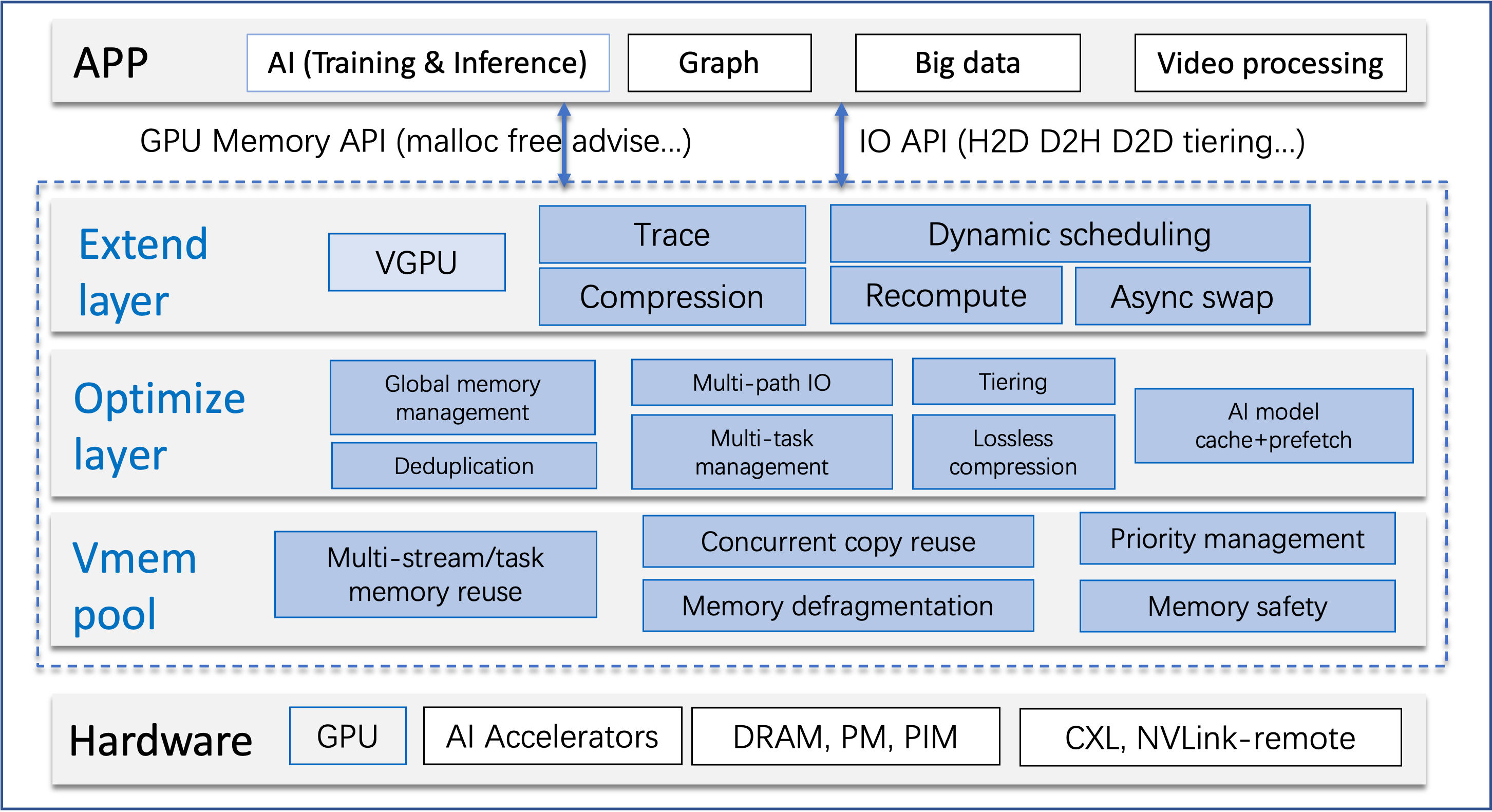
主要包括硬件接口层、GPU内存池、核心优化层、扩展层和应用生态层。目前主要支持PyTorch和NVIDIA GPU。
关键技术
GLake的核心技术包括:
- GMLake:当没有连续空闲缓冲区时,通过组合多个内存碎片返回完整缓冲区。
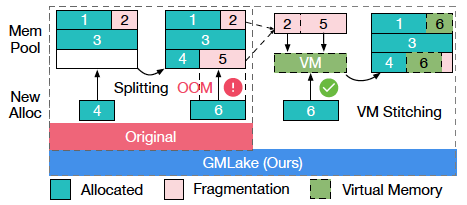
-
多路径传输:利用多个传输路径并发提高CPU-GPU IO吞吐量。
-
数据重复删除:自动发现和共享AI推理中的重复内存。
快速上手
GLake提供了简单的使用方法:
- 替换底层库(如libcuda.so或PyTorch的libc10_cuda.so)
- 按照详细步骤进行配置
更多使用说明可参考:
性能提升
GLake在多个方面带来显著性能提升:
- 训练:内存碎片减少27%,节省25G GPU内存,10B模型训练吞吐量提升近4倍。
- 推理:支持跨进程和跨模型消除重复内存,节省3倍内存。
- IO传输:CPU-GPU传输加速3倍。
未来规划
GLake团队正在开发多个有趣的新特性,包括:
- LLM KV缓存优化
- 缓存预取
- 内存分层
- 数据重复删除
- 内存调试
- 更多加速器支持
- 更多应用场景(如GNN、GraphDB等)
欢迎关注GLake项目的最新进展,并加入社区交流讨论。GLake有望成为优化GPU内存和IO传输的重要工具,为AI大模型的训练和推理带来显著性能提升。










