
GLake:突破GPU内存和IO瓶颈的利器
在人工智能快速发展的今天,大模型训练和推理正面临着严峻的挑战。随着模型规模的不断扩大,GPU内存容量和IO带宽的增长速度已经远远跟不上AI模型规模的增长速度,形成了所谓的"内存墙"和"IO传输墙"。为了应对这些挑战,一个名为GLake的开源项目应运而生,旨在通过底层优化来突破GPU内存和IO传输的瓶颈。
GLake简介
GLake是一个专注于优化GPU内存管理和IO传输的加速库及相关工具集。它主要在两个层面上进行工作:
- 底层:优化GPU虚拟和物理内存管理
- 系统层:优化多GPU、多路径和多任务场景
通过这些优化,GLake能够显著提升AI训练、推理以及开发运维(如Notebook)等场景下的硬件资源利用率。根据项目介绍,GLake可以:
- 将训练吞吐量提高至原来的4倍
- 节省推理内存高达3倍
- 加速IO传输3~12倍
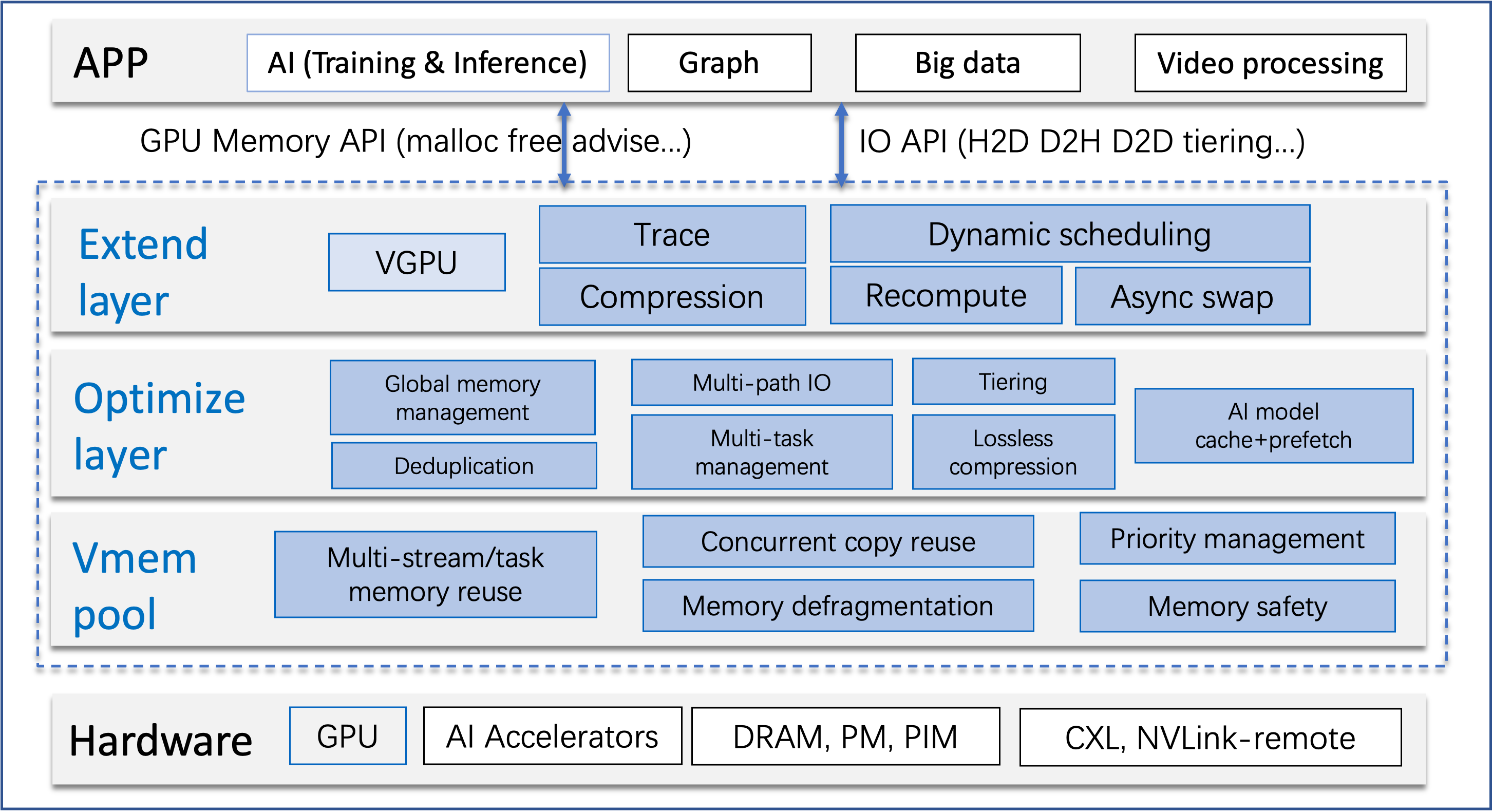
GLake的核心特性
-
高效性:GLake采用内部两层GPU内存管理和全局(多GPU、多任务)优化策略,实现了GPU内存池化、共享和分层,为训练和推理提供更大的可用GPU内存。同时,其多路径技术可以将CPU-GPU传输速度提升3~12倍。
-
易用性:GLake的核心功能对模型是透明的,无需修改训练和推理代码即可使用。它可以轻松集成到现有的深度学习引擎中,如PyTorch。此外,GLake还提供了RPC接口,允许用户在线查询GPU内存的内部统计信息(如内存碎片化程度)。
-
开放性和扩展性:GLake提供了可配置的策略,如压缩、数据验证、不同级别的安全检查等,使其易于根据具体需求进行扩展。
-
安全性:为了解决GPU内存越界等问题,GLake内置了GPU内存越界检测机制,有助于诊断和排查内存相关问题。
GLake的工作原理
-
GMLake技术:当没有连续的空闲缓冲区满足分配请求时,GMLake会通过组合多个内存碎片来返回一个完整的缓冲区给用户。这种技术有效减少了内存碎片化,提高了内存利用率。
-
多路径技术:GLake通过同时利用多个传输路径来提高CPU-GPU的IO吞吐量。这种方法充分利用了现有的硬件资源,显著提升了数据传输效率。
-
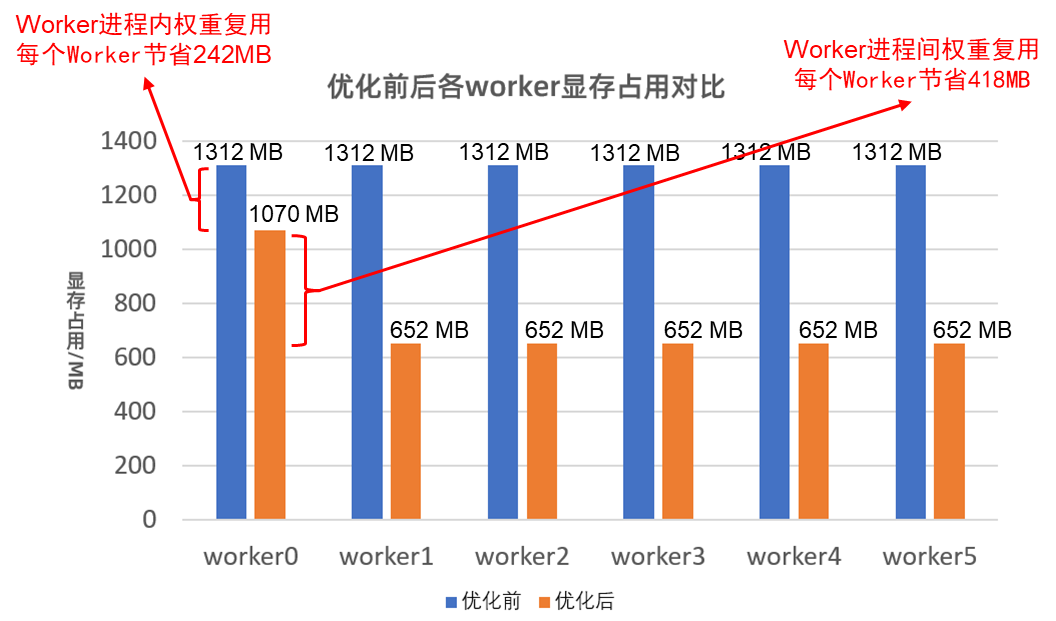
数据去重:在AI推理场景中,GLake能够自动识别重复的内存使用,并在进程间以细粒度的方式共享这些内存,从而大幅节省内存占用。
GLake的应用场景
GLake主要针对以下场景进行了优化:
-
大规模模型训练:通过减少内存碎片化和提高内存利用率,GLake能够支持更大规模模型的训练,或在相同硬件条件下提高训练效率。
-
模型推理:GLake的内存优化和数据去重技术可以显著减少推理过程中的内存占用,支持在有限的GPU内存中运行更大的模型或同时运行更多的模型实例。
-
AI开发和运维:对于使用Notebook等工具进行AI开发的场景,GLake可以提供更高效的GPU资源利用,改善开发体验。
-
大模型转换:GLake支持将大模型转换为TensorRT或ONNX Runtime格式,特别适用于NVIDIA A10/3090等GPU上的转换操作。
GLake的未来发展
GLake项目团队正在积极开发一些令人期待的新特性,包括:
- LLM KV缓存优化:以统一和高效的方式解决LLM推理中KV缓存碎片化问题。
- 缓存预取:优化微调和推理过程中的卸载和预取操作。
- 分层管理:优化跨卡/节点和各种内存类型的内存分配和数据移动。
- 更多加速器支持:计划支持更多种类的AI加速硬件。
- 扩展应用场景:如GNN、GraphDB等。
结语
GLake作为一个开源项目,为解决AI大模型面临的GPU内存和IO传输瓶颈提供了创新的解决方案。通过底层优化和系统层面的改进,GLake不仅提高了硬件资源的利用效率,还为AI研究人员和工程师提供了更好的开发体验。随着项目的不断发展和完善,GLake有望在推动AI技术进步方面发挥更大的作用。
对于有兴趣深入了解或贡献到GLake项目的开发者,可以访问其GitHub仓库获取更多详细信息和最新进展。GLake的发展无疑将为AI领域带来更多可能性,让我们共同期待它在未来带来的更多惊喜和突破。










