
LLM Guard简介
LLM Guard是一款专为大型语言模型(LLMs)设计的安全工具包,由Protect AI公司开发。它的主要目标是为LLM交互提供全面的安全保护,确保用户与AI系统之间的交互安全、可靠且符合道德标准。
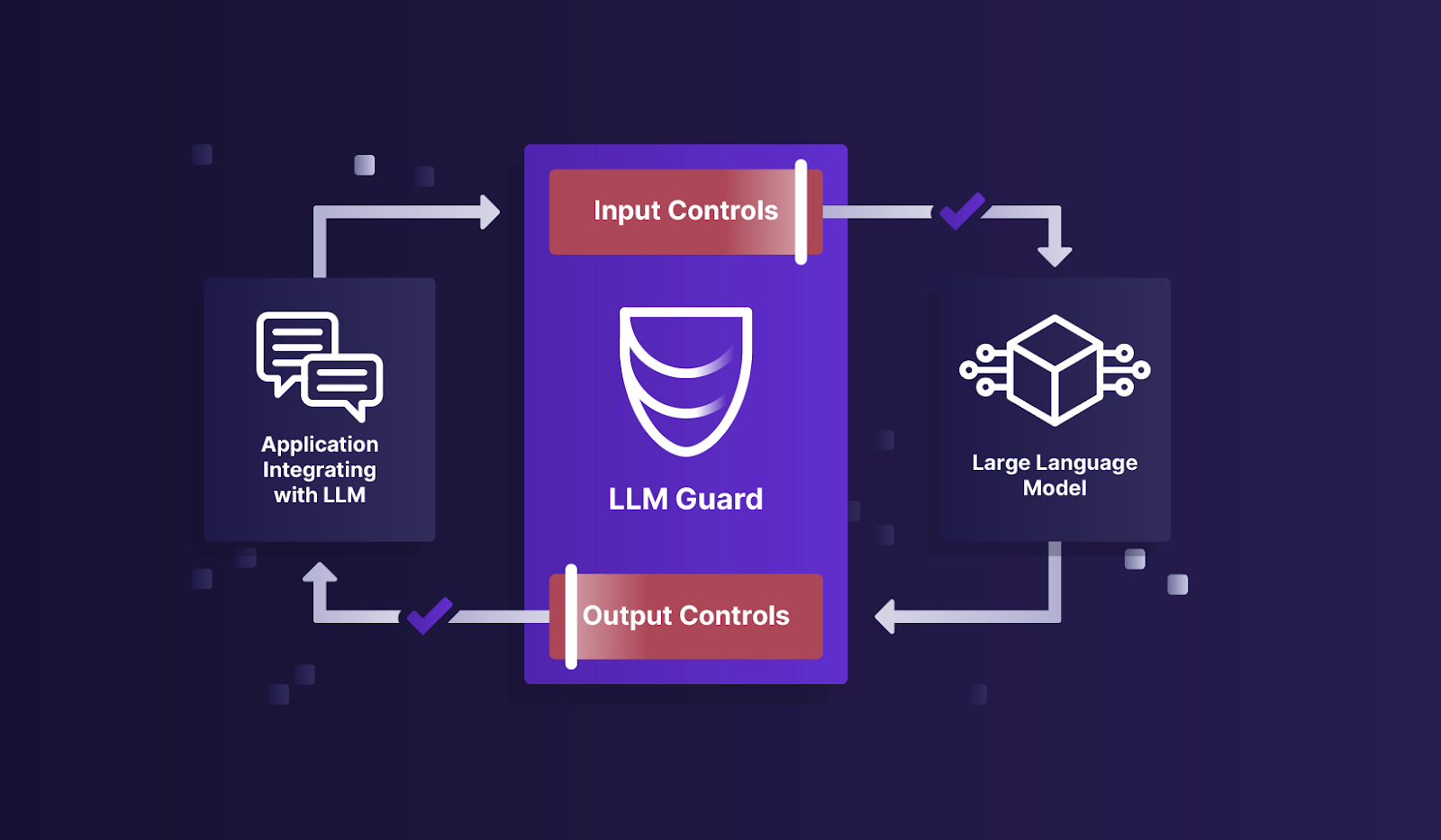
LLM Guard的核心功能
-
输入净化: 对用户输入进行清理和过滤,移除潜在的有害内容。
-
有害语言检测: 识别并阻止包含不当、冒犯或危险内容的语言。
-
数据泄露防护: 防止敏感信息在LLM交互过程中被意外泄露。
-
提示注入攻击防御: 抵御试图操纵或绕过LLM安全措施的恶意提示。
-
输出安全检查: 确保LLM生成的内容符合安全和道德标准。
通过这些功能,LLM Guard为企业和开发者提供了一个强大的工具,以确保他们的AI应用程序在与用户交互时保持安全和可控。
安装与使用
LLM Guard的安装非常简单,可以通过pip包管理器进行安装:
pip install llm-guard
安装完成后,用户需要确保使用Python 3.9或更高版本。如果在安装过程中遇到问题,可以尝试升级pip:
python -m pip install --upgrade pip
快速开始
LLM Guard提供了多种扫描器,可以单独使用或组合使用。以下是一些基本用法示例:
- 使用单个扫描器:
from llm_guard.input_scanners import BanTopics
scanner = BanTopics(topics=["violence"], threshold=0.5)
sanitized_prompt, is_valid, risk_score = scanner.scan(prompt)
- 使用多个扫描器:
from llm_guard import scan_prompt
from llm_guard.input_scanners import Anonymize, PromptInjection, TokenLimit, Toxicity
from llm_guard.vault import Vault
vault = Vault()
input_scanners = [Anonymize(vault), Toxicity(), TokenLimit(), PromptInjection()]
sanitized_prompt, results_valid, results_score = scan_prompt(input_scanners, prompt)
支持的扫描器
LLM Guard提供了丰富的扫描器,分为输入扫描器和输出扫描器两大类。
输入扫描器
输入扫描器用于检查和净化用户输入,包括:
- Anonymize: 匿名化敏感信息
- BanCode: 禁止代码输入
- BanCompetitors: 禁止竞争对手相关内容
- BanSubstrings: 禁止特定子字符串
- BanTopics: 禁止特定主题
- Code: 代码检测
- Gibberish: 无意义文本检测
- InvisibleText: 隐形文本检测
- Language: 语言检测
- PromptInjection: 提示注入检测
- Regex: 正则表达式匹配
- Secrets: 敏感信息检测
- Sentiment: 情感分析
- TokenLimit: 令牌数量限制
- Toxicity: 有毒内容检测
输出扫描器
输出扫描器用于检查和净化LLM生成的内容,包括:
- BanCode: 禁止生成代码
- BanCompetitors: 禁止生成竞争对手相关内容
- BanSubstrings: 禁止特定子字符串
- BanTopics: 禁止特定主题
- Bias: 偏见检测
- Code: 代码检测
- Deanonymize: 去匿名化检测
- JSON: JSON格式检查
- Language: 语言检测
- LanguageSame: 语言一致性检查
- MaliciousURLs: 恶意URL检测
- NoRefusal: 拒绝回答检测
- ReadingTime: 阅读时间估算
- FactualConsistency: 事实一致性检查
- Gibberish: 无意义文本检测
- Regex: 正则表达式匹配
- Relevance: 相关性检查
- Sensitive: 敏感信息检测
- Sentiment: 情感分析
- Toxicity: 有毒内容检测
- URLReachability: URL可达性检查
与其他工具的集成
LLM Guard可以轻松集成到现有的AI应用程序中。例如,它可以与OpenAI的ChatGPT API一起使用:
import os
from openai import OpenAI
from llm_guard import scan_prompt, scan_output
from llm_guard.input_scanners import Anonymize, PromptInjection, TokenLimit, Toxicity
from llm_guard.output_scanners import Deanonymize, NoRefusal, Relevance, Sensitive
from llm_guard.vault import Vault
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
vault = Vault()
input_scanners = [Anonymize(vault), Toxicity(), TokenLimit(), PromptInjection()]
output_scanners = [Deanonymize(vault), NoRefusal(), Relevance(), Sensitive()]
prompt = "Your prompt here"
sanitized_prompt, results_valid, results_score = scan_prompt(input_scanners, prompt)
if all(results_valid.values()):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": sanitized_prompt},
],
temperature=0,
max_tokens=512,
)
response_text = response.choices[0].message.content
sanitized_response_text, results_valid, results_score = scan_output(
output_scanners, sanitized_prompt, response_text
)
if all(results_valid.values()):
print(f"Output: {sanitized_response_text}\n")
else:
print(f"Output {response_text} is not valid, scores: {results_score}")
else:
print(f"Prompt {prompt} is not valid, scores: {results_score}")
社区与贡献
LLM Guard是一个开源项目,欢迎社区成员参与贡献。无论是修复bug、提出新功能、改进文档还是传播项目,都能为LLM Guard的发展做出贡献。
- 在GitHub上给项目一个星标(⭐️),支持项目发展。
- 阅读文档了解更多使用和自定义LLM Guard的信息。
- 通过GitHub Issues提交bug报告、功能请求或改进建议。
- 查看贡献指南并提交Pull Request。
此外,LLM Guard还有一个活跃的Slack社区,欢迎加入讨论、提问和分享经验。

结语
LLM Guard为大型语言模型的安全交互提供了全面的解决方案。通过其丰富的扫描器和灵活的集成方式,它能够有效地防范各种潜在的安全威胁,确保AI应用程序的安全性和可靠性。无论是企业还是个人开发者,都可以利用LLM Guard来增强他们的AI系统,为用户提供更安全、更可信的交互体验。
随着AI技术的不断发展,安全问题也变得越来越重要。LLM Guard作为一个开源项目,将继续evolve和改进,以应对新出现的安全挑战。通过社区的共同努力,LLM Guard有望成为AI安全领域的重要工具,为构建更安全、更可靠的AI生态系统做出贡献。










