
LLM2LLM: 突破性的大语言模型性能提升技术
在人工智能和自然语言处理领域,大型语言模型(LLMs)无疑是当前最炙手可热的研究方向之一。这些模型展现出了惊人的语言理解和生成能力,但在特定任务和低数据环境下仍面临着挑战。为了解决这一问题,来自加州大学伯克利分校、国际计算机科学研究所(ICSI)和劳伦斯伯克利国家实验室(LBNL)的研究团队提出了一种名为LLM2LLM的创新方法,这一方法有望彻底改变大语言模型的训练和应用方式。
LLM2LLM的核心理念
LLM2LLM的核心思想是通过一种新颖的迭代数据增强策略来提升大语言模型的性能。与传统的数据增强方法不同,LLM2LLM采用了一种更为智能和有针对性的方法。它利用一个"教师"大语言模型来生成高质量的合成数据,这些数据专门用于改善"学生"模型在特定任务上的表现。
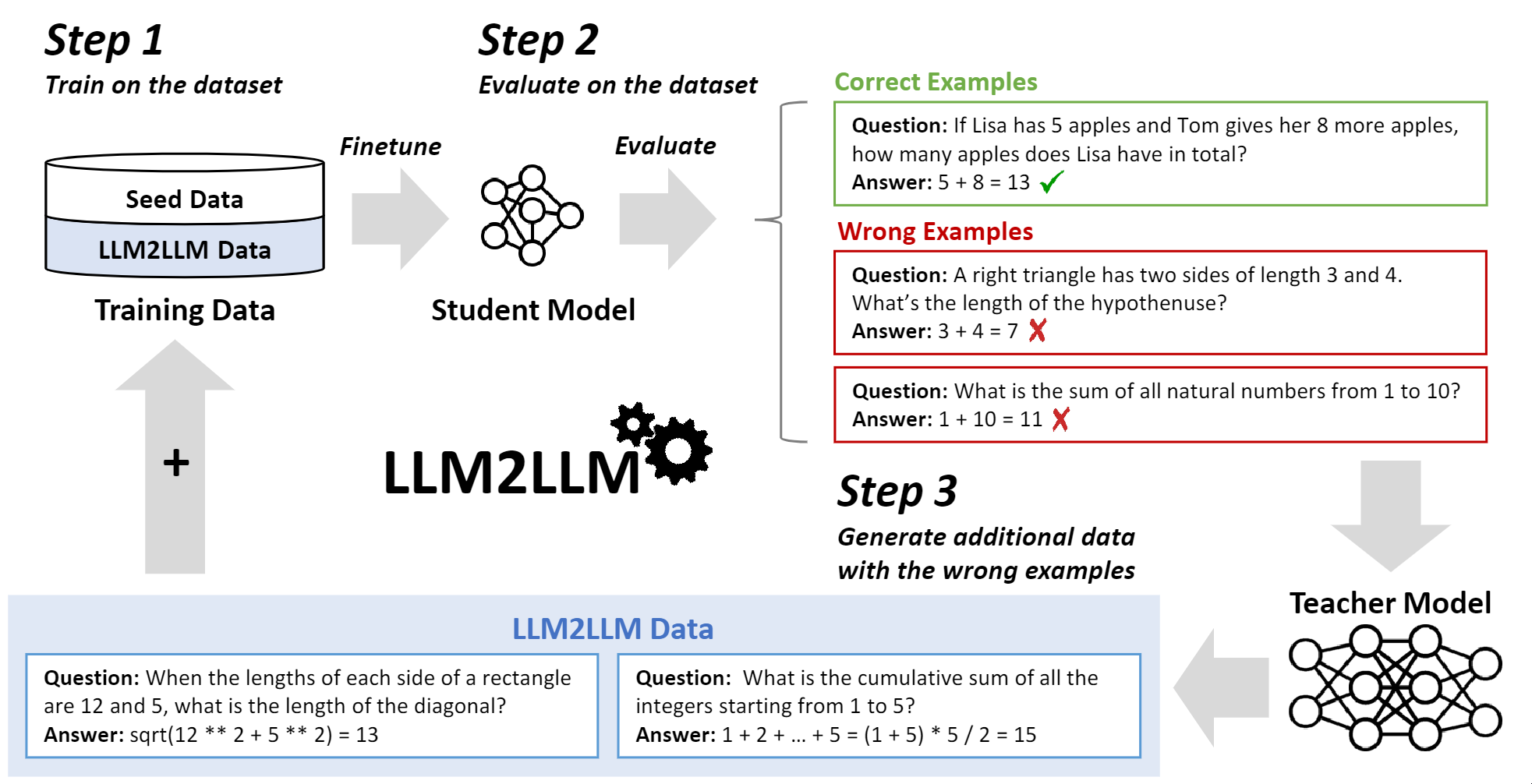
LLM2LLM的工作流程
- 初始微调: 首先,LLM2LLM会使用一个小规模的种子数据集对学生模型进行初步微调。
- 性能评估: 接下来,系统会评估学生模型的表现,识别出模型在哪些方面存在不足。
- 数据生成: 基于评估结果,教师模型会生成新的、针对性的训练数据。这些数据专门设计用来解决学生模型的弱点。
- 迭代优化: 学生模型使用新生成的数据进行进一步训练,然后重复评估和数据生成的过程。这种迭代循环持续进行,直到模型性能达到预期水平或不再有显著提升。
LLM2LLM的独特优势
- 针对性强: 与简单的同义词替换或句子重写不同,LLM2LLM生成的数据直接针对模型的薄弱环节,提供更有价值的学习材料。
- 自适应性: 通过不断评估和调整,LLM2LLM能够随着训练的进行动态地适应模型的需求。
- 效率高: 由于生成的数据都是高度相关的,LLM2LLM能够用相对较少的数据实现显著的性能提升。
- 通用性强: 这种方法可以应用于各种不同的NLP任务和模型架构。
实验结果令人振奋
研究团队在多个标准数据集上测试了LLM2LLM的效果,结果令人印象深刻:
- 在GSM8K数学推理数据集上,模型性能提升了24.2%。
- 在CaseHOLD法律案例数据集上,性能提升达到了32.6%。
- 在SNIPS自然语言理解数据集上,观察到了32.0%的性能提升。
这些结果清楚地表明,LLM2LLM能够在各种复杂任务中显著提升模型性能,特别是在训练数据有限的情况下。
LLM2LLM的潜在应用
LLM2LLM的出现为大语言模型在多个领域的应用开辟了新的可能性:
- 专业领域适应: 在医疗、法律、金融等专业领域,LLM2LLM可以帮助模型快速适应专业术语和知识结构,即使在相关训练数据稀缺的情况下也能表现出色。
- 低资源语言处理: 对于那些训练数据严重不足的小语种,LLM2LLM提供了一种有效的性能提升方法。
- 个性化AI助手: 通过LLM2LLM,可以更容易地为个人或组织定制专属的AI助手,使其能够更好地理解和响应特定的需求。
- 教育技术: 在教育领域,LLM2LLM可以用于开发更智能的tutoring系统,能够根据学生的具体情况生成针对性的学习材料。
- 研究加速: 对于科研人员来说,LLM2LLM可以帮助快速构建和优化特定领域的语言模型,加速科研进程。
技术实现细节
LLM2LLM的实现涉及多个关键步骤和技术考量:
- 模型选择: 研究中使用了LLaMA-2 7B作为基础模型,这是一个开源的大语言模型,具有强大的语言理解和生成能力。
- 数据处理: 研究团队开发了专门的数据处理脚本(如
process_data.py)来准备和管理训练数据。 - 训练流程: 核心训练逻辑封装在
train.py中,实现了LLM2LLM的迭代训练过程。 - 结果分析:
report_results.py脚本用于详细分析每次迭代后模型的性能变化。 - 配置管理: 使用YAML配置文件(
config.yaml)来灵活管理实验参数。 - 环境依赖:
requirements.txt文件列出了运行LLM2LLM所需的所有Python库。
开源与社区贡献
LLM2LLM项目已在GitHub上开源(https://github.com/SqueezeAILab/LLM2LLM),这为整个AI社区带来了巨大价值。研究人员和开发者可以直接访问、使用和改进这一创新技术。该项目的开源性质也鼓励了更广泛的合作和创新,可能会催生出LLM2LLM的新应用和改进版本。
未来展望
尽管LLM2LLM已经展现出了令人兴奋的潜力,但研究团队认为这仅仅是开始。他们计划进一步探索以下方向:
- 跨模态扩展: 将LLM2LLM的概念扩展到图像、视频等其他模态,实现更全面的AI模型增强。
- 效率优化: 进一步提高数据生成和模型训练的效率,使LLM2LLM能够在更大规模的模型和数据集上应用。
- 自动化程度提升: 开发更智能的算法来自动选择最佳的教师模型和优化策略。
- 与其他技术的结合: 探索将LLM2LLM与其他先进技术(如少样本学习、元学习等)结合的可能性。
- 伦理和偏见研究: 深入研究LLM2LLM对模型偏见的影响,确保生成的数据不会引入或放大不当偏见。
结语
LLM2LLM代表了大语言模型研究的一个重要里程碑。它不仅提供了一种强大的性能提升方法,更为我们思考AI模型的学习和适应能力开辟了新的视角。随着这项技术的不断发展和完善,我们有理由期待它将在推动AI技术更广泛、更深入地应用于各行各业中发挥关键作用。
对于那些对NLP和大语言模型感兴趣的研究者和开发者来说,LLM2LLM无疑是一个值得深入研究和实践的项目。它不仅有助于提升现有模型的性能,更可能激发出全新的应用ideas和研究方向。
随着AI技术日新月异的发展,像LLM2LLM这样的创新方法将继续推动着整个领域向前迈进。我们期待看到更多基于LLM2LLM的突破性应用,以及它如何塑造AI的未来景象。在这个充满可能性的领域中,保持开放、创新和合作的态度,将是推动技术进步和造福人类的关键。









