
 Github
Github 论文
论文LLM2LLM:通过新型迭代数据增强提升大语言模型 [论文]
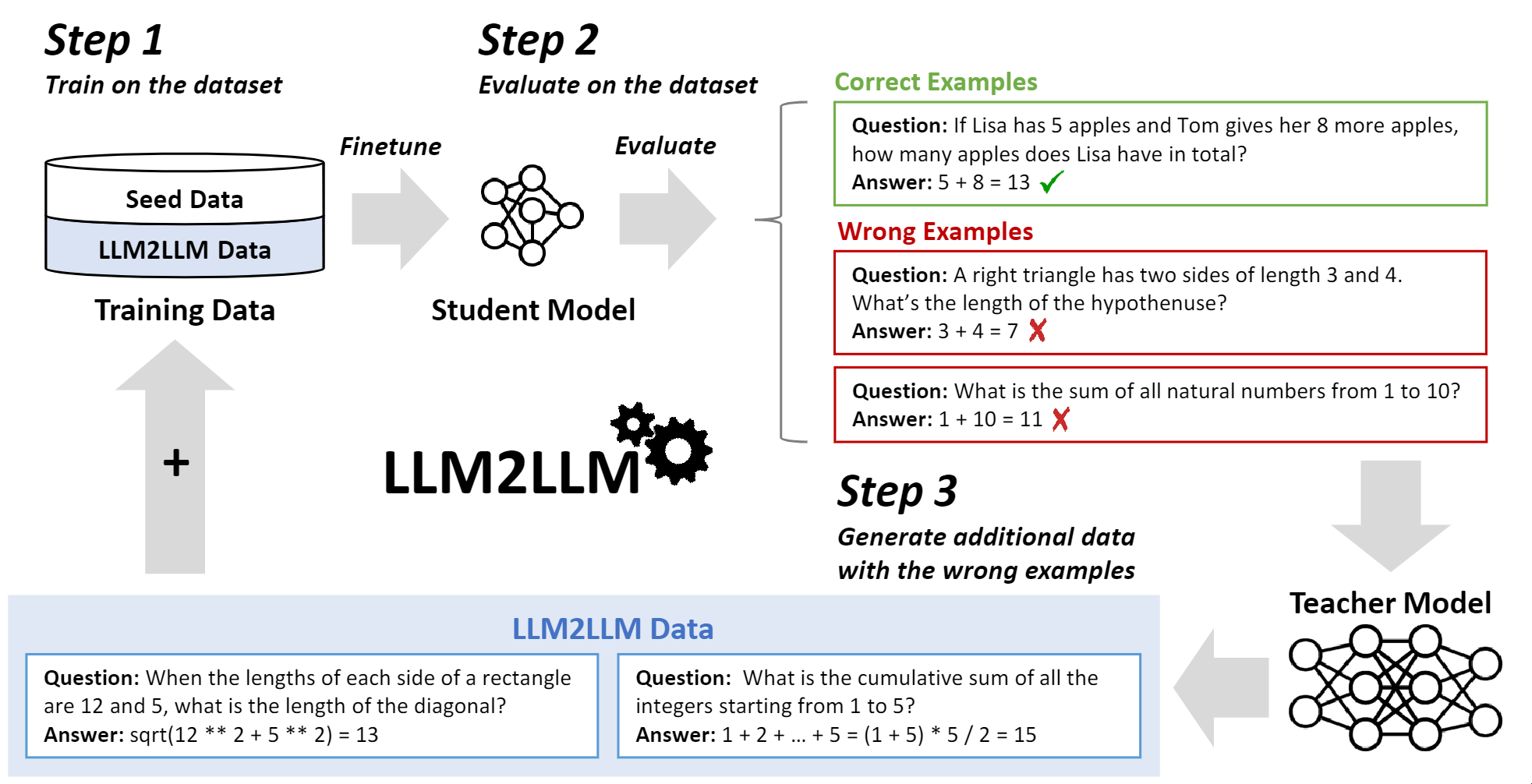
这是LLM2LLM论文的代码。
复现主要实验
我们提供了复现GSM8K主要实验所需的代码。其他数据集的说明将很快上传。
- 下载LLaMA-2-7B的副本和相应的数据集
- 通过运行以下命令克隆GSM8K数据集
cd GSM8K
git clone https://github.com/openai/grade-school-math.git
- 运行
generate_seed_data.py并调整SUBSAMPLE_SPLIT以获取种子数据。 - 确保
config.yaml中的所有设置都准确无误 - 运行
python GSM8K/generator_data.py GSM8K/config.yaml cd进入你的实验文件夹并运行./run_all.sh- 所有迭代完成后,运行
python report_results.py --results_file_name test_0.jsonl GSM8K/grade-school-math/grade_school_math/data/test.jsonl $EXP_FOLDER
以获取每次迭代中模型性能的详细分析。
这将生成一个包含所有数据和模型检查点的输出文件夹。
路线图
我们计划添加复现其他数据集实验所需的代码。
引用
LLM2LLM是作为以下论文的一部分开发的。如果您发现这个库对您的工作有用,我们将非常感谢您引用这篇论文:
@article{lee2024llm2llm,
title={LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement},
author={Lee, Nicholas and Wattanawong, Thanakul and Kim, Sehoon and Mangalam, Karttikeya and Shen, Sheng and Anumanchipali, Gopala and Mahoney, Michael W and Keutzer, Kurt and Gholami, Amir},
journel={arXiv},
year={2024},
}











