
Luotuo-Text-Embedding:开创中文文本表示新纪元
在自然语言处理(NLP)领域,文本表示一直是一个核心问题。如何将文本信息转化为计算机可以理解和处理的数值向量,对于诸多下游任务至关重要。近日,由李鲁鲁、冷子昂等多位研究者共同开发的Luotuo-Text-Embedding模型在GitHub上开源,为中文NLP社区带来了一个强大的新工具。
模型简介
Luotuo-Text-Embedding(骆驼嵌入)是一个生成式文本嵌入模型,通过蒸馏OpenAI的text-embedding-ada-002 API实现。该模型能够将任意中文文本映射到1536维的向量空间,使得语义相近的文本在该空间中的距离更接近。这一特性使得Luotuo-Text-Embedding在文本可视化、检索、聚类等多个应用场景中表现出色。

主要特点
-
多样化的模型选择: Luotuo-Text-Embedding提供了不同规模的模型版本,包括基于BERT的小型(110M参数)和中型(352M参数)模型,以及基于GLM的大型模型。用户可以根据实际需求和计算资源选择适合的版本。
-
优秀的性能表现: 通过与OpenAI API的结果对比,研究团队发现Luotuo-Text-Embedding在多个测试中均取得了可比的性能。这意味着用户可以在本地部署该模型,获得与OpenAI API相近的效果,同时避免API调用的额外开销。
-
丰富的应用示例: 项目提供了多个实用的应用示例,包括文本数据可视化、文本相关性测试、模糊问题搜索、文本聚类等。这些示例不仅展示了模型的实际应用价值,也为用户提供了快速上手的参考。
-
开源友好: 整个项目采用Apache-2.0许可证开源,鼓励社区贡献和二次开发。研究团队还计划公开训练数据集,进一步促进相关研究的发展。
技术细节
Luotuo-Text-Embedding的训练过程融合了多种先进技术:
-
多目标训练: 模型训练使用了三项损失函数,包括与OpenAI特征的均方误差(MSE)、对比句子嵌入(CSE)损失,以及KL散度损失。这种多目标训练策略有助于模型学习更加丰富和鲁棒的文本表示。
-
迁移学习: BERT版本的模型以沈向洋团队开发的中文CLIP模型为起点,通过进一步训练提升了在中文文本嵌入任务上的性能。
-
大规模数据集: 训练使用了234.5K的CNewSum新闻数据集,经过预处理后得到大量的文本对样本,为模型提供了丰富的学习材料。
应用展示
Luotuo-Text-Embedding在多个实际应用中展现出色性能:
- 文本数据可视化
研究团队开发了一个特殊的可视化工具,能够将不同类别的文本数据映射到二维平面上。这一工具不仅直观地展示了模型的聚类效果,还支持抽样展示部分文本内容,方便用户深入分析。
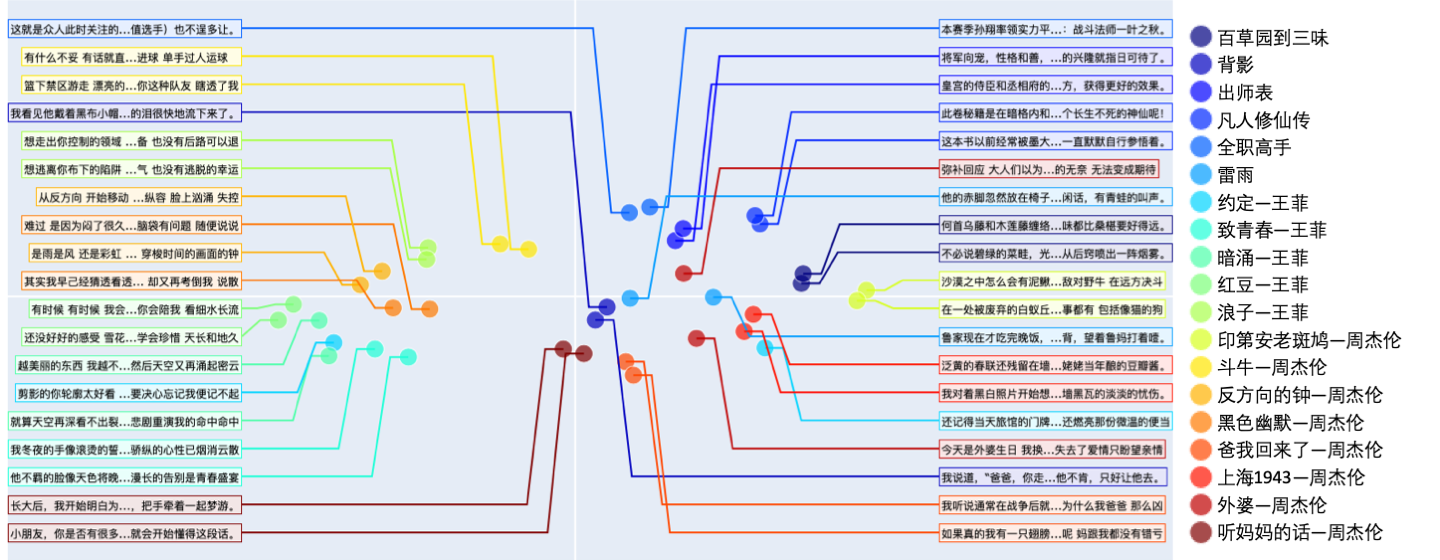
- 文本相关性测试
为验证模型的泛化能力,研究团队设计了"网文新闻测试"和"周杰伦挑战"两个测试集。结果表明,Luotuo-Text-Embedding不仅在新闻领域表现出色,在处理歌词等非正式文本时也显示出良好的相关性捕捉能力。
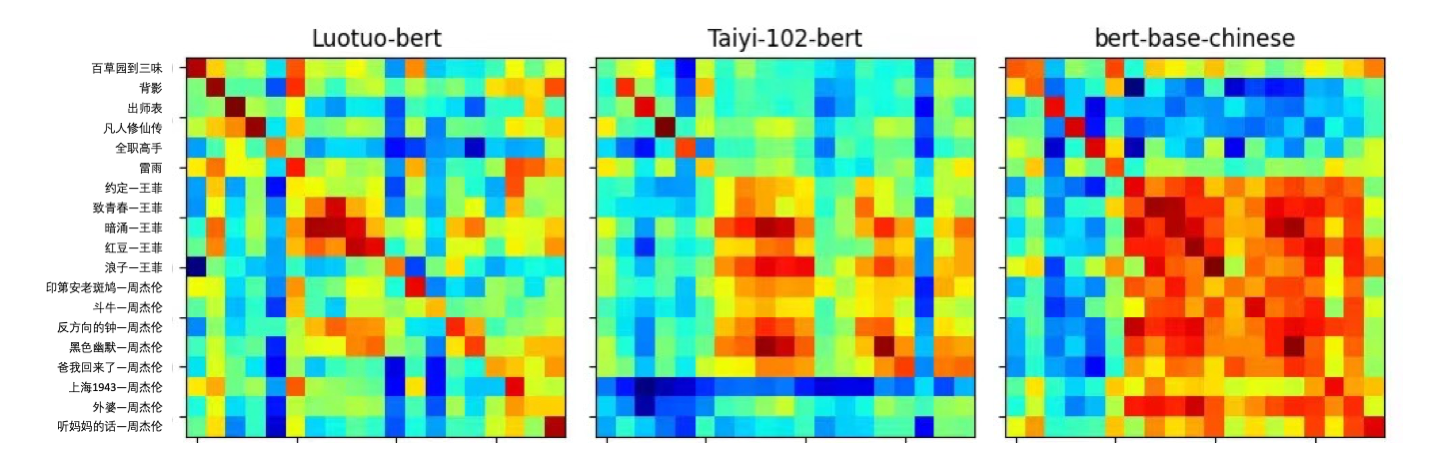
- 模糊问题搜索
在初步测试中,Luotuo-Text-Embedding展现出强大的模糊文本搜索能力。这一功能对于构建智能问答系统、信息检索等应用具有重要价值。
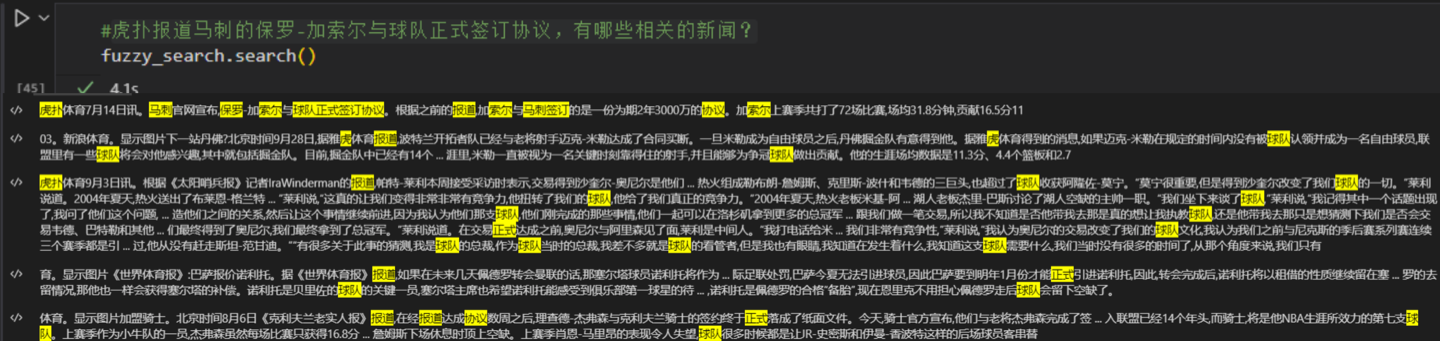
未来展望
尽管Luotuo-Text-Embedding已经取得了显著成果,研究团队仍在不断推进项目的发展:
-
领域适应: 目前模型主要基于新闻数据训练,团队计划通过增加不同领域的训练数据来提升模型的泛化能力。
-
大模型优化: 基于GLM的大型模型版本仍在优化中,有望在未来为用户提供更强大的文本表示能力。
-
应用拓展: 团队正在探索将Luotuo-Text-Embedding应用于更多下游任务,如文本分类、情感分析等。
-
社区合作: 项目欢迎社区贡献,包括但不限于提供额外训练数据、开发新的应用示例等。
结语
Luotuo-Text-Embedding的开源为中文NLP社区带来了一个强大而灵活的文本表示工具。无论是学术研究还是工业应用,该模型都有望在多个领域发挥重要作用。随着项目的不断发展和社区的积极参与,我们可以期待看到更多基于Luotuo-Text-Embedding的创新应用涌现。
对于有兴趣深入了解或使用Luotuo-Text-Embedding的读者,可以访问项目的GitHub仓库获取更多信息。让我们共同期待这个优秀的开源项目为中文NLP领域带来更多惊喜! 🚀🐫









