
 访问官网
访问官网 Github
GithubEnglish | 快速上手 | Embedding应用 | 数据 | 赞助 | 人员 | 引用 | 鲁叔的讨论
Luotuo Embedding 骆驼嵌入:从OpenAI API蒸馏的生成式文本嵌入模型
骆驼嵌入是一个文本嵌入(text embedding)模型,由冷子昂、刘思诣、黄泓森、陈舒年、胡婧、孙骜、陈启源、李鲁鲁等开发
每位作者均为第一作者,排序随机。(点击此处查看详情)
李鲁鲁发起了项目,并完成了初步的验证,提出了KL散度Loss和Hard Negative挖掘。
刘思诣完成了初步训练框架的编写,以及支持了后续模型上传到hugging face的流程。
冷子昂完成了完整的大模型和小模型的训练,包括载入数据和损失函数的实现。
陈启源准备了CNewSum的数据,做了句子切分。
黄泓森负责爬取了OpenAI Embedding的数据。
陈舒年完成了几个重要的可视化。
孙骜(即将)用我们得到的Embedding,完成CoT的提升实验。
胡婧收集了周杰伦的歌词,并(即将)完成更多的定量实验。
骆驼嵌入是Luotuo(骆驼)的子项目之一,后者由李鲁鲁、冷子昂、陈启源发起。

文本嵌入是指将一段文本转化为一定维度的向量(1536维),其中语义相近、主题相关的文本在向量空间中更接近。拥有一个良好的文本嵌入特征,对于文本可视化、检索、聚类、内容审核等下游任务具有重要意义。
-
如果您觉得这个项目有帮助,请为我们的主要仓库Luotuo(骆驼)点星,非常感谢!
-
如果您觉得这个页面对您有帮助,恳请您也去我们骆驼的主页点个star,非常感谢!
快速上手
中等规模模型已经发布,大型模型将在后续有空时发布。
| Colab链接 | 详情 | |
|---|---|---|
| 小型模型 |  | BERT 110M带可视化验证 |
| 中等模型 | | BERT 352M带可视化验证 |
| 大型模型 | - | GLM-Encoder模型带可视化验证 |
| 小型模型简化版 | | BERT 110M最简代码 |
| 中等模型简化版 | | BERT 352M最简代码 |
| 大型模型简化版 | - | GLM-Encoder模型最简代码 |
Embedding应用
所有应用示例都可以在以下Colab链接中体验 。
-
文本数据可视化 任意文本分类数据的可视化
-
文本相关性测试 周杰伦歌词之间的相关性测试
-
文本的模糊搜索 周鸿祎为什么喜欢穿红衣?
-
文本聚类 找呀找呀找朋友
-
少样本的分类学习 用embedding解决审核任务
文本数据可视化
对于任意多类的数据,围绕我们发布的Embedding模型,我们准备了一个特殊的可视化代码,可以将类别展示在二维平面,并抽样展示部分文本的内容。你可以直接在大模型链接/小模型链接中运行体验。
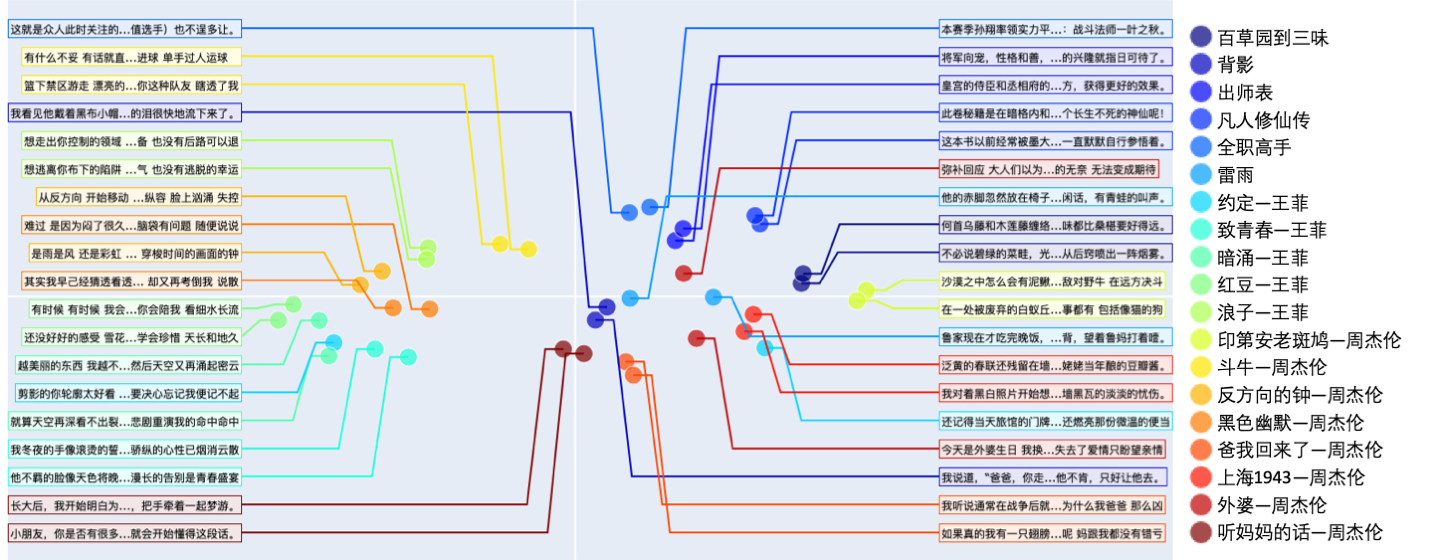
通过可视化我们可以看到,OpenAI原论文的基本假设基本得到验证,即使是很抽象的歌词,在中间切开,去除重复文本之后,前段歌词和后段歌词仍然能够呈现很强的相关性。(除了周杰伦的《外婆》,其他的)歌曲的前后段在特征空间中都很接近。
文本相关性测试
在OpenAI的论文(补充引用)中,使用了大量文本(补充数量)来进行自监督学习。其关键假设是,在切开的文本中,连续的两段长文本是相关的。在这个应用中,我们会在两个测试上验证这个假设。因为我们目前版本的模型的训练数据都是新闻,我们想找两批不同领域的语料,来验证模型的能力。
-
网文新闻数据:我们选取了15篇网文,并且加上了15篇数据集中不覆盖的新闻数据。并且寻找语料中的大段落,进行前后的切分。在网文数据中,为了增加挑战性,我们避免切分前后的数据出现过多重复的词汇。
-
周杰伦挑战:由于新闻数据前后文中会有一定数量重复的词汇,而网文叙述的连贯性也很强。所以我们想做一个更难的挑战,我们选取了3篇中学课文,2篇网文,5首王菲的歌,以及8首不同内容的周杰伦的歌。并且在这个挑战中,切分后的前文和后文中,我们人工去除了重复的短句(如副歌),并避免重复的词汇。
下面是周杰伦的第一张专辑中,一首Acid爵士风格的叙事歌曲《印第安老斑鸠》在切分后的前后歌词
前半句:沙漠之中怎么会有泥鳅 话说完飞过一只海鸥 大峡谷的风呼啸而过 是谁说没有 有一条热昏头的响尾蛇 无力的躺在干枯的河 在等待雨季来临变沼泽 灰狼啃食着水鹿的骨头 秃鹰盘旋死盯着腐肉 草原上两只敌对野牛 在远方决斗
后半句:在一处被废弃的白蚁丘 站着一只饿昏的老斑鸠 印地安老斑鸠腿短毛不多 几天都没有喝水也能活 脑袋瓜有一点秀逗 猎物死了它比谁都难过 印地安斑鸠 会学人开口 仙人掌怕羞 蜥蝪横着走 这里什么奇怪的事都有 包括像猫的狗
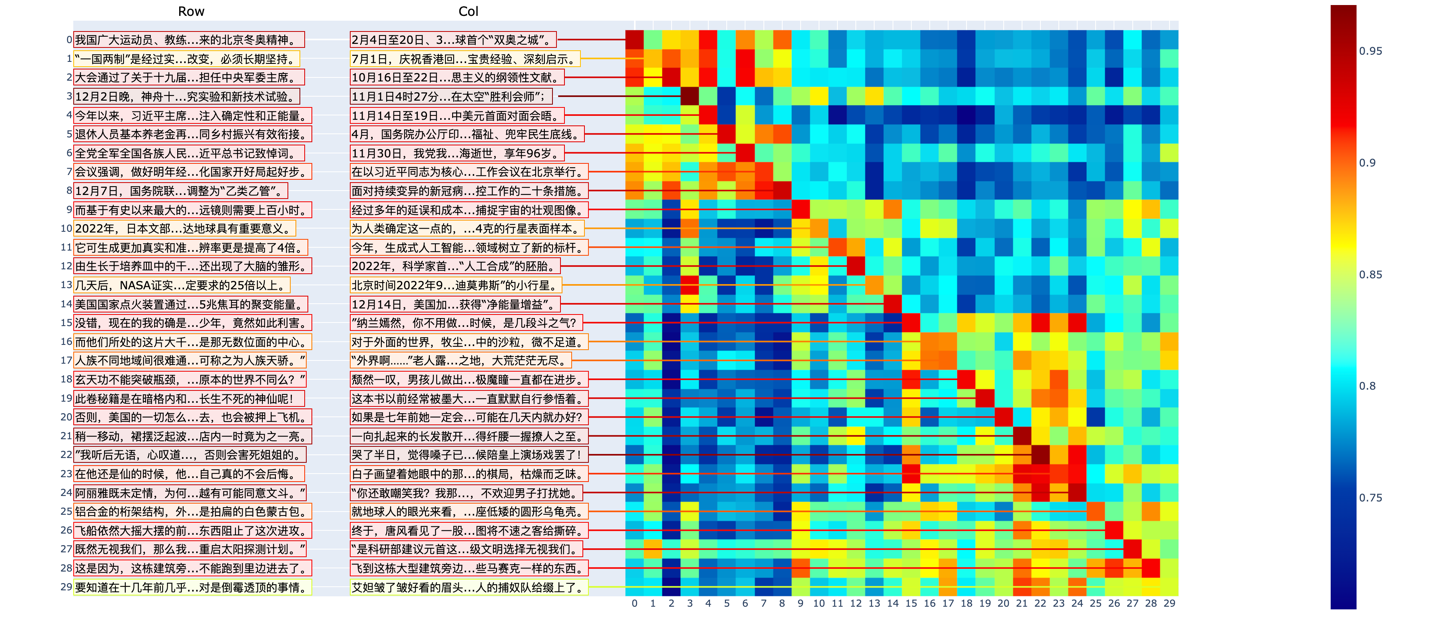
网文新闻测试
我们对Luotuo-BERT在网文新闻30对的数据上进行了测试。我们额外编写了一个可视化,除了热图的展示,我们还抽样展示了热图中涉及数据的文本信息。可以看到:
-
OpenAI论文的假设被基本验证。即一个文本的前段和后段呈现很强的相关性。
-
由于我们的模型是在新闻上训练的,当前在新闻的表现上更好。
-
对于不同领域的文本,相关性矩阵会呈现分块对角的形式,甚至在不同类型的新闻,不同类型的网文之间,也有这样的特点。
-
根据我们的测试,当前的模型在其他领域的文本上,也能体现出良好的相关性。如果进一步补充其他领域的训练文本,可以使得这个特征有更好的不同领域的适应能力。
周杰伦挑战
在周杰伦挑战中,我们对比了我们训练之前的基础模型,沈向洋老师IDEA团队的Tai-102M的BERT,以及我们训练后的Luotuo-BERT的结果,同时我们还展示了Hugging Face默认的BERT-base-Chinese模型的结果。(更大BERT的结果将在周一放出)
周杰伦挑战的图见一开始tSNE可视化。
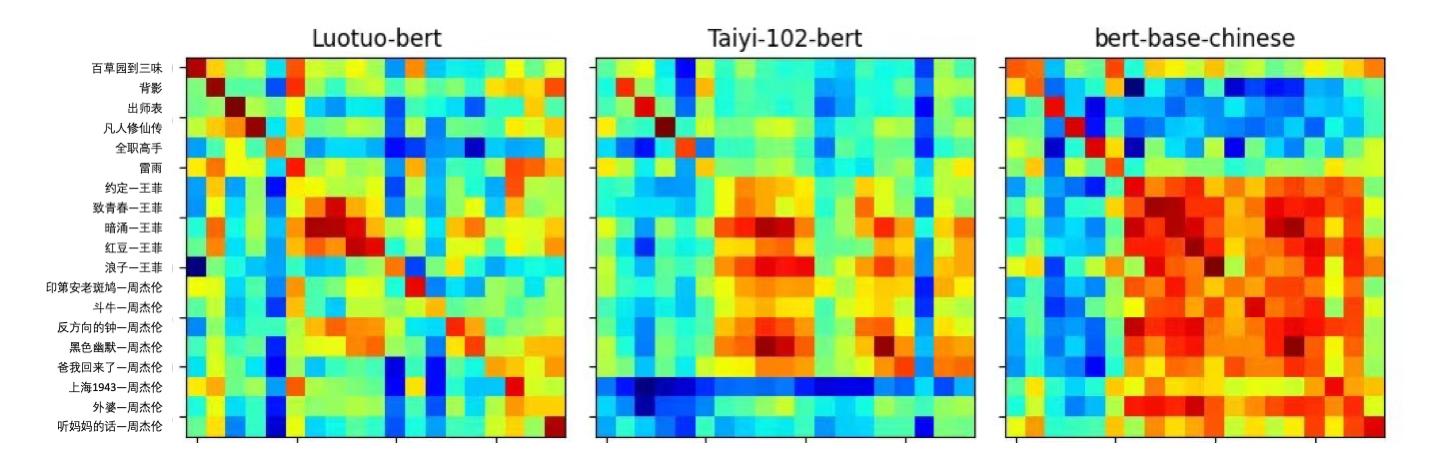
观察下图我们可以得出几个结论
-
Compared to online news tests, lyric tests are much more challenging. Even for humans observing the context, it's difficult to see obvious correlations.
-
Some songs by the same artist or with similar themes may show segmented correlations.
-
We also compared our results with OpenAI's. Through distillation learning, our LuotuoBERT can now achieve competitive results with OpenAI's API. Therefore, we are considering further strengthening the diagonal prior in the KL divergence loss, rather than simply targeting OpenAI's structure as the target probability.
More comparative results will be published in our upcoming report.
Fuzzy Question Search
In our preliminary tests, LuotuoBERT has already demonstrated strong capabilities in fuzzy text search.
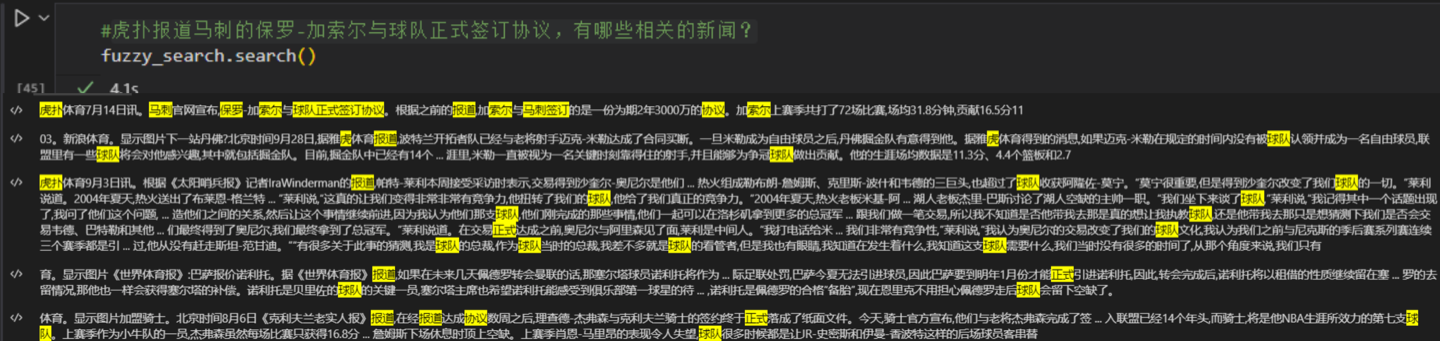
Of course, a more serious fuzzy search should further establish the correlation mapping from query features to answer text, and appropriately consider traditional keyword techniques.
Text Clustering
When category labels are not provided, our visualization tool automatically clusters the text.
This is a demonstration of clustering on news data.
Few-shot Classification Learning
- TODO
Example Code
Training Methods
During training, we used three loss components. The first is the MSE loss on OpenAI's features (I actually think L1 might be better); the second is the CSE loss, which calculates the similarity matrix for text pairs, then computes cross-entropy horizontally and vertically with the diagonal as ground truth labels; the third is the KL divergence loss, which calculates the KL divergence row-wise and column-wise between the correlation matrix P obtained from OpenAI and the current correlation matrix Q from the model.
For specific details, please refer to our report that we are currently writing. Once some quantitative experiments are completed, we will first post a Chinese version on arXiv for easier citation of our work. After adding more quantitative experiments, I will translate it into English.
BERT Model
For the BERT model, we added a fully connected layer to increase BERT's features to 1536 dimensions. We started with the Chinese CLIP model released by Dr. Shen Xiangyang's IDEA and trained for a total of 5 epochs on all data. We released the 102M small model over the weekend, and the 352M model should be released on Monday or Tuesday.
GLM Model
For the GLM model, for a sentence input, we obtain the hidden vector of each input token in GLM's last layer after tokenization, then pass this vector through a fully connected layer and input it into a BERT.
These details can be found in our report that we are currently writing.
Data
In training the Luotuo embeddings, we used 234.5K CNewSum data. After cleaning the news data, splitting it, and calling OpenAI's text-embedding-ada-002 model, we obtained 1536-dimensional data for all text pairs.
We plan to release this dataset and are currently studying the data protocols of CNewSum and OpenAI. We are preparing to apply for sharing the spreadsheets and websites for this dataset, and will release it afterward.
Additionally, applying models trained on news data to other domains (such as Xianxia web novels) may have some limitations. It's best to further incorporate corresponding domain data for additional distillation training. If you have specific needs in this area and are willing to cover the costs of data and computing power, you can contact our team. (It would be even better if you're willing to make the training results with partial additional domain data public to the community)
Sponsorship of the Luotuo Project
In addition to using remote servers purchased with community-donated funds for training Luotuo embeddings,
We also used two weeks of A100 computing power donated by Soochow Securities. We express our gratitude for this!
If you are interested in sponsoring the Luotuo project, please click on the main project or view the sponsorship form
If you are interested in sponsoring the Luotuo Project, please click on the major project or view the sponsorship form.
Personnel
For more detailed information about the personnel involved in the entire Luotuo project, please check the Luotuo project homepage
Each author is a first author, and the order is random. Li Lulu initiated the project, completed initial validation, and proposed KL divergence Loss and Hard Negative mining.
Liu Siyi completed the initial training framework and supported the subsequent model upload to the Hugging Face pipeline.
Leng Ziang completed the full training of large and small models, including data loading and loss function implementation.
Chen Qiyuan prepared the CNewSum data and performed sentence segmentation.
Huang Hongsen was responsible for crawling OpenAI Embedding data.
Chen Shunian completed several important visualizations.
Sun Ao (will) use our obtained Embeddings to complete CoT enhancement experiments.
Hu Jing collected Jay Chou's lyrics and (will) complete more quantitative experiments.
Citation
If you use our model, code, or data in your project, please cite the first article below.
Please cite the repo if you use the data or code in this repo.
@misc{alpaca,
author={Siyi Liu, Ziang Leng, Hongsen Huang, Shunian Chen, Jing Hu, Ao sun, Qiyuan Chen, Cheng Li},
title = {Luotuo Embedding: Generative Text Embedding Model distilled from OpenAI API},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/LC1332/Luotuo-Text-Embedding}},
}
@misc{alpaca,
author={Ziang Leng, Qiyuan Chen and Cheng Li},
title = {Luotuo: An Instruction-following Chinese Language model, LoRA tuning on LLaMA},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/LC1332/Luotuo-Chinese-LLM}},
}
Uncle Lu's Discussion
-
Embedding is a more academic approach. The public has discussed a lot about the language generation results of generative models, but there's relatively little discussion about Embedding.
-
However, many applications, such as BingGPT or ChatPDF, actually need Embedding models when constructing. So it's necessary to build one.
-
I estimate that this work might not receive a lot of attention, but it's indeed a very important work for the entire community, so it's worth doing. Therefore, we've invested a lot of manpower and resources into doing this Embedding work, and I'd like to express my gratitude to them here. If you think this project is indeed meaningful or has truly helped you, you can go to our Luotuo main project to give it a star.
-
However, the lyrics visualization is quite interesting. Since many of the team members are born after 1995 and 2000 (should I say everyone except me?), they complained that the songs I chose were too old, older than them. This lyrics visualization is very interesting, and I want to make a gradio later that supports uploading 20 lines of lyrics and automatically calculates and generates a graph.
-
I wasn't very satisfied with the previous NLP work visualization tools, so we rewrote them all here. The visualization was mainly implemented by Chen Shunian.
-
I've said that the Luotuo project is our assignment project, aiming to revisit various NLP tasks using new large language models. So I don't want to struggle too much time on decoder fine-tuning alone, but rather want to do various tasks.
-
If you find that this embedding doesn't work very well in your application area, but the OpenAI API does, it means we need to increase data to cover your domain. Please contact us promptly. We ultimately hope that Luotuo-BERT is a good Text Embedding that everyone can use, without having to spend effort retraining themselves.
-
For QA, theoretically, we should make a conversion function between query and answer, but I estimate a linear function should be enough here.
-
Because the community attention to this work may not be high, we might as well write an arxiv paper after completing the tests later, which would be the first arxiv paper for the entire big project.
TODO for RELEASE
- Build project page
- Release small model test code
- Release small model colab test code
- Update link on Luotuo main page after colab code release
- Replace correlation test, change data to web text-news data
- Fuzzy search
- Draw a model structure diagram
- (optional) Prepare an easier-to-use lyrics analysis script
- (optional) Release medium model
To be completed before Tuesday
- Release large model test code
- Downstream application - Search small model
- Downstream application - Clustering small model
- Downstream application - Classification small model
- Downstream application - Search large model
- Downstream application - Clustering large model
- Downstream application - Classification large model
- Translate page to English
- Release data
- Expand domain data, train a better small model
- Expand domain data, train a better large model
- Write arxiv supplementary experiments
- Clean and release training code
Report
See our in-writing report here











