
Mega-TTS 2: 突破性的零样本文本转语音技术
在人工智能和语音合成技术飞速发展的今天,一项名为Mega-TTS 2的创新技术正在引起业界的广泛关注。这项由研究人员开发的零样本文本转语音(TTS)模型,不仅能够合成高质量的语音,还能够利用任意长度的语音提示来模仿说话者的声音特征,为语音克隆和个性化语音合成开辟了新的可能。
突破性的技术创新
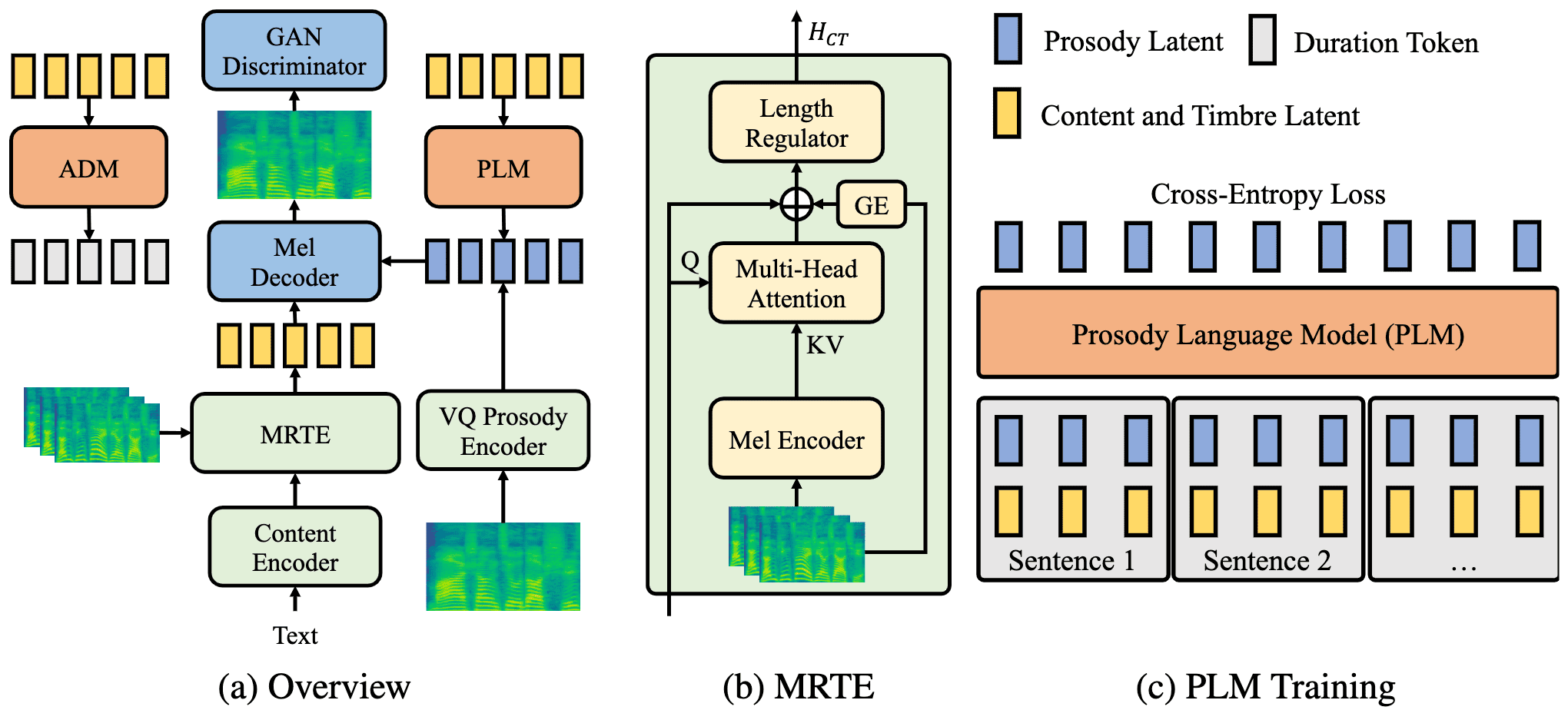
Mega-TTS 2的核心创新在于其能够处理任意长度的语音提示。传统的零样本TTS模型通常只能使用短时间(如10秒)的语音样本作为提示,这严重限制了它们在细粒度身份模仿方面的表现。而Mega-TTS 2突破了这一限制,能够从更长的语音样本中提取更丰富的声音特征信息,从而实现更加逼真和个性化的语音合成。
为了实现这一突破,研究人员设计了几个关键组件:
- 多参考音色编码器:能够从多个参考语音中提取音色信息。
- 韵律语言模型(PLM):可以处理任意长度的语音提示,学习说话者的韵律特征。
- 音素级自回归持续时间模型:引入了上下文学习能力,提高了语音节奏的自然度。
这些创新使得Mega-TTS 2不仅可以利用短语音提示合成未见说话者的语音,还能随着提供的语音样本增多而不断提升合成质量,甚至在某些情况下超越了传统的微调方法。
广泛的应用前景
Mega-TTS 2的出现为语音合成技术带来了新的可能性,其潜在的应用场景非常广泛:
- 个性化语音助手:用户可以使用自己的声音来定制虚拟助手,提供更加个性化的交互体验。
- 配音和本地化:电影、游戏和其他媒体内容可以更容易地实现多语言配音,而无需原声演员重新录制。
- 辅助交流:失声或语言障碍患者可以使用这项技术恢复"自己的声音",提高生活质量。
- 教育培训:可以创建各种声音的教学内容,增强学习体验的多样性。
- 创意内容制作:音乐家、播客创作者等可以探索新的创作方式,如虚拟合唱或多角色对话。
技术实现与开源贡献
虽然Mega-TTS 2的原始实现尚未开源,但已经有研究者开始尝试复现这项技术。GitHub上的megatts2项目就是一个非官方的实现尝试,为开发者和研究者提供了一个学习和实验的平台。
该项目的主要特点包括:
- 使用PyTorch-Lightning框架进行模型训练
- 提供了数据集准备、模型训练和推理测试的完整流程
- 计划引入更多优化,如替换HifiGAN为BigVGAN,混合中英文训练等
对于有兴趣深入研究或应用Mega-TTS 2技术的开发者,这个开源项目提供了一个很好的起点。
伦理考虑与未来展望
尽管Mega-TTS 2展现出了巨大的潜力,但我们也需要警惕其可能带来的伦理问题,如未经授权的语音克隆或制作深度伪造内容。因此,在推进这项技术的同时,建立相应的伦理准则和使用规范也变得尤为重要。
展望未来,Mega-TTS 2代表了语音合成技术的一个重要里程碑。随着进一步的研究和优化,我们可以期待看到更加自然、富有表现力的语音合成系统,这将为人机交互、内容创作和无障碍技术等领域带来革命性的变革。
总的来说,Mega-TTS 2的出现不仅推动了语音合成技术的进步,也为我们展示了人工智能在模仿和创造人类语音方面的巨大潜力。随着技术的不断发展和完善,我们有理由相信,未来的语音交互将变得更加自然、个性化和富有表现力。
参考资料
- Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
- Mega-TTS 2 项目演示页面
- GitHub - LSimon95/megatts2: Unofficial implementation of Megatts2
通过Mega-TTS 2这项突破性技术,我们可以看到语音合成领域正在迈向一个更加智能和个性化的未来。无论是对研究人员、开发者还是普通用户来说,这都预示着语音交互体验的重大变革即将到来。










