
MegaTTS 2: 零样本语音合成的重大突破
MegaTTS 2是一个能够利用任意长度语音提示进行零样本语音合成的最新模型,由浙江大学和字节跳动联合开发。该模型在零样本语音合成领域取得了重大突破,能够生成高质量、保留说话人身份特征的语音,且支持任意长度的语音提示。
主要特点
- 支持任意长度的语音提示
- 能够生成保留说话人身份特征的高质量语音
- 支持跨语言的语音合成
- 实现了可控的韵律迁移
相关资源
-
论文: Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
-
项目主页: MegaTTS 2 Demo
-
非官方开源实现: GitHub - LSimon95/megatts2
-
论文解读视频: Mega-TTS 2: Revolutionizing Zero-Shot Text-to-Speech with Longer Prompts!
技术细节
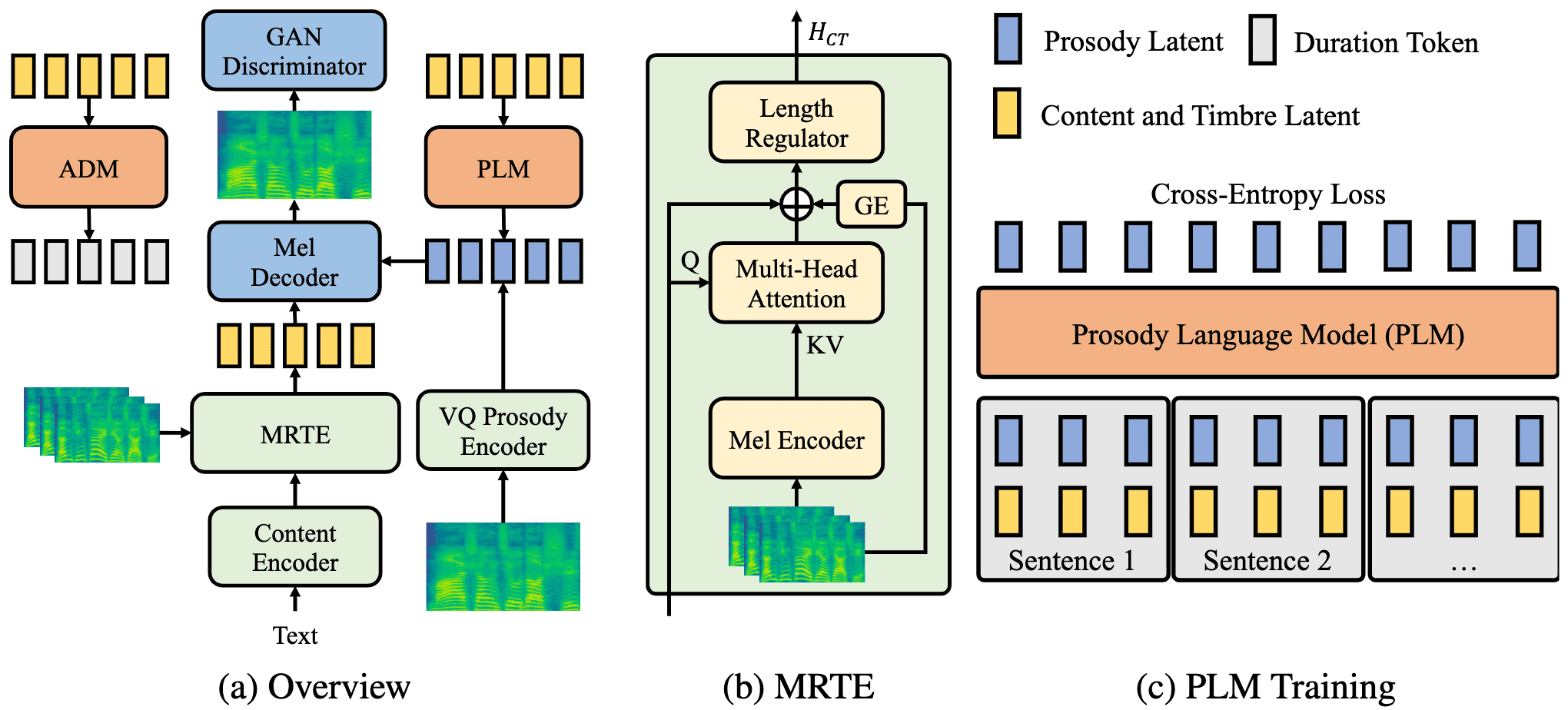
MegaTTS 2的核心创新包括:
- 多参考音色编码器:从多个参考语音中提取音色信息
- 韵律潜在语言模型:处理任意长度的语音提示
- 音素级自回归持续时间模型:引入上下文学习能力
使用教程
非官方开源实现提供了详细的使用教程,包括:
- 安装Montreal Forced Aligner(MFA)
- 准备数据集
- 训练模型
- 推理测试
详细步骤请参考 GitHub仓库的README。
未来展望
MegaTTS 2为零样本语音合成开辟了新的可能性。未来可能的改进方向包括:
- 使用BigVGAN替换HiFi-GAN提升音质
- 混合训练中英文数据集
- 扩大训练数据规模至1000小时语音
- 开发Web用户界面
MegaTTS 2是语音合成领域的一个重要里程碑。随着技术的不断发展,我们可以期待更加自然、富有表现力的语音合成系统的诞生。
参考资料
欢迎对MegaTTS 2感兴趣的读者深入探索这些资源,共同推动语音合成技术的发展!










